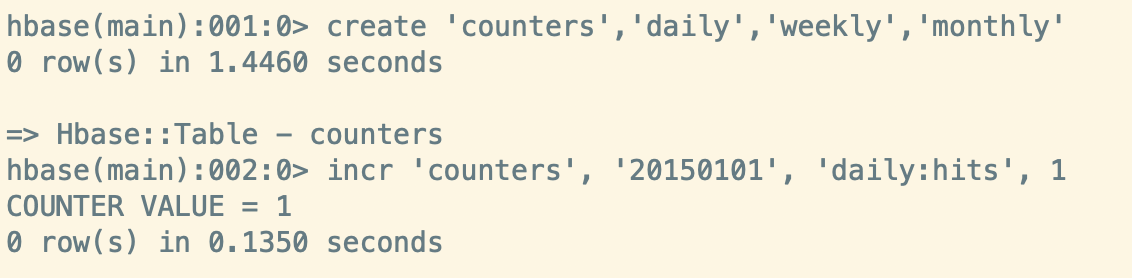
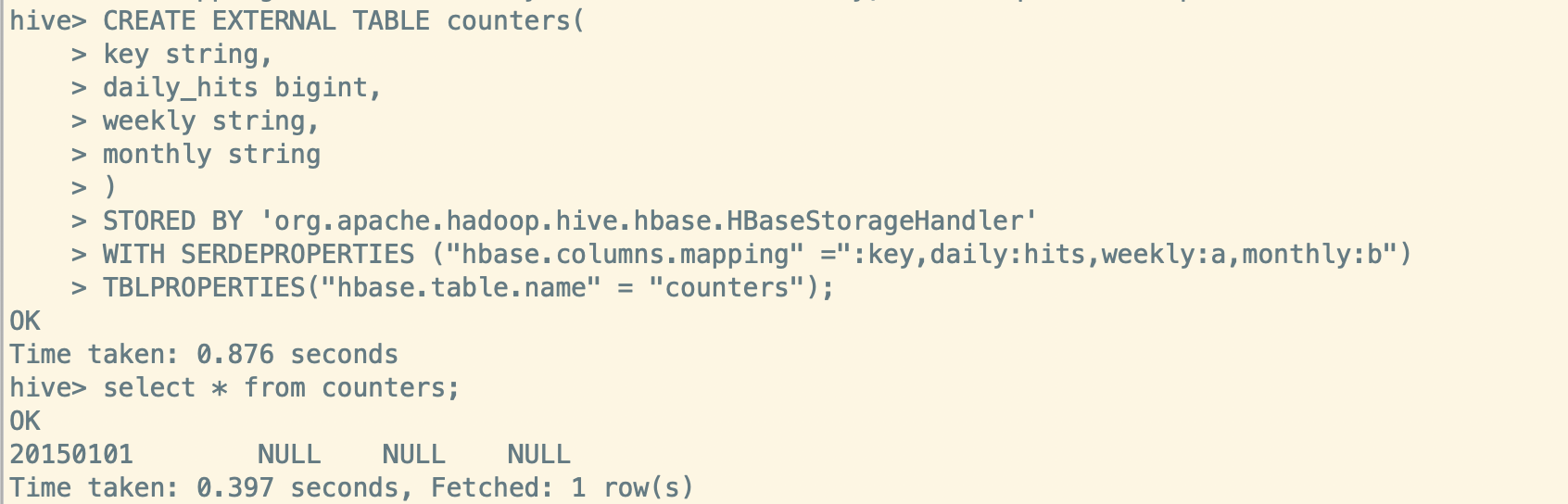
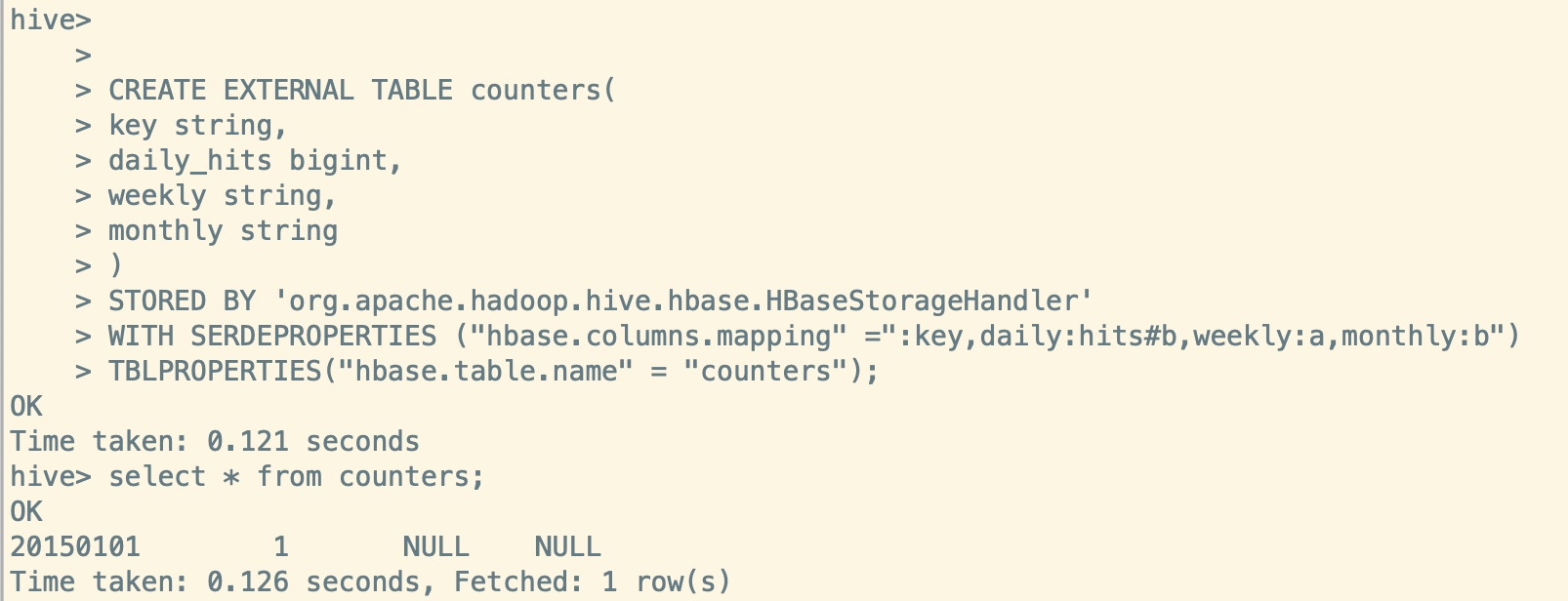
ERROR: org.apache.hadoop.hbase.DoNotRetryIOException: Field is not a long, it's 3 bytes wide at org.apache.hadoop.hbase.regionserver.HRegion.getLongValue(HRegion.java:7690) at org.apache.hadoop.hbase.regionserver.HRegion.applyIncrementsToColumnFamily(HRegion.java:7644) at org.apache.hadoop.hbase.regionserver.HRegion.doIncrement(HRegion.java:7530) at org.apache.hadoop.hbase.regionserver.HRegion.increment(HRegion.java:7487) at org.apache.hadoop.hbase.regionserver.RSRpcServices.increment(RSRpcServices.java:592) at org.apache.hadoop.hbase.regionserver.RSRpcServices.mutate(RSRpcServices.java:2246) at org.apache.hadoop.hbase.protobuf.generated.ClientProtos$ClientService$2.callBlockingMethod(ClientProtos.java:32383) at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:2150) at org.apache.hadoop.hbase.ipc.CallRunner.run(CallRunner.java:112) at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:187) at org.apache.hadoop.hbase.ipc.RpcExecutor$Handler.run(RpcExecutor.java:167)
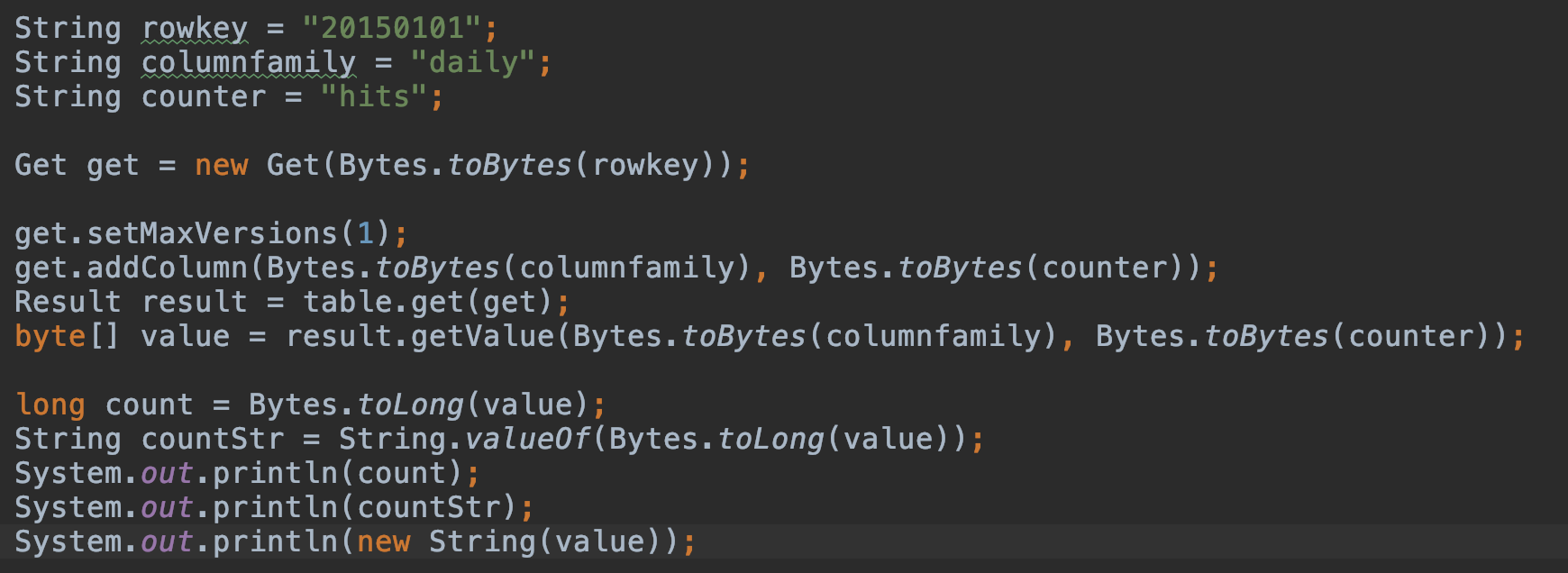
get.setMaxVersions(1); get.addColumn(Bytes.toBytes(columnfamily), Bytes.toBytes(counter)); Result result = table.get(get); byte[] value = result.getValue(Bytes.toBytes(columnfamily), Bytes.toBytes(counter));
long count = Bytes.toLong(value); String countStr = String.valueOf(Bytes.toLong(value));