Data Block Encoding Types
前言
AlstonWilliams 的HBase Data Block Encoding Types介绍写的挺好的
本文主要是翻译官方Data Block Encoding Types 部分
块压缩
HBase 中提供了五种 Data Block Encoding Types,具体有:
- NONE
- PREFIX
- DIFF
- FAST_DIFF
- PREFIX_TREE
NONE这种就不介绍了,这个很容易理解。
PREFIX
通常来说,key 总是相似的,拥有相同的前缀,只是末尾不相同。
例如,一个 Key 是 RowKey:Family:Qualifier0,
跟它相邻的下一个 Key 可能是 RowKey:Family:Qualifier1
在 PREFIX 编码中,会额外添加一字段表示当前行的 key 和前一行的 key
前缀相同长度
很明显,如果相邻 Key 之间,完全没有共同点,那 PREFIX 显然毫无用处,还增加了额外的开销.
当使用 NONE 这种 Block Encoding 时,如下图所示:
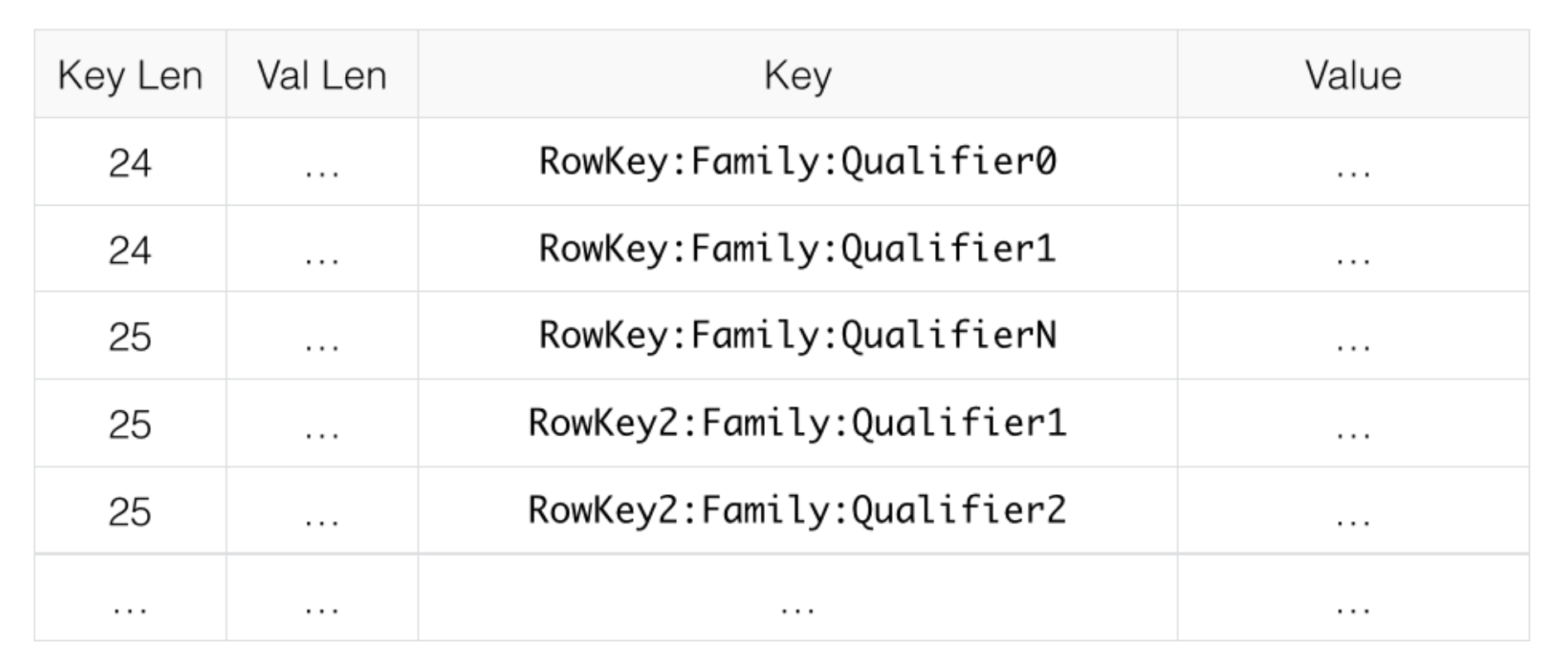
而如果采用 PREFIX 这种数据块编码,如下图所示:

此处的第一个 key 与之前的 key 完全不同,则其前缀长度为 0,
第二个 key 前缀长度为 23,因为它们前 23 个字符相同。
DIFF
DIFF 是在 PREFIX 基础上扩展,不在把 Key 看成一个整体,而是将 Key 每个键字段拆分,以便可以更有效地压缩键的每个部分。
它添加了两个新的字段 timestamp 和 type
如果 KeyB 的 ColumnFamily、key length、value length、Key type 和 KeyA 对应字段相同,那么它就会在 KeyB 中被省略.
此外,timestamp 存储的是相对于前一行 Row 的 timestamp 偏移量(即差值),而不是完整存储。
默认情况下,DIFF 是不建议启动的.因为它会导致写数据、Scan 数据更慢.但是相对于 PREFIX/NONE,它会在 BlockCache 中缓存更多数据.
用 DIFF 编码方式压缩之前的 block 如下图所示:

示例中的第一行、第二行,并给出 timestamp 和 type 精确匹配,key 长度也是相等的,所以第二行的 key length 和 type 都不需要存储,timestamp 存储与上一行的差值。
FAST_DIFF
FAST_DIFF 跟 DIFF 非常相似,所不同的是,它额外增加了一个字段,表示 RowB 是否跟 RowA 完全一样,如果是的话,那数据就不需要重复保存了.
如果在你的场景下,Key很长,或者有很多Column,那么推荐使用FAST_DIFF。
数据格式几乎与 DIFF 编码相同,因此没有图像来说明它。
PREFIX_TREE
PREFIX_TREE 是 HBase 0.96 中的一项实验功能。它已在 HBase-2.0.0 中删除。
参考链接