发现测试集群HDFS报丢失块的告警。 对块进行修复
前言
发现测试集群HDFS报丢失块的告警。
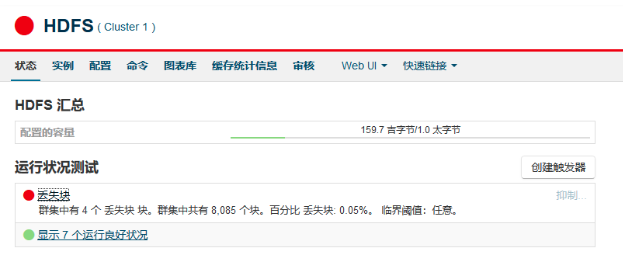
如果块损坏过多,超过设置的百分比,NameNode 会进入安全模式。需要退出安全模式处理
处理
解决方法:
- 如果文件不重要,可以直接删除此文件;或删除后重新复制一份到集群中
- 如果不能删除,需要从上面命令中找到发生在哪台机器上,然后到此机器上查看日志。
先确认集群有没有datanode宕机
1 | sudo -u hdfs hdfs dfsadmin -report |
查看丢失块的信息
1 | # 需要hdfs权限权限操作。如果没有hdfs 账号,则在命令前加 sudo -u hdfs ,以hdfs权限运行该命令 |

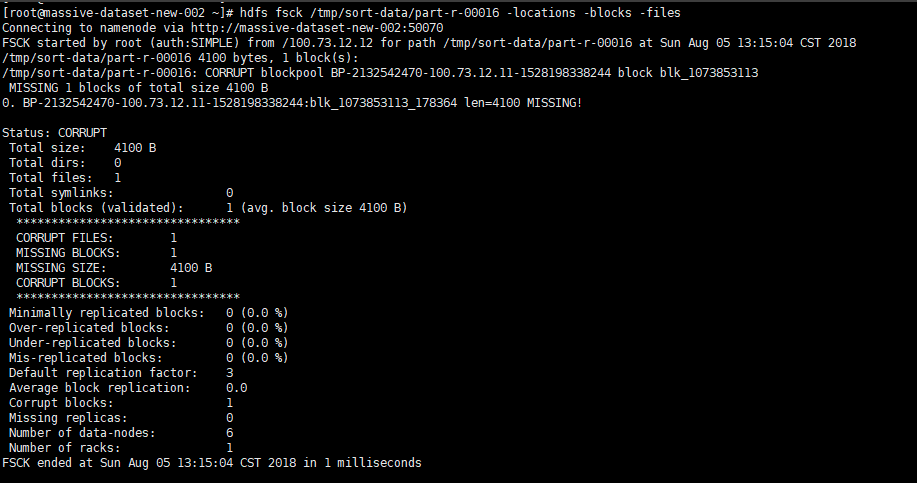
当然,这只是数据允许丢失的情况下可以使用的一种简单粗暴的方法hdfs fsck / -delete, 是删除所有损坏的块的数据文件,会导致数据彻底丢失
生产上还是无法使用这种直接删数据的方法的
那么生产上应该怎么处理这种情况呢?
- 首先
hdfs fsck -list-corruptfileblocks找到数据块的位置 hdfs debug recoverLease [-path <path>] [-retries <num-retries>]用这个命令恢复上面路径丢失的数据块,最后一个参数是重试次数
自动修复
hdfs当然会自动修复损坏的数据块,当数据块损坏后,DN节点执⾏directoryscan(datanode进行内存和磁盘数据集块校验)操作之前,都不会发现损坏;也就是directoryscan操作校验是间隔6h
dfs.datanode.directoryscan.interval : 21600在DN向NN进⾏blockreport前,都不会恢复数据块;也就是blockreport操作是间隔6h
dfs.blockreport.intervalMsec : 21600000
最终当NN收到blockreport才会进⾏恢复操作
生产中倾向于使用手动修复的方法去修复损坏的数据块。
具体的实操请转移这里阅读生产HDFS Block损坏恢复最佳实践(含思考题),注意地方:
- 删除块和meta文件之后要重启HDFS,模拟损坏效果,不重启的话直接fsck检查看不到块损坏
HDFS block丢失过多进入安全模式(Safe mode)的解决方法
前面介绍的是简单的块损坏。 后面遇到一次丢失块比例高达 13% 的测试环境。
由于系统断电,内存不足等原因导致 DN 丢失超过设置的丢失百分比,系统自动进入安全模式。
解决办法就是把宕机 DN 重启恢复回来,然后观察是否能够恢复。
不然只能退出安全模式。清理损坏的块。注意: 这种方式会出现数据丢失,损坏的block会被删掉 请慎重
退出安全模式操作如下
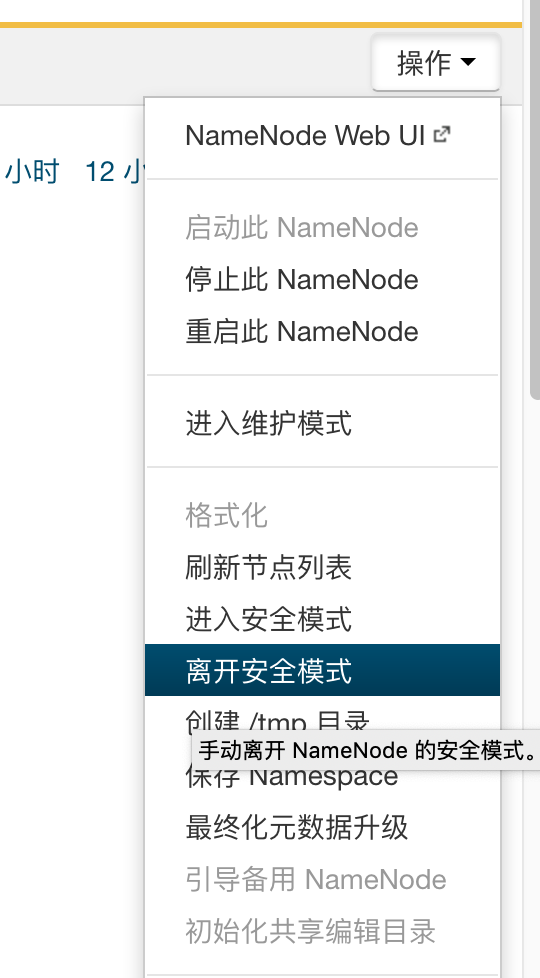
离开安全模式后使用hdfs dfsadmin -safemode get查看,Safe mode is OFF 为安全模式关闭,Safe mode is ON为安全模式开启
如果无法离开安全模式,那就强制离开hdfs dfsadmin -safemode forceExit
执行健康检查,删除损坏掉的block hdfs fsck / -delete
参考链接