使用 Spark 将数据以 bulkload 的方式写入 HBase
前言
因历史遗留问题,有之前的开发写了 mapreduce 版的 bulkload 代码。
数据量太大。要跑3天才能跑完。 因此想将其改成 spark 的来试试。
之前没写过 spark 代码,都是现学现卖。同时记录自己所踩的坑。
为何要 BulkLoad 导入?
在初始化 HBase 表时,有时候需要大量导入初始数据。 最能想到的方式是一条一条数据写入。
可是这样的话,HBase会block写入,频繁进行flush,split,compact等大量IO操作,
并对HBase节点的稳定性造成一定的影响,GC时间过长,响应变慢,导致节点超时退出,并引起一系列连锁反应。因此在大数据量写入时效率低下。
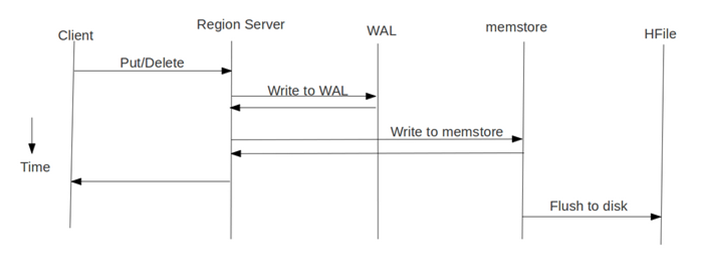
使用 Bulk Load 方式由于利用了 HBase 的数据信息是按照特定格式存储在 HDFS 里的这一特性。
直接在 HDFS 中生成持久化的 HFile 数据格式文件,然后完成巨量数据快速入库的操作。
配合 MapReduce 完成这样的操作,不占用 Region 资源,不会产生巨量的写入 I/O。所以需要较少的 CPU 和网络资源。
概括来说:BulkLoad 方式是绕过了 Write to WAL,Write to MemStore及Flush to disk的过程,减少了对集群资源的消耗,适合大批量数据导入。
MapReduce 版本
按照HBase存储数据按照HFile格式存储在HDFS的原理,使用MapReduce直接生成HFile格式的数据文件,然后在通过RegionServer将HFile数据文件移动到相应的Region上去。
将数据源准备好,上传到HDFS进行存储。我这里的数据来源是 Hive 表。查看原同事写的 MapReduce 版的是传入 Hive 表的路径
HFile文件的生成,可以使用MapReduce来进行实现,然后在程序中读取HDFS上的数据源,进行自定义封装,组装RowKey。
然后将封装后的数据在回写到HDFS上,以HFile的形式存储到HDFS指定的目录中。
大家可以参考哥不是小萝莉的博客。HBase BulkLoad批量写入数据实战
还有过往记忆的博客。通过BulkLoad快速将海量数据导入到HBase
两篇博客都写的挺好的。
Spark 版本
在 Spark 上通过 BulkLoad 快速将海量数据导入到 HBase
批量导数据到 HBase 又可以分为两种:
- 生成 HFiles,然后批量导数据
- 直接将数据批量导入到HBase中
具体代码可以参看过往记忆的博客。在Spark上通过BulkLoad快速将海量数据导入到HBase
我这里使用的是第一种方式写的代码。 把两种方式都记录下来是下次可以尝试第二种方式实现。
1. 批量将 HFiles 导入 HBase
现在我们来介绍如何批量将数据写入到HBase中,主要分为两步:
- 先生成 HFiles
- 使用 org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles 将事先生成 HFile 导入到 HBase 中。
2. 直接 BulkLoad 数据到 HBase
这种方法不需要事先在HDFS上生成Hfiles,而是直接将数据批量导入到HBase中。
遇到的问题
1. 路径没有权限
保存 HFiles 的路径没有权限写入。把路径权限改成777,或者用所属账号提交运行,又或者改成自己能写入的路径。
2. doBulkLoad 卡着
成功在 HDFS 上生成了 HFiles 文件,但是在 doBulkLoad 过程卡着不动,一度以为是资源问题,可是把我数据量缩小到只有3条数据都跑不动。
不应该是资源问题。后面怀疑是不是 HFiles 文件不符合规范导致卡着不动。
尝试直接使用 bulkload 命令可以直接导入数据 hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles /tmp/pres person
说明生成的 HFiles 是可行的。同事说可能是路径权限还是不够,让我将其路径递归设置为 777 。
再次运行代码到卡着不动时,手动执行递归修改权限命令 hadoop fs -chmod -R 777 /tmp/pres 。程序成功运行完成,并且 HBase 表可以查到数据了。
这里造成的原因不清楚,不知道是不是自己集群做了什么设置。
3. 临时目录存在
HFiles 生成的目录应该要求事先不存在的,如果事先存在,应删除。
1 | val fs:FileSystem = FileSystem.get(hdfsCf) |
4. key 有序
这里真的是踩了大坑,大坑啊。 最先谷歌出来的博客说是 rowkey 有序即可。
但是我的代码明明已经对其排序了。sortByKey 后还是报错。

后面对比了报错的原因才发现,不只是 rowkey 有序,cf、qualifer 也要有序。
5. 超过 32 个 HFiles
java.io.IOException: Trying to load more than 32 hfiles to one family of one region
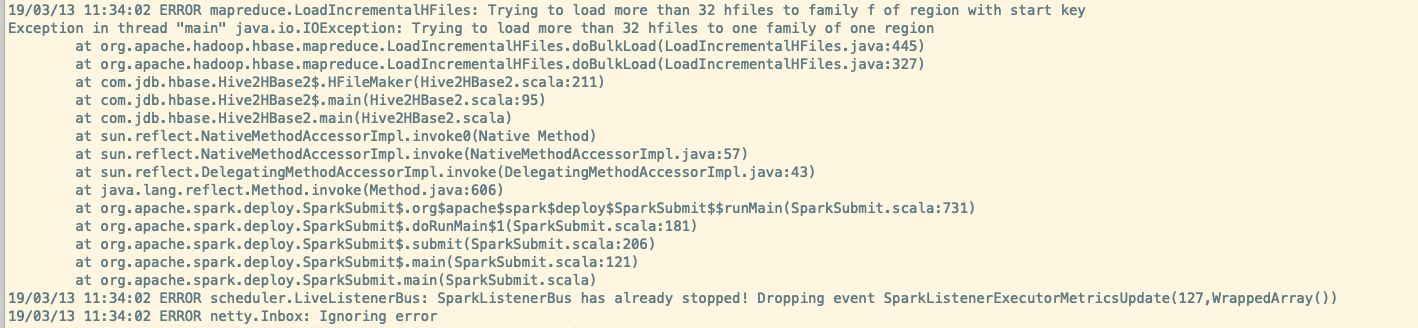
doBulkLoad 超过了 32 个 HFiles。
HBaseConfiguration 设置参数。 两种方式都行
1 | val conf = HBaseConfiguration.create() |
同时在 saveAsNewAPIHadoopFile 时要使用 conf
1 | result.saveAsNewAPIHadoopFile(tmpHdfs, classOf[ImmutableBytesWritable], classOf[KeyValue], classOf[HFileOutputFormat2], conf) |
如果在直接使用 bulkload 命令时也报这个错误的话,给命令加个参数 -Dhbase.mapreduce.bulkload.max.hfiles.perRegion.perFamily=1024
hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles -Dhbase.mapreduce.bulkload.max.hfiles.perRegion.perFamily=1024 /tmp/pres person
总结
真不容易。各种踩坑,各种填坑才完成的。
主要参考来自 过往的记忆的两篇文章,和哥不是萝莉的文章。资料1 、资料2、资料3、资料5
Fayson 大神的 bulkload 好像比较高级。表示没看懂,有兴趣的大佬可以自己观摩。资料4
参考链接