Apache HBase 快照机制。
什么是快照
快照是一组元数据信息,允许管理员返回到表的先前状态。
快照不是表的副本; 它只是一个文件名列表,不会复制数据。
完整快照还原意味着您将返回到先前的“表状态”,即恢复以前的数据,从而丢失自快照以来所做的任何更改。
操作
- 拍摄快照:此操作尝试在指定的表上拍摄快照。如果区域在平衡,拆分或合并期间移动,则操作可能会失败。
- 克隆快照:此操作使用相同的模式创建新表,并在指定的快照中显示相同的数据。此操作的结果是一个新的全功能表,可以在不影响原始表或快照的情况下进行修改。
- 还原快照:此操作将表架构和数据恢复为快照状态。(注意:此操作会丢弃自拍摄快照以来所做的任何更改。)
- 删除快照:此操作从系统中删除快照,释放非共享磁盘空间,而不会影响任何克隆或其他快照。
- 导出快照:此操作将快照数据和元数据复制到另一个群集。该操作仅涉及HDFS,因此与 HMaster 或 RS 没有交互,所以 HBase 群集可以处于停止状态。
零拷贝快照,还原,克隆
快照和 CopyTable / ExportTable 之间的主要区别在于快照操作仅写入元数据。没有涉及大量数据副本。
HBase的主要设计原则之一是,一旦文件被写入,它将永远不会被修改。拥有不可变文件意味着快照只跟踪快照操作时使用的文件,并且在压缩期间,快照负责通知系统不应删除该文件,而应将其归档。
同样的原则适用于克隆或还原操作。由于文件是不可变的,因此创建一个新表,只使用快照引用的文件的“链接”。
导出快照是唯一需要数据副本的操作,因为其他群集没有数据文件。
导出快照 vs 复制/导出表
除了复制/导出作业与快照之间提供的更好的一致性保证之外,
导出快照和复制/导出表之间的主要区别在于 ExportSnapshot 在HDFS级别运行。这意味着主服务器和区域服务器不参与此操作。
因此,在扫描过程中创建的对象数量不会创建不必要的数据高速缓存,不会触发其他GC暂停。
对HBase集群的性能影响源于 DataNode 所经历的额外网络和磁盘工作负载。
HBase Shell
通过检查 hbase-site.xml 文件中 hbase.snapshot.enabled 中的属性是否设置为true,确认已启用快照支持。
1 | # 要获取指定表的快照,请使用该snapshot命令。(不执行文件复制) |
原理
HBase 数据文件一旦落到磁盘之后就不再允许更新删除等原地修改操作,如果想更新删除的话可以追加写入新文件。
(HBase中根本没有更新接口,删除命令也是追加写入)
利用 HBase 已经落盘的文件不会更改的特点。只需要对快照表对应的所有 HFile 文件创建好指针即可。
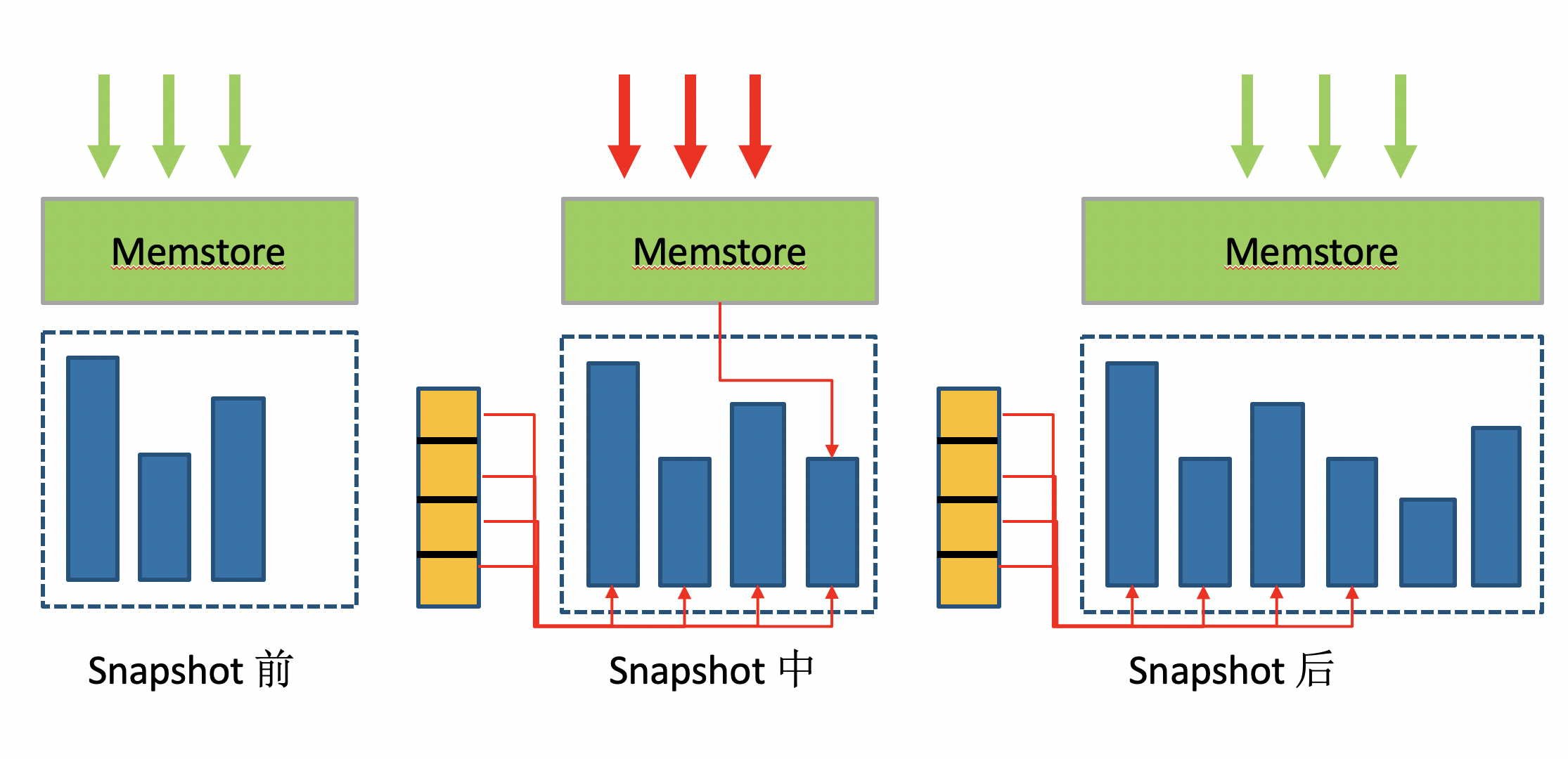
Snapshot 的流程分为4个步骤
对该表添加全局锁,不允许任何数据的写入、更新和删除
将 memstore 中的数据 flush 到 HFile 文件中 (可选)
为该表涉及的各个 region 中所有 HFile 文件创建引用指针,并记录到 snapshot manifest 文件中
HMaster 将所有的 region 的 snapshot 文件进行汇总形成总 snapshot manifest 文件.
1
snapshot 'mytable', 'snapshot123', {SKIP_FLUSH=true}
可以选择是否跳过 flush
两阶段提交
关于两阶段提交。大家可以看看这篇博文分布式基础,啥是两阶段提交?
HBase 采用两阶段提交的方式来保证 Snapshot 的原子性,要么成功,要么失败。
两阶段提交分为 prepare 阶段和 commit 阶段。
prepare 阶段:HMaster 在 ZK 的”/hbase/online-snapshot/acquired”下创建一个’acquired-snapshotname’节点,并在此节点上写入snapshot相关信息(snapshot表信息)。
所有regionserver监测到这个节点之后,根据 acquired-snapshotname 节点携带的 snapshot 表信息查看当前 RS 上是否存在目标表,如果不存在,就忽略该命令。
如果存在,遍历目标表中的所有 region,分别针对每个 region 执行 snapshot 操作,注意此处 snapshot 操作的结果并没有写入最终文件夹,而是写入临时文件夹。
RS 执行完成之后会在 acquired-snapshotname 节点下新建一个子节点 acquired-snapshotname/nodex,表示 nodex 节点完成了该 RS 上所有相关 region 的 snapshot 准备工作。commit 阶段:一旦所有 RS 都完成了 snapshot 的 prepared 工作,即都在 /hbase/online-snapshot/acquired/acquired-snapshotname 节点下新建了对应子节点,
HMaster 就认为 snapshot 的准备工作完全完成。HMaster 会新建一个新的节点 /hbase/online-snapshot/reached/reached-snapshotname,表示发送一个 commit 命令给参与的 RS。
所有 RS 监测到 reached-snapshotname 节点之后,执行snapshot commit操作,commit 操作非常简单,只需要将 prepare 阶段生成的结果从临时文件夹移动到最终文件夹即可。
执行完成之后在 reached-snapshotname 节点下新建子节点 reached-snapshotname/nodex,表示节点nodex完成snapshot工作。
如果所有参与的 regionserver 都在 /reached-snapshotname 下创建的子节点,则 HMaster 确认快照创建已经成功。如果一定时间内,reached-snapshotname 下的子节点没有满足条件或者 prepare 阶段中
/acquired-snapshot 下的子节点不满足条件,则会进入第3个 abort 阶段
- abort阶段:HMaster 会认为快照创建超时,进行回滚操作。此时 HMaster 会在ZK上创建 /hbase/online-snapshot/abort/abort-snapshotname 节点,所有 RS 监听到会清理临时 snapshot 在临时文件夹中的生成结果。
核心实现
Snapshot 两个原子性操作
- 每个 region 真正实现 snapshot
- HMaster 又是如何汇总所有 region snapshot 结果
region 如何实现 snapshot ?
在基本原理一节提到过 snapshot 不会真正拷贝数据,而是使用指针引用的方式创建一系列元数据。
那元数据具体是什么样的元数据呢?实际上snapshot的整个流程基本如下:
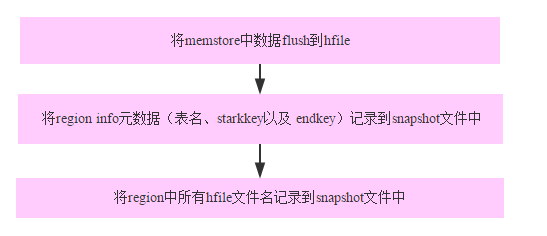
分别对应 Debug 日志中如下片段:
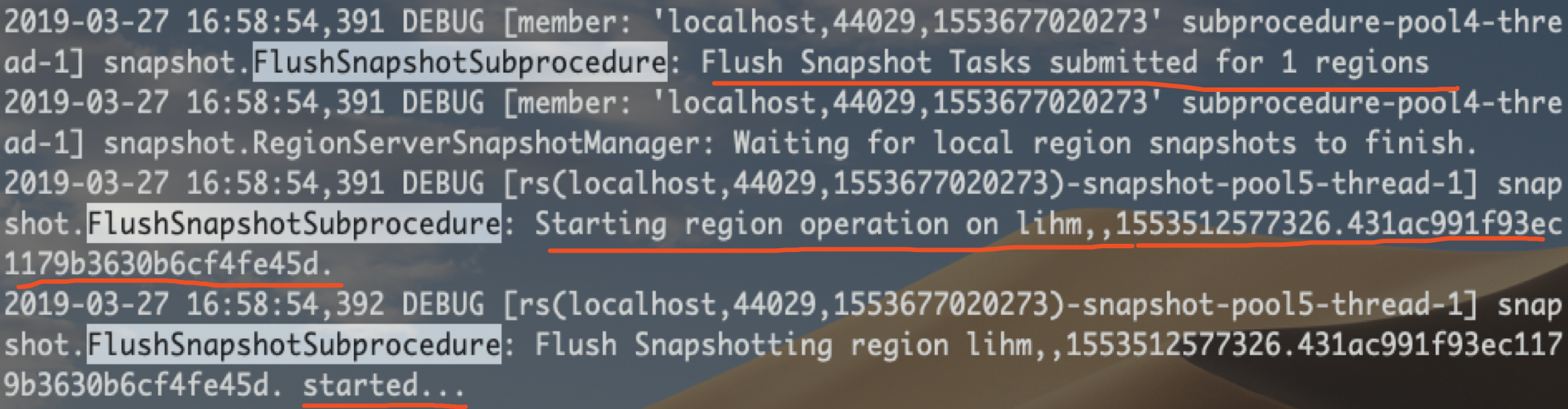
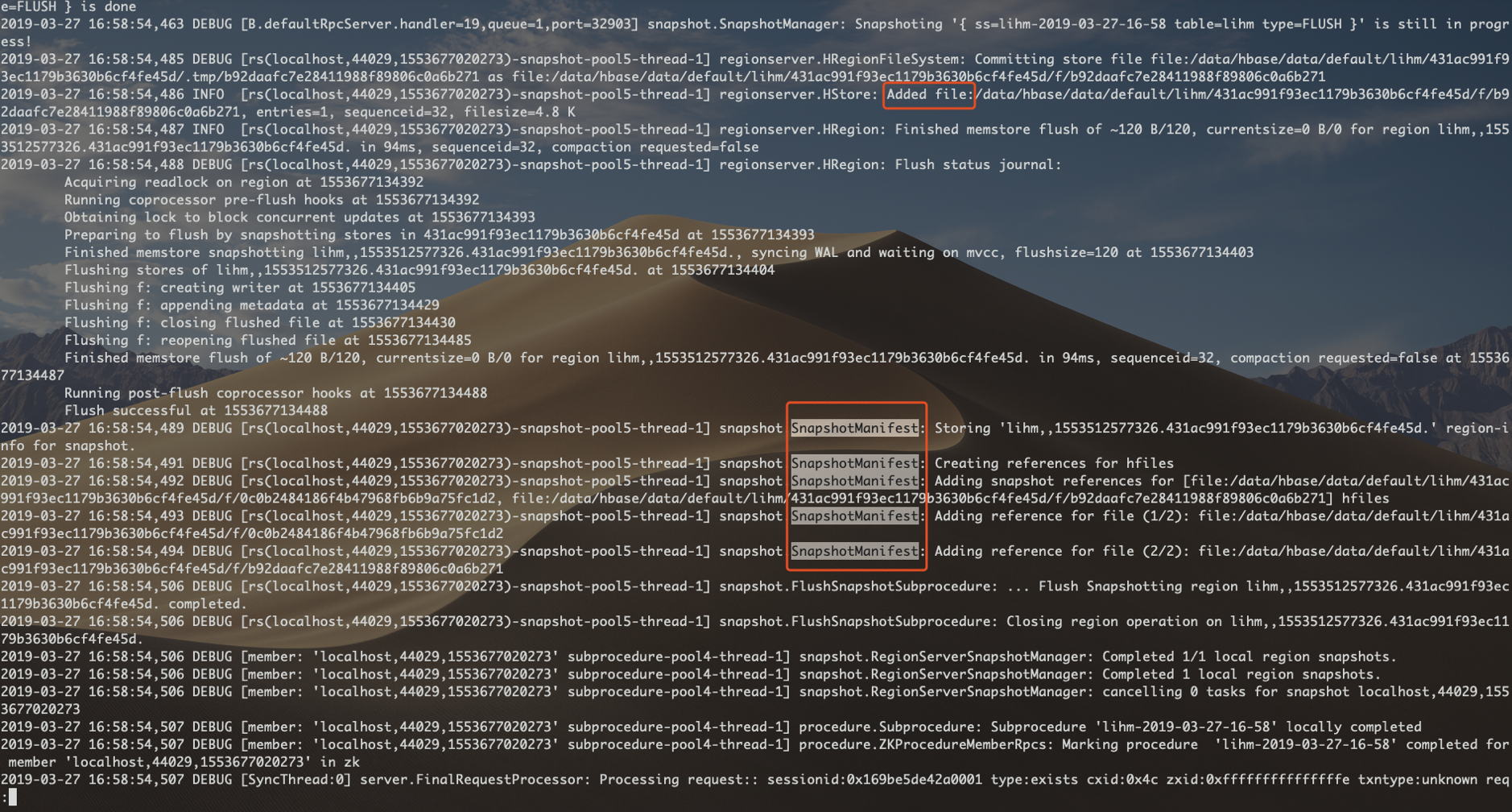
注意:region 生成的 snapshot manifest 文件是临时文件,生成目录在 /hbase/.hbase-snapshot/.tmp 下,一般因为 snapshot 过程特别快,
所以很难看到单个 region 生成的 snapshot 文件。
HMaster 如何汇总所有 region snapshot 的结果?
HMaster 会在所有 region 完成 snapshot 之后执行一个汇总操作(consolidate),将所有 region snapshot manifest 汇总成一个单独 manifest。
汇总后的 snapshot 文件是可以在 HDFS 目录下看到的,路径为: /hbase/.hbase-snapshot/{snapshotname}/data.manifest。(snapshotname 为快照名字)
注意,snapshot 目录下有3个文件,如图所示:
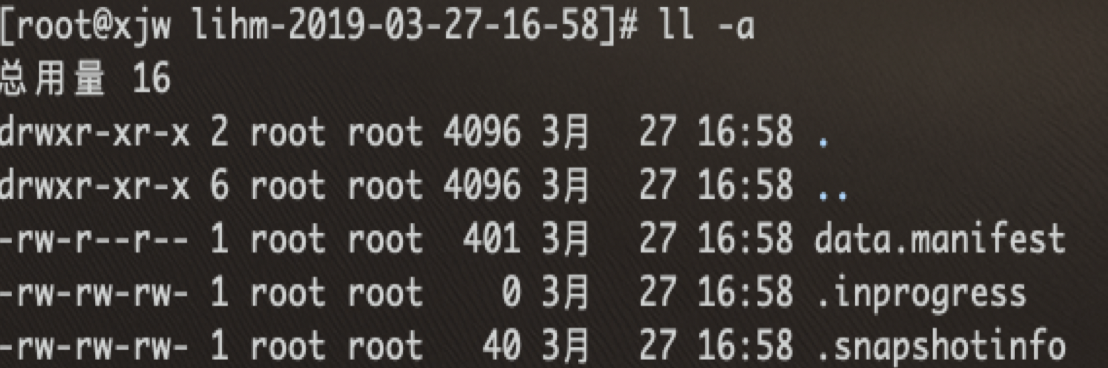
其中 .snapshotinfo 为 snapshot 基本信息,包含待 snapshot 的表名称以及 snapshot 名;
data.manifest 为 snapshot 执行后生成的元数据信息,
即 snapshot 结果信息。可以使用 hadoop dfs -cat /hbase/.hbase-snapshot/{snapshotname}/data.manifest 查看
快照的使用示例
1. 更改表名
因为 HBase 中没有 Rename 命令, 所以更改表名比较复杂。重命名主要通过 HBase 的快照功能。
1 | # 停止表继续插入 |
2. 恢复表
从用户/应用程序错误中恢复表。
1 | # 制作快照 |
3. 表迁移
HBase Snapshot 可以在对 RS 影响很小的情况下创建快照、将快照复制到另一个集群。
由于导出快照在 HDFS 级别运行,因此不会像 CopyTable 那样减慢主 HBase 群集的速度。
1 | # 在源表上创建快照。 |
参考链接