记录一些名词的理解和解释
前言
记录专有名词的解释。方便自己回看
并发与并行
- 并发: 多任务下,在同一时间段内同时发生。
- 并行: 多任务下,在同一时间点上同时发生。
并发会多个任务之间是互相抢占资源的,而并行不会。
知乎上高赞例子:
- 你吃饭吃到一半,电话来了,你一直到吃完了以后才去接,这就说明你不支持并发也不支持并行。
- 你吃饭吃到一半,电话来了,你停了下来接了电话,接完后继续吃饭,这说明你支持并发。
- 你吃饭吃到一半,电话来了,你一边打电话一边吃饭,这说明你支持并行。
只有在多CPU的情况中,才会发生并行。否则,看似同时发生的事情,其实都是并发执行的。
分布式、高并发、多线程
分布式是为了解决单个物理服务器容量和性能瓶颈问题而采用的优化手段。
- 水平扩展: 当一台机器扛不住流量时,就通过添加机器的方式,将流量平分到所有服务器上,
所有机器都可以提供相当的服务;
- 垂直拆分: 前端有多种查询需求时,一台机器扛不住,
可以将不同的需求分发到不同的机器上,比如A机器处理余票查询的请求,B机器处理支付的请求。
高并发在解决的问题上会集中一些,其反应的是同时有多少量
高并发可以通过分布式技术去解决,将并发流量分到不同的物理服务器上。
但除此之外,还可以有很多其他优化手段:比如使用缓存系统,将所有的,静态内容放到CDN等;
还可以使用多线程技术将一台服务器的服务能力最大化。
多线程是指从软件或者硬件上实现多个线程并发执行的技术,
它更多的是解决CPU调度多个进程的问题,从而让这些进程看上去是同时执行(实际是交替运行的)。
这几个概念中,多线程解决的问题是最明确的,手段也是比较单一的,
基本上遇到的最大问题就是线程安全。
总结一下:
● 分布式是从物理资源的角度去将不同的机器组成一个整体对外服务,技术范围非常广且难度非常大,有了这个基础,高并发、高吞吐等系统很容易构建;
● 高并发是从业务角度去描述系统的能力,实现高并发的手段可以采用分布式,也可以采用诸如缓存、CDN等,当然也包括多线程;
● 多线程则聚焦于如何使用编程语言将CPU调度能力最大化。
分布式、集群
分布式(distributed)是指在多台不同的服务器中部署不同的服务模块,通过远程调用协同工作,对外提供服务。
集群(cluster)是指在多台不同的服务器中部署相同应用或服务模块,构成一个集群,通过负载均衡设备对外提供服务。
在这里感觉分布式就是上章节的垂直拆分
集群就是上章节的水平扩展
两阶段加锁(2PL)协议、两阶段提交(2PC)协议
2PL: 两阶段加锁协议: 主要用于单机事务中的一致性与隔离性。
2PC: 两阶段提交协议: 主要用于分布式事务。
QPS、TPS
QPS: Queries Per Second意思是“每秒查询率”,是一台服务器每秒能够相应的查询次数,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准。
TPS: 是 TransactionsPerSecond 的缩写,也就是事务数/秒。它是软件测试结果的测量单位。一个事务是指一个客户机向服务器发送请求然后服务器做出反应的过程。客户机在发送请时开始计时,收到服务器响应后结束计时,以此来计算使用的时间和完成的事务个数。
数据仓库
Data Warehouse: 简称DW,中文名数据仓库,是商业智能(BI)中的核心部分。主要是将不同数据源的数据整合到一起,通过多维分析等方式为企业提供决策支持和报表生成。
那么它与我们熟悉的传统关系型数据库有什么不同呢?
简而言之,用途不同。数据库面向事务,而数据仓库面向分析。数据库一般存储在线的业务数据,
需要对上层业务的改变做出实时反应,涉及到增删查改等操作,所以需要遵循三大范式,需要ACID。
而数据仓库中存储的则主要是历史数据,主要目的是为企业决策提供支持,所以可能存在大量数据冗余,
但利于多个维度查询,为决策者提供更多观察视角。
在传统BI领域中,数据仓库的数据同样存储在Oracle、MySQL等数据库中,
而在大数据领域中最常用的数据仓库就是Apache Hive,Hive也是Apache Kylin默认的数据源。
OLAP、OLTP
OLAP:(Online Analytical Process),联机分析处理,以多维度的方式分析数据,一般带有主观的查询需求,多应用在数据仓库。
OLTP:(Online Transaction Process),联机事务处理,侧重于数据库的增删查改等常用业务操作。
at most once、at least once、exactly once
At most once 的消息传输机制是每条消息传输零次或者一次,即消息可能会丢失
A t least once 意味着每条消息会进行多次传输尝试,至少一次成功,即消息传输可能重复但不会丢失
Exactly once 的消息传输机制是每条消息有且只有一次,即消息传输既不会丢失也不会重复
CPU 用户态、内核态
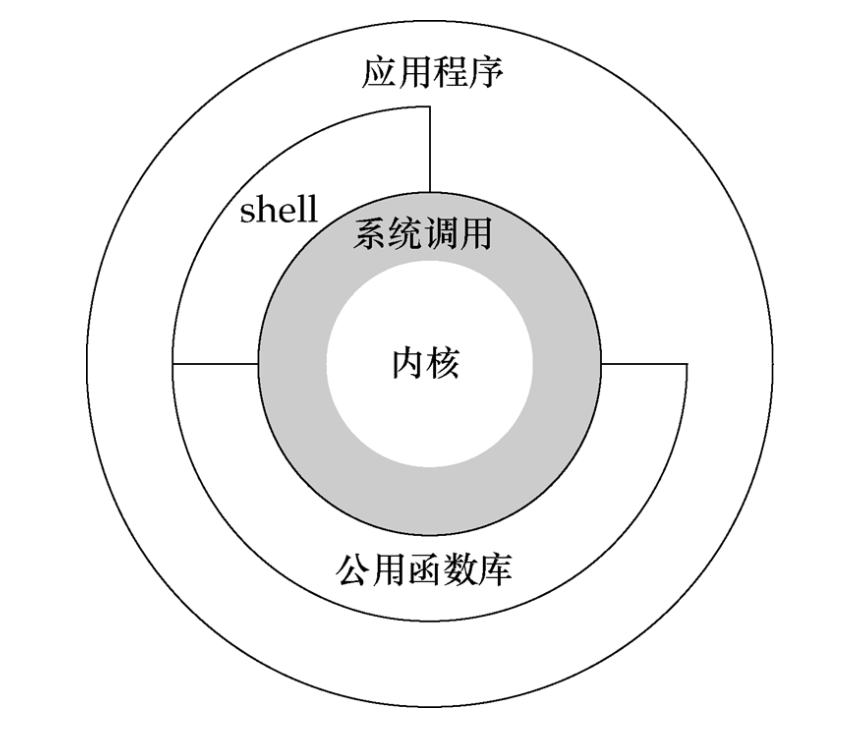
系统中既有操作系统的程序,也有普通用户程序。OS 的核心是内核,可以访问底层硬件设备,为了保证用户进程不能直接操作内核从而保证内核的安全,为了安全性和稳定性,需要切换到内核状态来访问底层硬件设备,这就是内核态。
内核态: 控制计算机的硬件资源,并提供上层应用程序运行的环境,内核态可以使用计算机所有的硬件资源
用户态: 上层应用程序的活动空间,应用程序的执行必须依托于内核提供的资源
系统调用: 为了使上层应用能够访问到这些资源,内核为上层应用提供访问的接口
从用户态到内核态的切换,一般存在以下三种情况
- 系统调用: 用户态进程通过系统调用申请使用操作系统提供的服务程序完成工作,比如fork()实际上就是执行了一个创建新进程的系统调用。而系统调用的机制其核心还是使用了操作系统为用户特别开放的一个中断来实现,例如Linux的int 80h中断
- 异常事件: 当CPU正在执行运行在用户态的程序时,突然发生某些预先不可知的异常事件,这个时候就会触发从当前用户态执行的进程转向内核态执行相关的异常事件,典型的如缺页异常
- 外围设备的中断: 当外围设备完成用户的请求操作后,会像CPU发出中断信号,此时,CPU就会暂停执行下一条即将要执行的指令,转而去执行中断信号对应的处理程序,如果先前执行的指令是在用户态下,则自然就发生从用户态到内核态的转换
其中系统调用可以认为是用户进程主动发起的,异常和外围设备中断则是被动的。所以系统调用的本质也是中断,相对于外围设备的硬中断,这种中断称为软中断
- 计算机系统中有“操作系统程序”和“普通用户程序”。
- 操作系统程序执行就是在“内核态”下执行的。
- 普通用户程序就是在“用户态”下执行的。
- 内核态可以使用所有的硬件资源,用户态不能直接使用系统资源
- 为了安全和稳定性,操作系统程序是不能随便访问的
- 引起“用户态切换到内核态”的本质就是“CPU实行了一次中断相应”
用户空间、内核空间
用户空间就是用户进程所在的内存区域,相对的,系统空间就是操作系统占据的内存区域。用户进程和系统进程的所有数据都在内存中
是谁来划分内存空间的呢?在电脑开机之前,内存就是一块原始的物理内存。什么也没有。开机加电,系统启动后,就对物理内存进行了划分。当然,这是系统的规定,物理内存条上并没有划分好的地址和空间范围。这些划分都是操作系统在逻辑上的划分。
软中断、硬中断
中断(硬)是一种电信号,当设备有某种事情发生的时候,他就会产生中断,通过总线把电信号发送给中断控制器。如果中断的线是激活的,中断控制器就把电信号发送给处理器的某个特定引脚。处理器于是立即停止自己正在做的事,跳到中断处理程序的入口点,进行中断处理
软中断: CPU内部中断,即执行软件中断指令INT或遇到软件陷阱而产生的中断,它们的中断类型号已由CPU规定好
硬中断: CPU以外的I/O设备产生的中断
P99、P999
称之为分位数,分位数是将总体的全部数据按从小到大顺序排列后,处于各等分位置的变量值。
例如 p999=4.22124273,代表99.9%的请求响应时间不大于4.22124273ms,p表示:percent 百分比。
脏页
脏页是Linux内核中的概念,因为硬盘的读写速度远远赶不上内存的速度,系统就把读写比较频繁的数据事先放到内存中,以提高读写速度,这就是高速缓存,Linux是以页作为高速缓存的单位,当进程修改了高速缓存里的数据时,该页就被内核标记为脏页,内核将会在合适的时间把脏页的数据写到磁盘中,以保持高速缓存中的数据同磁盘中的数据是一致的
参考链接