Kafka 重度依赖底层操作系统提供的 PageCache 功能
简介
Kafka 重度依赖底层操作系统提供的 PageCache 功能。
Kafka为什么不自己管理缓存,而非要用page cache?原因有如下三点
- JVM中一切皆对象,数据的对象存储会带来所谓object overhead,浪费空间;
- 如果由JVM来管理缓存,会受到GC的影响,并且过大的堆也会拖累GC的效率,降低吞吐量;
- 一旦程序崩溃,自己管理的缓存数据会全部丢失。
Kafka三大件(broker、producer、consumer)与page cache的关系可以用下面的简图来表示。
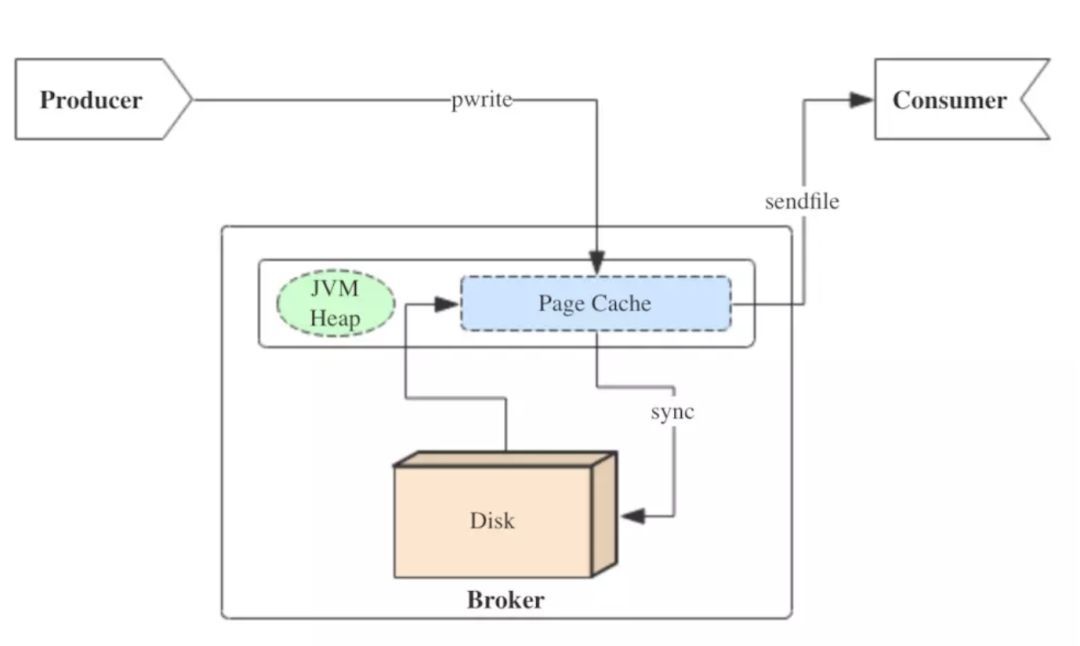
当上层有写操作时,操作系统只是将数据写入PageCache,同时标记Page属性为Dirty。当读操作发生时,先从PageCache中查找,如果发生缺页才进行磁盘调度,最终返回需要的数据。
来看美团详细版的图
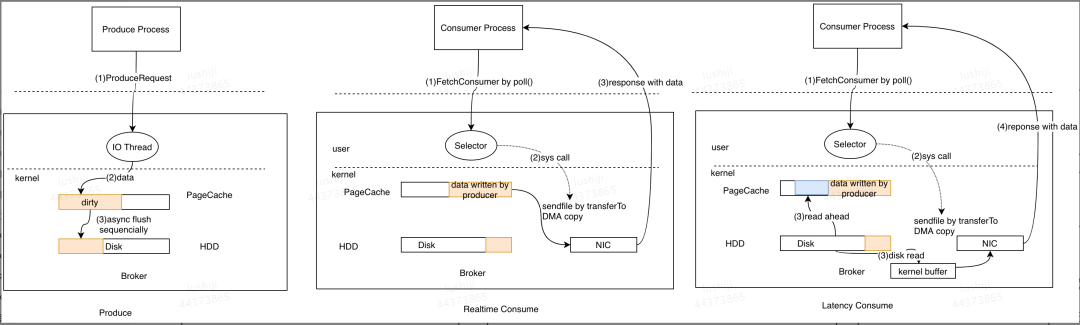
对于Produce请求:Server端的I/O线程统一将请求中的数据写入到操作系统的PageCache后立即返回,当消息条数到达一定阈值后,Kafka应用本身或操作系统内核会触发强制刷盘操作(如左侧流程图所示)。
对于Consume请求:主要利用了操作系统的ZeroCopy机制,当Kafka Broker接收到读数据请求时,会向操作系统发送sendfile系统调用,操作系统接收后,首先试图从PageCache中获取数据(如中间流程图所示);如果数据不存在,会触发缺页异常中断将数据从磁盘读入到临时缓冲区中(如右侧流程图所示),随后将数据拷贝到网卡缓冲区中等待后续的TCP传输(数据拷贝利用DMA操作减少拷贝次数和上下文切换)。
由此我们可以得出重要的结论:如果Kafka producer的生产速率与consumer的消费速率相差不大,那么就能几乎只靠对broker page cache的读写完成整个生产-消费过程,磁盘访问非常少。并且Kafka持久化消息到各个topic的partition文件时,是只追加的顺序写,充分利用了磁盘顺序访问快的特性,效率高。
参数
对于单纯运行Kafka的集群而言,首先要注意的就是为Kafka设置合适(不那么大)的JVM堆大小。从上面的分析可知,Kafka的性能与堆内存关系并不大,而对page cache需求巨大。根据经验值,为Kafka分配5~8GB的堆内存就已经足足够用了,将剩下的系统内存都作为page cache空间,可以最大化I/O效率。
另一个需要特别注意的问题是lagging consumer,即那些消费速率慢、明显落后的consumer。它们要读取的数据有较大概率不在broker page cache中,因此会增加很多不必要的读盘操作。比这更坏的是,lagging consumer读取的“冷”数据仍然会进入page cache,污染了多数正常consumer要读取的“热”数据,连带着正常consumer的性能变差。
在Linux操作系统中,写操作是异步的,即写操作返回的时候数据并没有真正写到磁盘上,而是先写到了系统cache里,随后由pdflush内核线程将系统中的脏页写到磁盘上
- /proc/sys/vm/dirty_writeback_centisecs:flush检查的周期。单位为0.01秒,默认值500,即5秒。每次检查都会按照以下三个参数控制的逻辑来处理。
- /proc/sys/vm/dirty_expire_centisecs:如果page cache中的页被标记为dirty的时间超过了这个值,就会被直接刷到磁盘。单位为0.01秒。默认值3000,即半分钟。
- /proc/sys/vm/dirty_background_ratio:如果dirty page的总大小占空闲内存量的比例超过了该值,就会在后台调度pdflush内核线程异步写磁盘,不会阻塞当前的write()操作。默认值为10%。
- /proc/sys/vm/dirty_ratio:如果dirty page的总大小占总内存量的比例超过了该值,就会阻塞所有进程的write()操作,并且强制每个进程将自己的文件写入磁盘。默认值为20%。
参考链接