HBase 源码分析之 WAL
前言
WAL(Write-Ahead Logging)是数据库系统中保障原子性和持久性的技术,通过使用 WAL 可以将数据的随机写入变为顺序写入,可以提高数据写入的性能。
在 HBase 中写入数据时,会将数据写入内存同时写 WAL 日志, 为防止日志丢失,日志是写在 HDFS 上的
默认是每个 RegionServer 有1个WAL,在 HBase1.0 开始支持多个WAL HBASE-5699
,这样可以提高写入的吞吐量。配置参数为 hbase.wal.provider=multiwal, 支持的值还有defaultProvider和filesystem(这2个是同样的实现)。

WAL 持久化级别
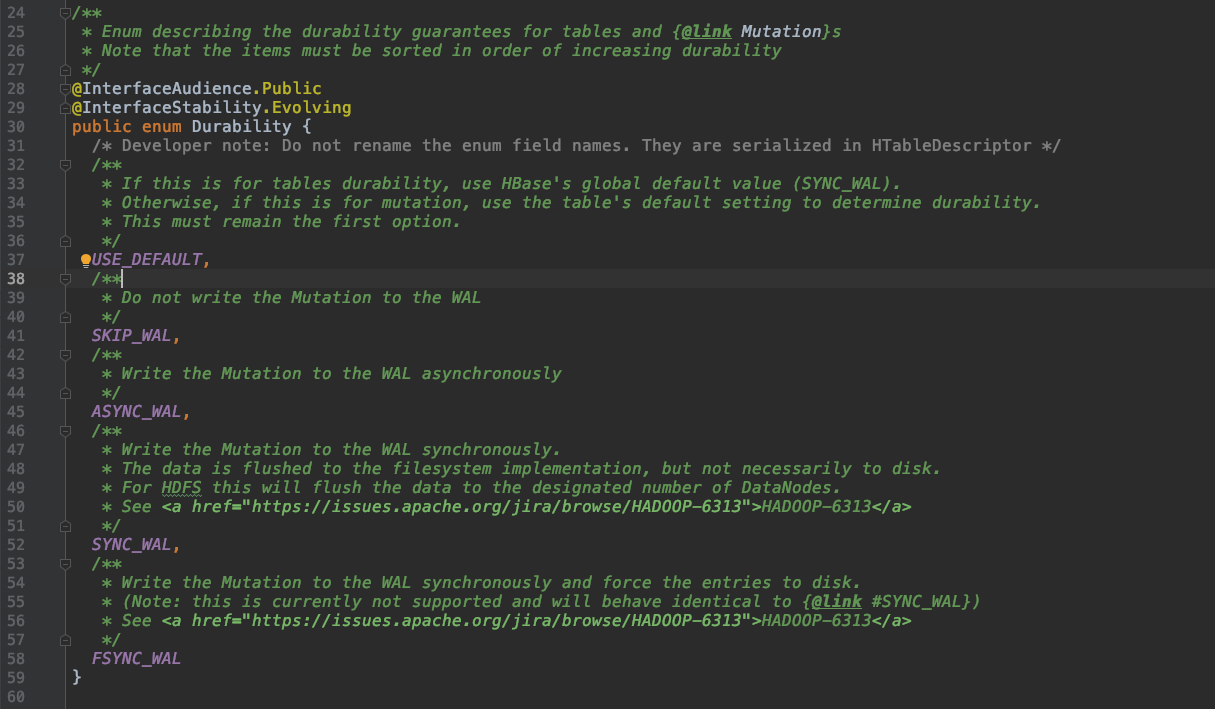
HBase 中可以通过设置 WAL 的持久化等级决定是否开启 WAL 机制、以及 HLog 的落盘方式。
- USE_DEFAULT: 如果没有指定持久化级别,则默认为 USE_DEFAULT, 这个为使用 HBase 全局默认级别(SYNC_WAL)
- SKIP_WAL: 不写 WAL 日志, 这种可以较大提高写入的性能,但是会存在数据丢失的危险,只有在大批量写入的时候才使用(出错了可以重新运行),其他情况不建议使用。
- ASYNC_WAL: 异步写入
- SYNC_WAL: 同步写入wal日志文件,保证数据写入了DataNode节点。
- FSYNC_WAL: 目前不支持了,表现是与SYNC_WAL是一致的
用户可以通过客户端设置WAL持久化等级,设置put的属性。
代码:put.setDurability(Durability. SYNC_WAL);
WAL 持久化保障 HBase 行级事务的持久性
WAL 结构
WAL 结构可以参阅HBase 行锁与多版本并发控制 (MVCC)的原子性保障
WALKey: WAL日志的key, 包括 log sequncece number 作为 HFile 中一个重要的元数据,和 HLog 的生命周期息息相关;regionName–日志所属的region, tablename–日志所属的表,writeTim–日志写入时间,clusterIds–cluster的id,在数据复制的时候会用到。
WALEdit: 在 HBase 行级事务日志中记录一系列的修改的一条事务日志。另外WALEdit实现了Writable接口,可用于序列化处理。
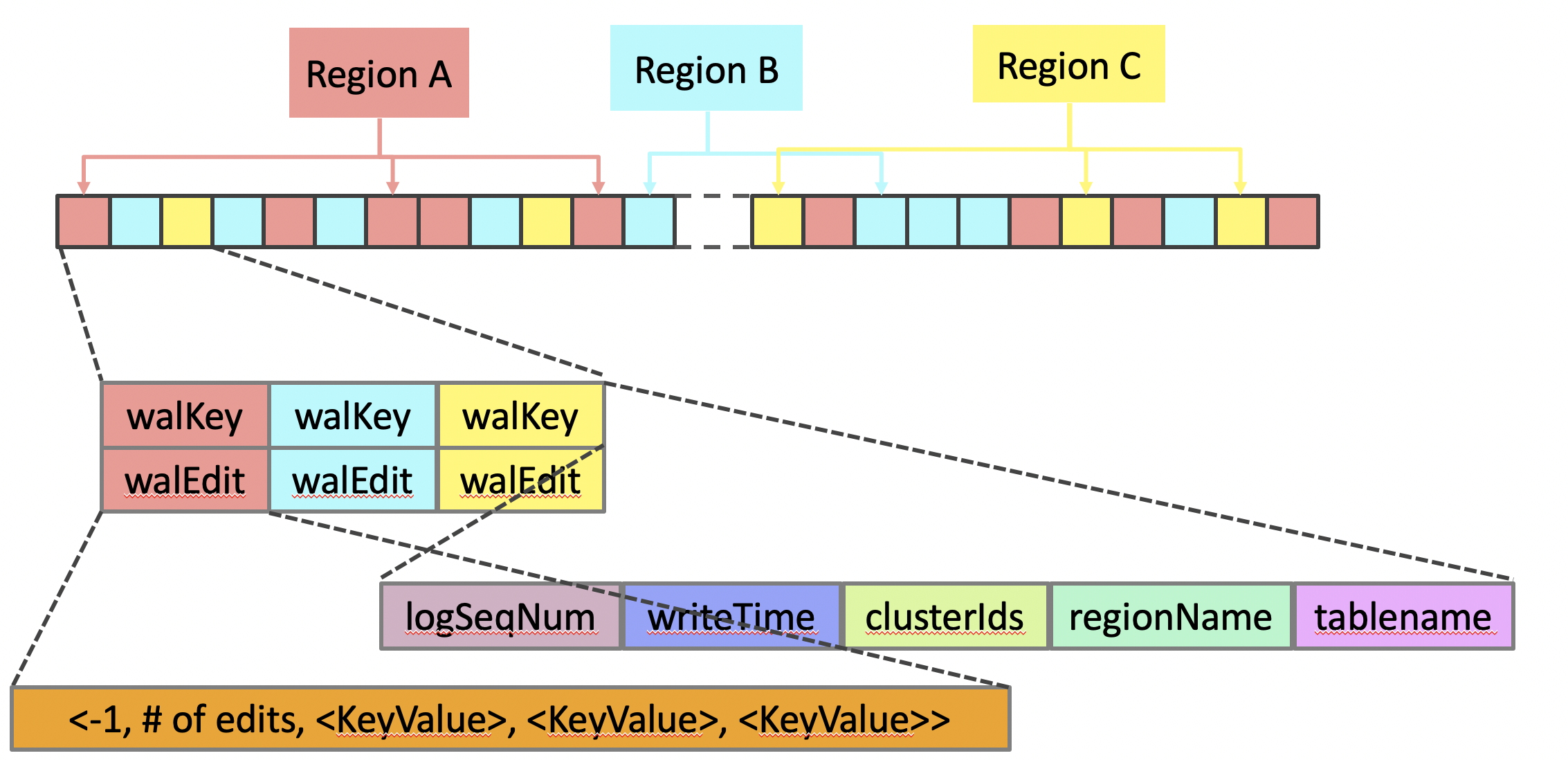
WAL 写入模型
这里将阐述 RegionServer 是如何把多个 client 的“写”操作安全有序地落地日志文件,又如何让 client 端优雅地感知到已经真正的落地。
Write Ahead Log (WAL)提供了一种高并发、持久化的日志保存与回放机制。
每一个业务数据的写入操作(PUT / DELETE)执行前,都会记账在WAL中。
如果出现HBase服务器宕机,则可以从WAL中回放执行之前没有完成的操作。
由于多个HBase客户端可以对某一台HBase Region Server发起并发的业务数据写入请求,因此WAL也要支持并发的多线程日志写入。——确保日志写入的线程安全、高并发。
对于单个HBase客户端,它在WAL中的日志顺序,应该与这个客户端发起的业务数据写入请求的顺序一致。
(对于以上两点要求,大家很容易想到,用一个队列就搞定了。见下文的架构图。)
为了保证高可靠,日志不仅要写入文件系统的内存缓存,而且应该尽快、强制刷到磁盘上(即WAL的Sync操作)。但是Sync太频繁,性能会变差。所以:
(1) Sync应当在多个后台线程中异步执行
(2) 频繁的多个Sync,可以合并为一次Sync——适当放松对可靠性的要求,提高性能。
其线程模型主要实现实在 FSHLog 中,FSHLog 是 WAL 接口的实现类,负责将数据写入文件系统,其实现了最关键的 apend() 和 sync() 方法
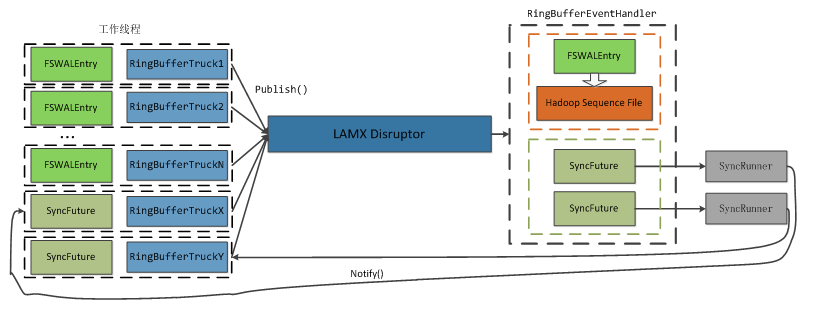
这个图主要描述了 HRegion 中调用 append() 和 sync() 后, HBase 的 WAL 线程流转模型。
最左边是有多个 client 提交到 HRegion 的 append 和 sync 操作。
当调用 append 后 WALEdit 和 WALKey 会被封装成 FSWALEntry 类进而再封装成 RinbBufferTruck 类放入一个线程安全的 Buffer(LMAX Disruptor RingBuffer) 中。可以理解成服务进程的缓存中
这里的队列是一个LMAX Disrutpor RingBuffer,可以简单理解为是一个无锁高并发队列。
当调用 sync 后会生成一个 SyncFuture 进而封装成 RinbBufferTruck 类同样放入这个 Buffer 中,然后工作线程此时会被阻塞等待被 notify() 唤醒。
在最右边会有一个且只有一个线程 (即RingBufferEventHandler) 专门去处理这些 RinbBufferTruck,如果是 FSWALEntry 则写入 hadoop sequence file。因为文件缓存的存在,这时候很可能 client 数据并没有落盘。
所以进一步如果是 SyncFuture 会被批量的放到一个线程池中,异步的批量去刷盘, 刷盘成功后唤醒工作线程完成 WAL。
这是我按照自己的理解画的图
源码分析
Region Server RPC服务线程
这些工作线程处理 HBase 客户端通过 RPC 服务调用(实际上是 Google Protobuf 服务调用)发出的业务数据写入请求。
对于Append操作
工作线程中当 HRegion 准备好一个行事务“写”操作的,WALEdit,WALKey 后就会调用FSHLog的append方法:
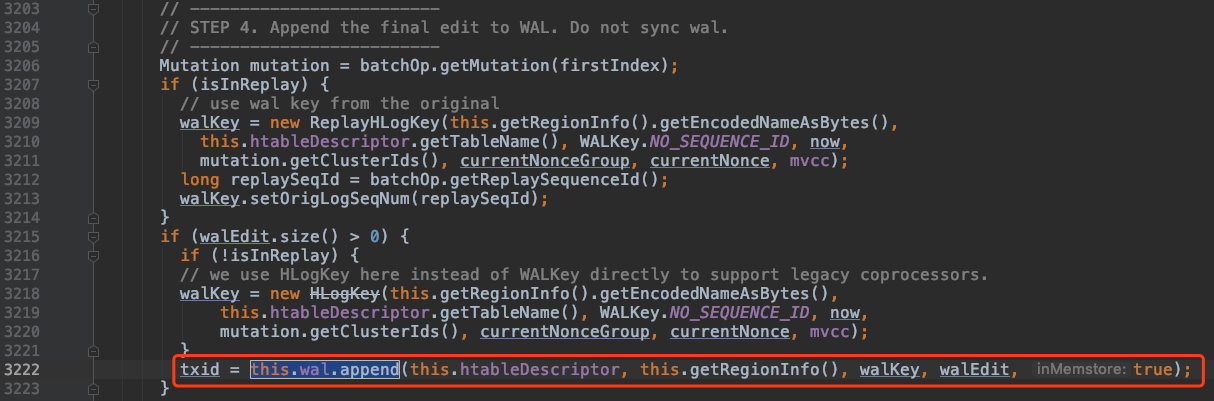
FSHLog 的 append 方法首先会从LAMX Disruptor RingbBuffer 中拿到一个序号作为 txid(sequence),然后把 WALEdit, WALKey 和 sequence 等构建一个 FSALEntry 实例 entry,
并把 entry 放到 ringbuffer 中。
而 entry 以 truck.loadPayload(RingBufferTruck,ringbuffer实际存储类型) 通过
sequence 和 ringbuffer 中的 RingBufferTruck 一一对应。
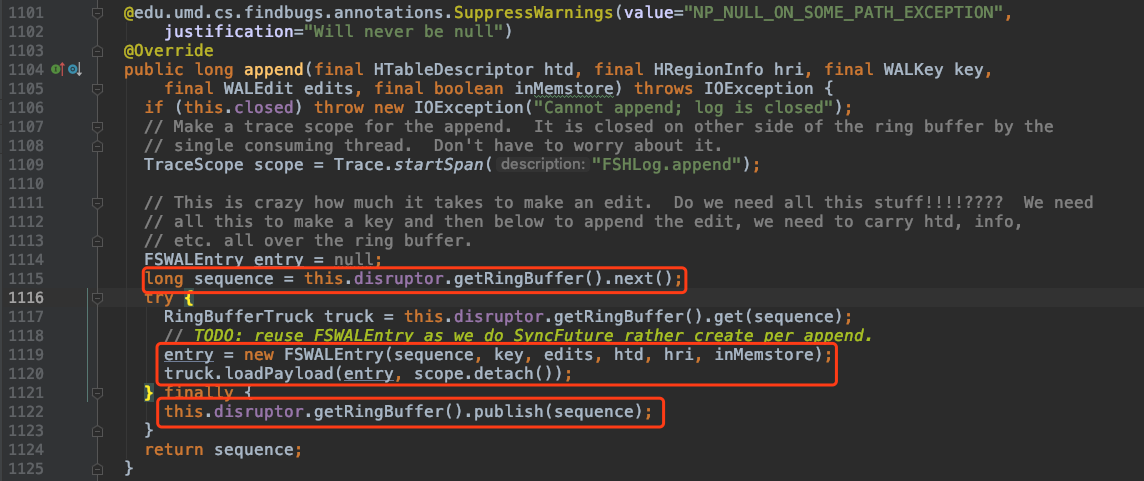
对于Sync操作
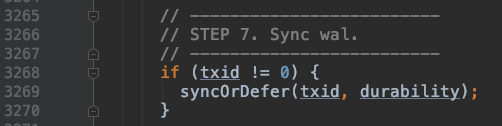
如果 client 设置的持久化等级是 USER_DEFAULT,SYNC_WAL或FSYNC_WAL
那么工作线程的 HRegion 还将调用 FSHLog 的 sync() 方法
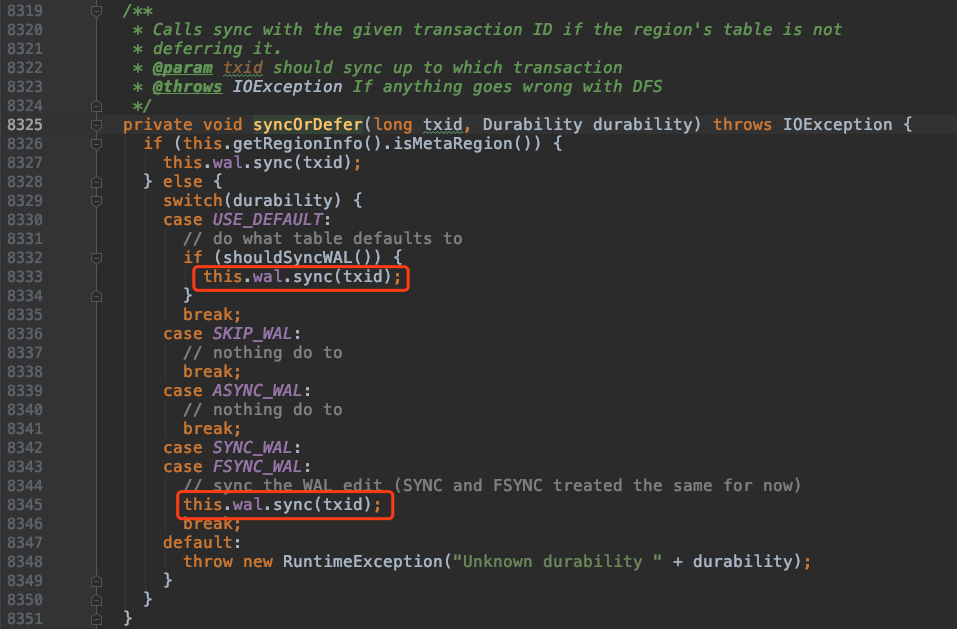
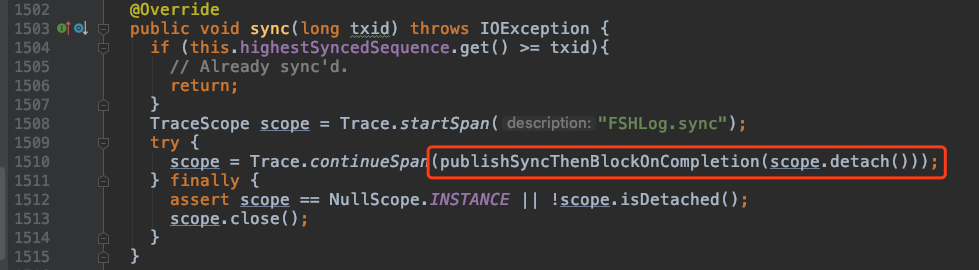
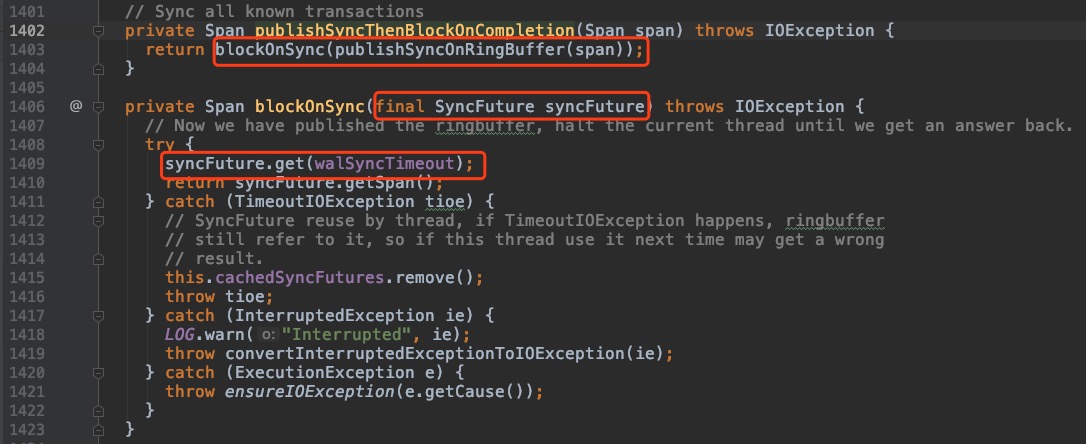
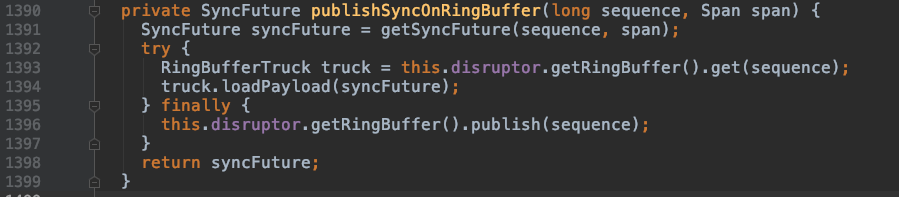
追踪代码可以分析出Sync()方法会往ringbuffer中放入一个SyncFuture对象,并阻塞等待完成(唤醒)。
WAL 日志消费线程
WAL机制中,只有一个 WAL 日志消费线程,从队列中获取 Append 和 Sync 操作。这样一个多生产者单消费者的模式,决定了 WAL 日志并发写入时日志的全局唯一顺序。
像模型图中所展示的多个工作线程封装后拿到由 ringbuffer 生成的 sequence 后作为生产者放入 ringbuffer 中。
在 FSHLog中有一个私有内部类 RingBufferEventHandler 类实现了 LAMX Disruptor的EventHandler 接口,也即是实现了 OnEvent 方法的 ringbuffer 的消费者。
Disruptor 通过 java.util.concurrent.ExecutorService 提供的线程来触发 Consumer 的事件处理,可以看到 HBase 的 WAL 中只启了一个线程。
从源码注释中也可以看到 RingBufferEventHandler 在运行中只有单个线程。
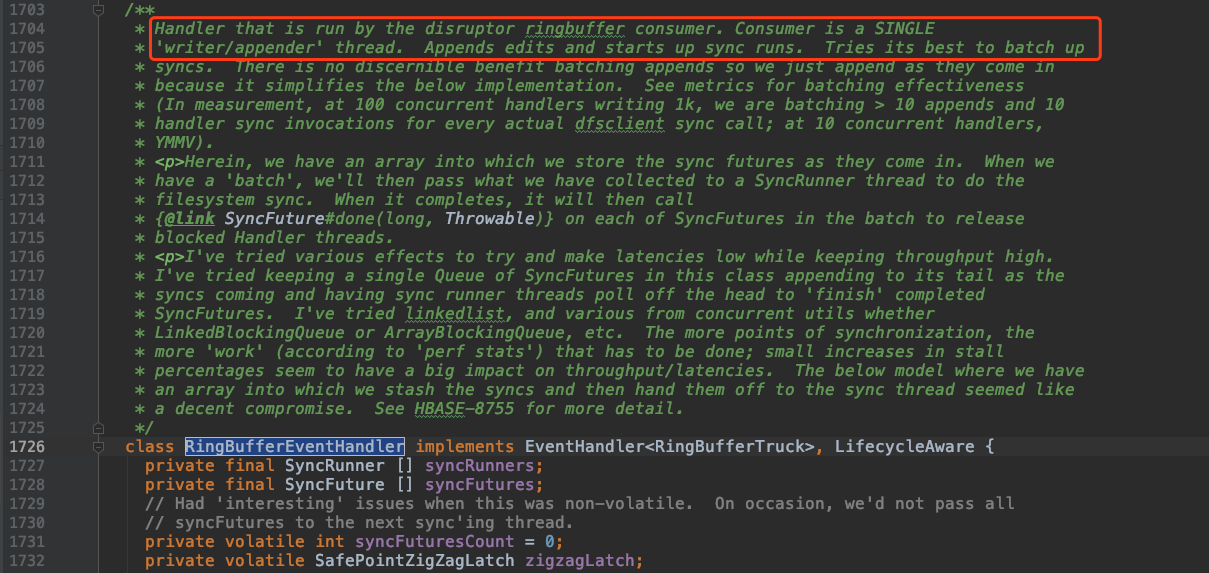
由于消费者是按照 sequence 的顺序刷数据,这样就能保证 WAL 日志并发写入时只有一个线程在真正的写入日志文件的可感知的全局唯一顺序。
RingBufferEventHandler类的onEvent()(一个回调方法)是具体处理append和sync的方法。
在前面说明过 WAL 使用 RingBufferTruck 来封装 WALEntry 和 SyncFuture (如下图源码)
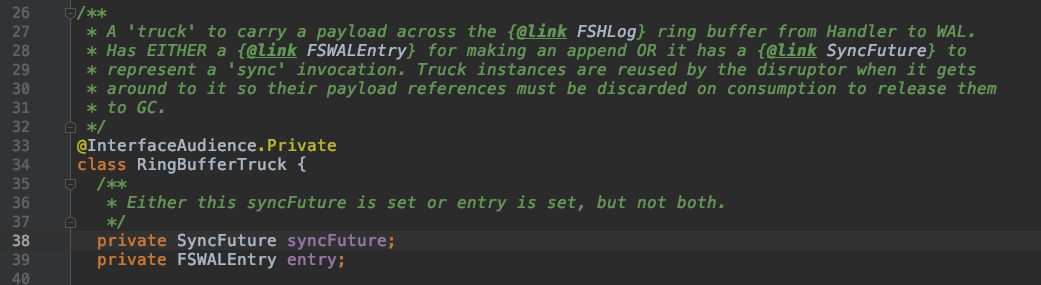
这部分源码可以看到 RingBufferTruck 类的结构,从注释可以看到选择 SyncFuture 和 FSWALEntry 一个放入 ringbuffer 中。
在消费线程的实际执行方法 onEvent( )中就是被 ringbuffer 通知一个个的从 ringbfer 取出 RingBufferTruck,如果是 WALEntry(即为FSWALEntry) 则使用当前 HadoopSequence 文件writer写入文件(此时很可能写的是文件缓存)
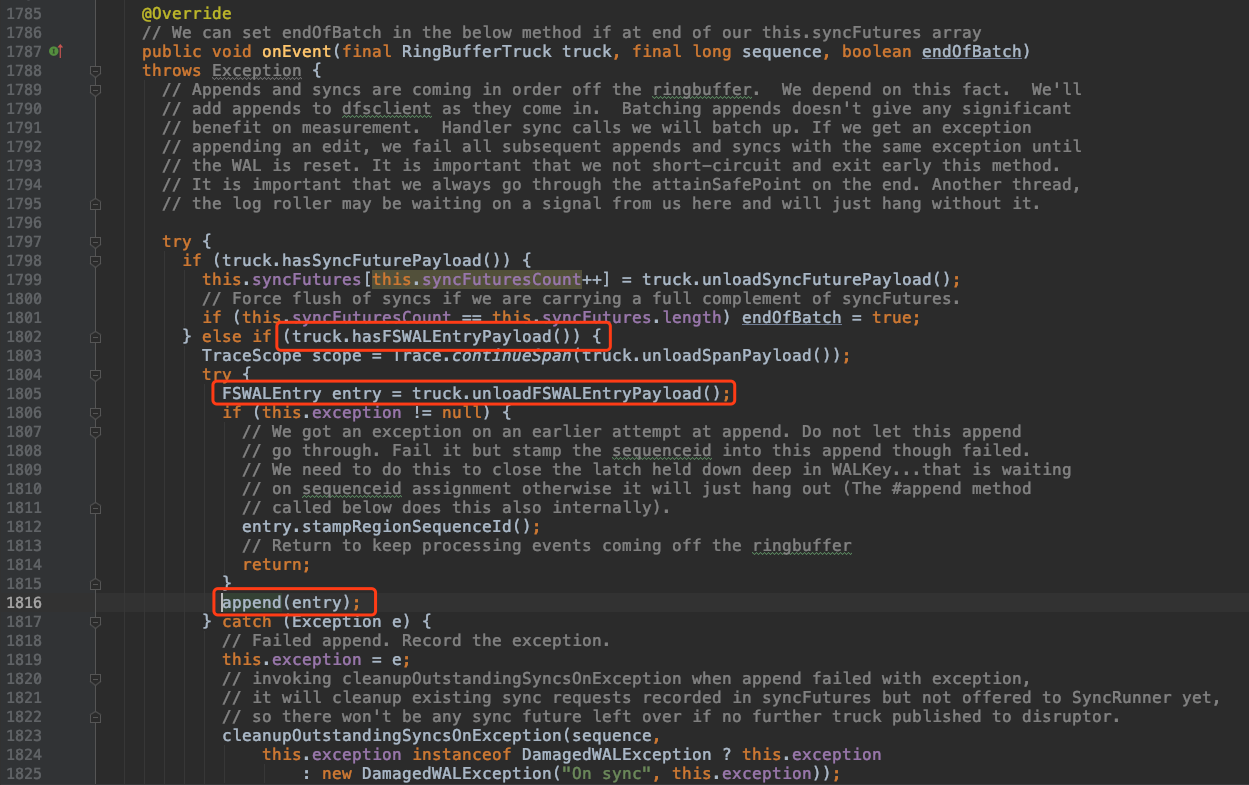
对于获取到的 Append 操作,直接调用 Hadoop Sequence File Writer 将这个 Append 操作(包括元数据和row key, family, qualifier, timestamp, value等业务数据)写入文件
如果是 SyncFuture 则简单的轮询处理放入 SyncRunner 线程异步去把文件缓存中数据刷到磁盘。
通过下面代码可以看到,先将 SyncFuture 累积到一个 syncFutures 数组中,syncFuturesCount 等于 this.syncFutures.length 长度时
endOfBatch 才等于 true
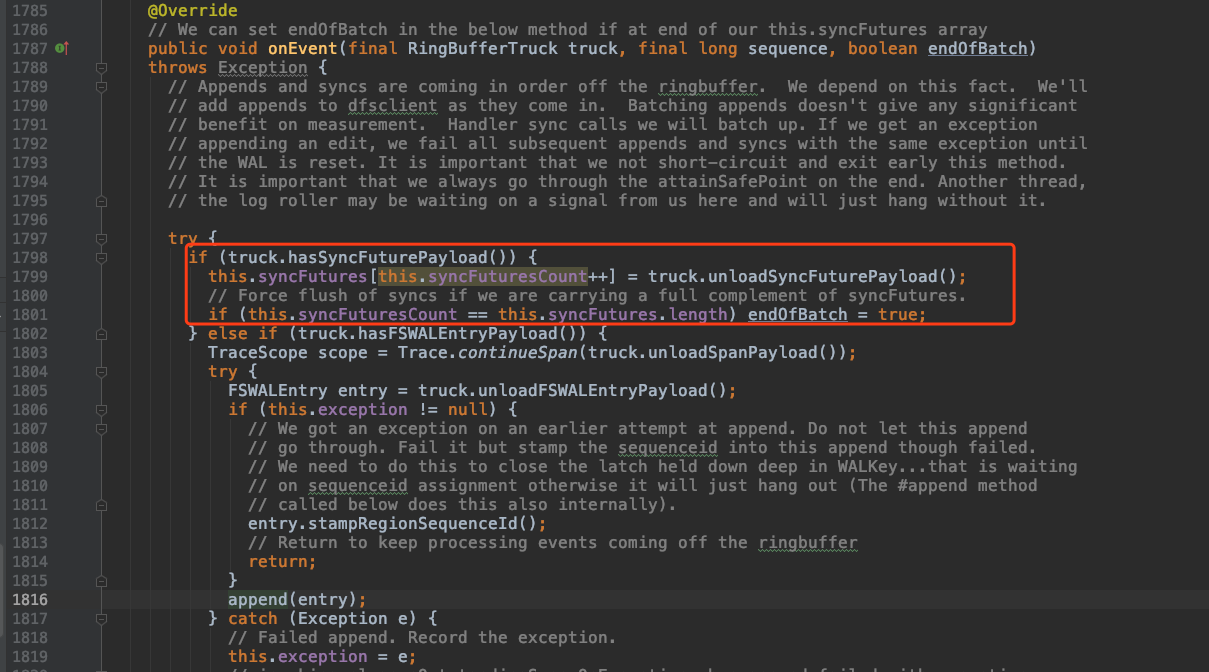
如果 endOfBatch 为 false 则不执行轮询代码。只有积累到一定长度 endOfBatch 为 true 时才执行轮询
这部分源码是说明 syn c操作的 SyncFutur e会被提交到 SyncRunner 中,这里可以注意 SyncFuture 实例其实并不是一个个提交到 SyncRunner 中执行的,而是以 syncFutures (数组,多个SyncFuture实例)方式提交的。
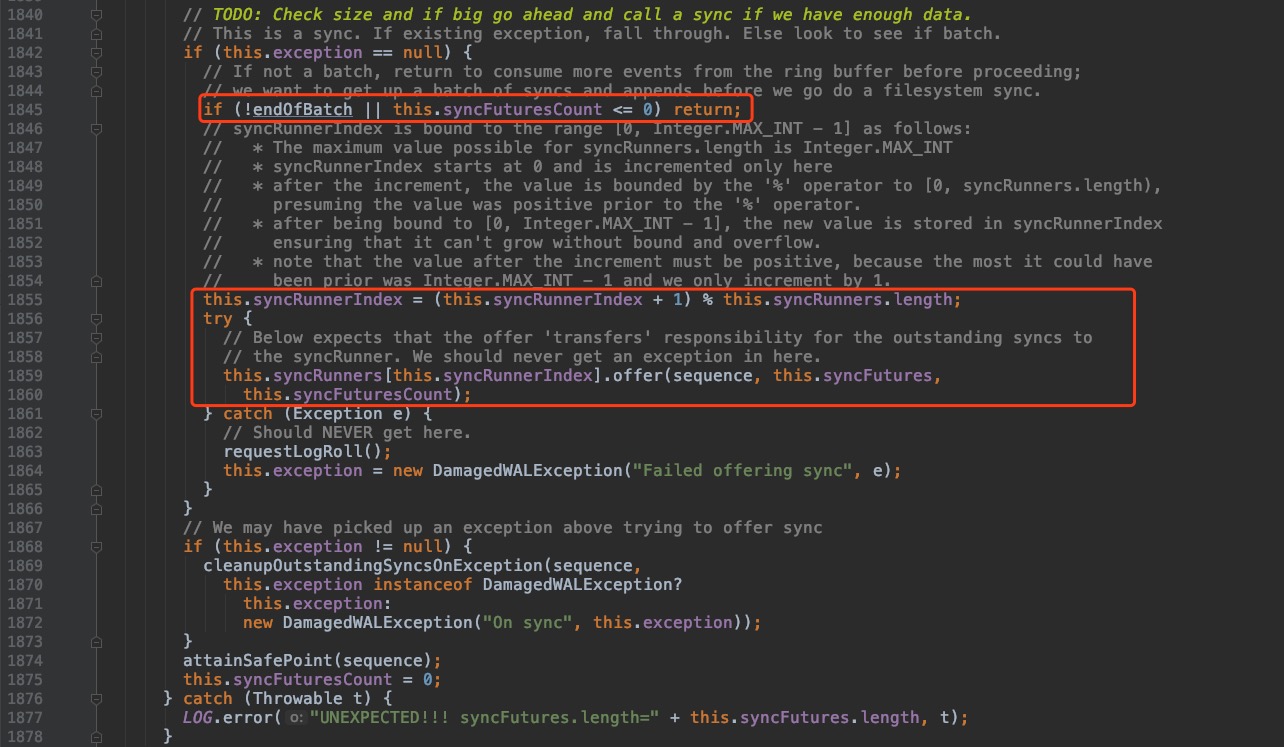
this.syncRunners 就是 SyncRunner 线程池。可以看到,通过计算syncRunnerIndex,采用了简单的轮循提交算法。

这里再加一个异步操作去真正刷文件缓存的原因 wal 源码中有解释: 刷磁盘是很费时的操作,
如果每次都同步的去刷 client 的回应比较快,但是写效率不高,如果异步刷文件缓存,写效率提高但是友好性降低
在考虑了写吞吐率和对 client 友好回应平衡后,wal选择了后者,积累了一定量(通过 ringbuffer 的 sequence)的缓存再刷磁盘以此提高写效率和吞吐率。
这个决策从 HBase 存储机制最初采用lsm树把随机写转换成顺序写以提高写吞吐率,可以看出是目标一致的。
SyncRunner线程
SyncRunner 是一个线程,WAL 实际有一个SyncRunner的线程组,专门负责之前append到文件缓存的刷盘工作。

SyncRunner的线程方法(run())负责具体的刷写文件缓存到磁盘的工作。
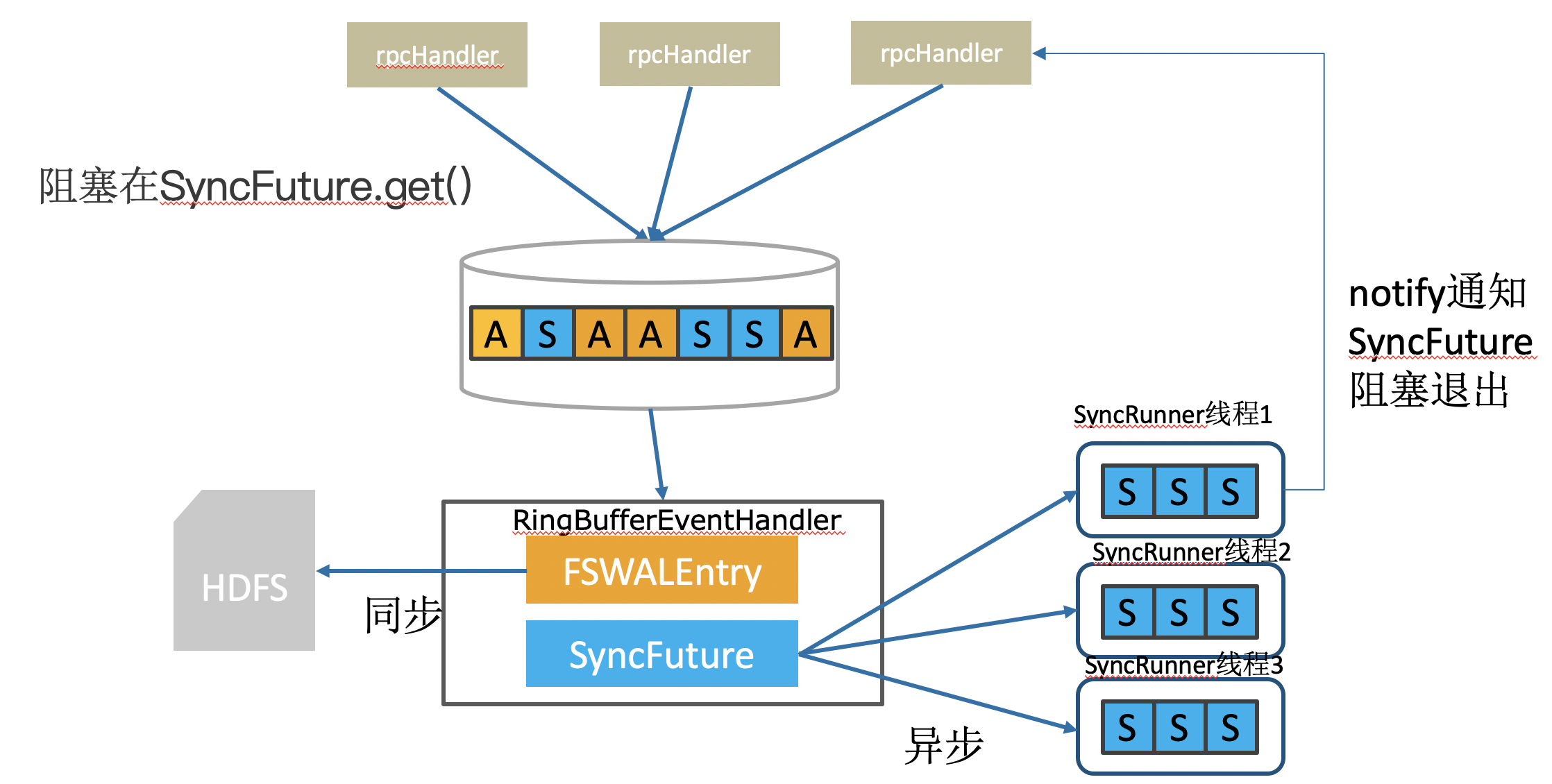
首先队列中获取一个由 WAL 日志消费线程提交的 SyncFuture (第一个红框)
即去之前提交的 SyncFutures 中拿到其中 sequence 最大的 SyncFuture 实例,并拿到它对应 ringbuffer 的sequence。
再去对比当前最大的 sequence (即currentHighestSyncedSequence),如果发现比当前最大的 sequence 小则去调用 releaseSyncFuture() 方法释放 synceFuture,
实际就是notify通知正被阻塞的sync操作,让工作线程可以继续往下继续。(第二个红框)
SyncRunner线程只会落实执行其中最新的 SyncFuture 所代表的Sync操作。而忽略之前的 SyncFuture。
调用文件系统 API,执行 sync() 操作 (第三个红框)
如果sync()完成,或者因为上面提到的合并忽略了某一个SyncFuture,那么会调用releaseSyncFuture() ==> Object.notify()来通知SyncFuture阻塞退出。
之前阻塞在SyncFuture.get()上的Region Server RPC服务线程就可以继续往下执行了。 (第四个红框)
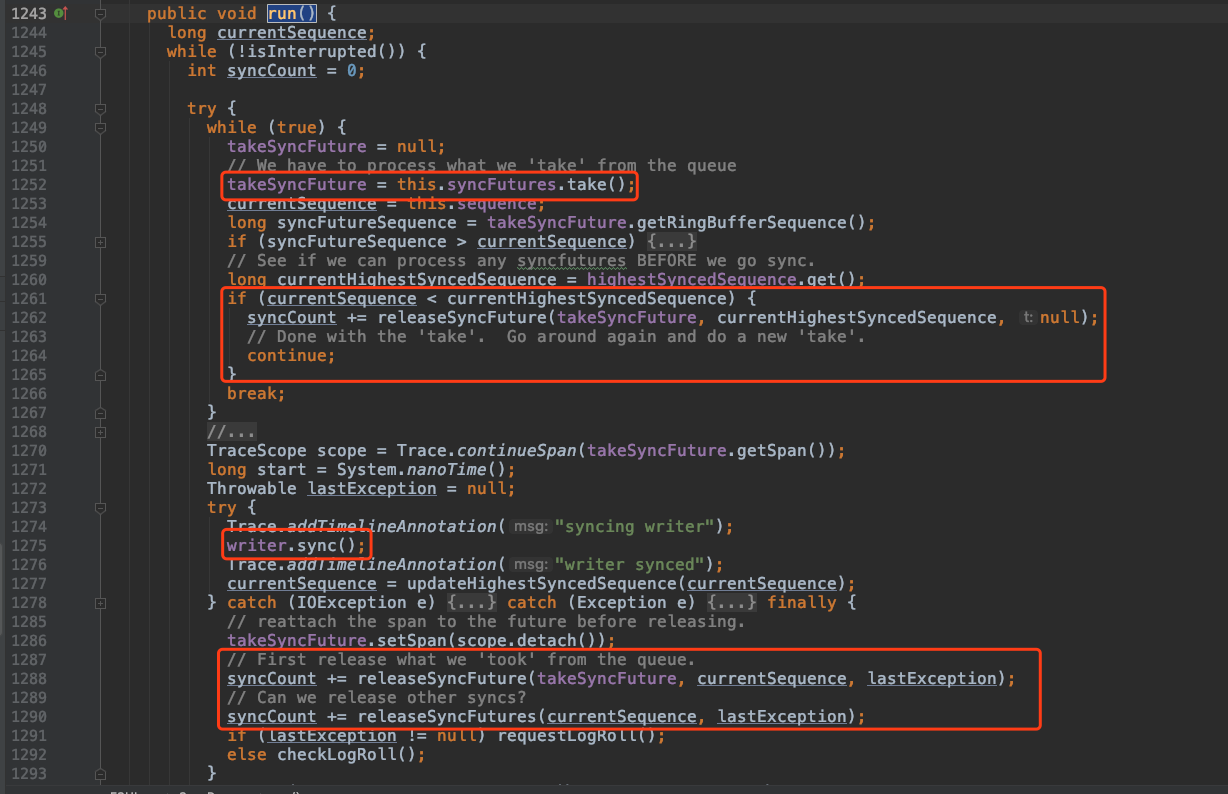
至此,整个WAL写入流程完成。
为什么 SyncRunner 是个线程池? 而不是单个线程。官方有介绍

同事解释说只有一个 SyncRunner 线程情况下, 第一个 sync 发出以后,来的写请求,只能等下一轮了,就会很慢。
我是这么理解的。sync 是个很耗时的操作,假设耗时 A。
第一个 sync 发生后,后面来的写请求如果 sync 得等待前一个 sync 耗时完成。
等前一个 sync 完成,和自己所在的 sync 完成,就是两个 A 的耗时。所以降低延迟,用多线程来 sync 可以提高效率
参考链接