记一次 RegionServer 宕机排查过程
前言
头大,今天 HBase 集群写入压力过大,一直报压缩队列的警告。
接着突然间来了一个 RS 宕机的告警。凉凉。赶紧查看,同事已经先行一步将其启动起来了。
查看 CM 读写请求曲线,发现并不是很大。
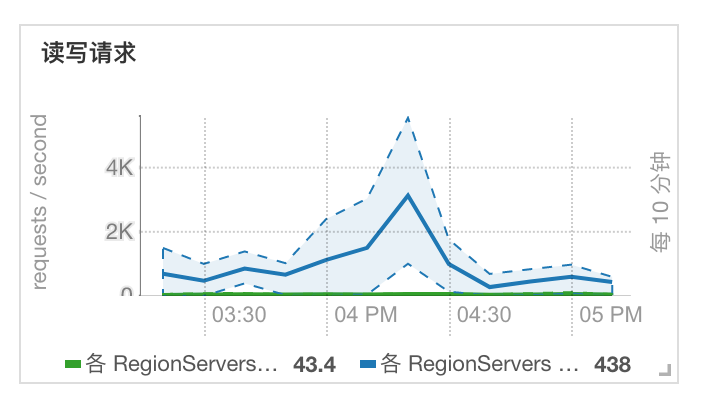
查看日志

可以看到有一段时间日志没有更新,往后看到下方日志
1 | 2019-06-24 16:47:28,787 WARN org.apache.hadoop.hbase.util.Sleeper: We slept 258006ms instead of 3000ms, this is likely due to a long garbage collecting pause and it's usually bad, see http://hbase.apache.org/book.html#trouble.rs.runtime.zkexpired |
可以看出,HBase 发生了 Stop The World(停顿类型STW) ,导致整个进程所有线程被挂起了 257s。将近 4 分钟多。
查看对应的 GC 日志
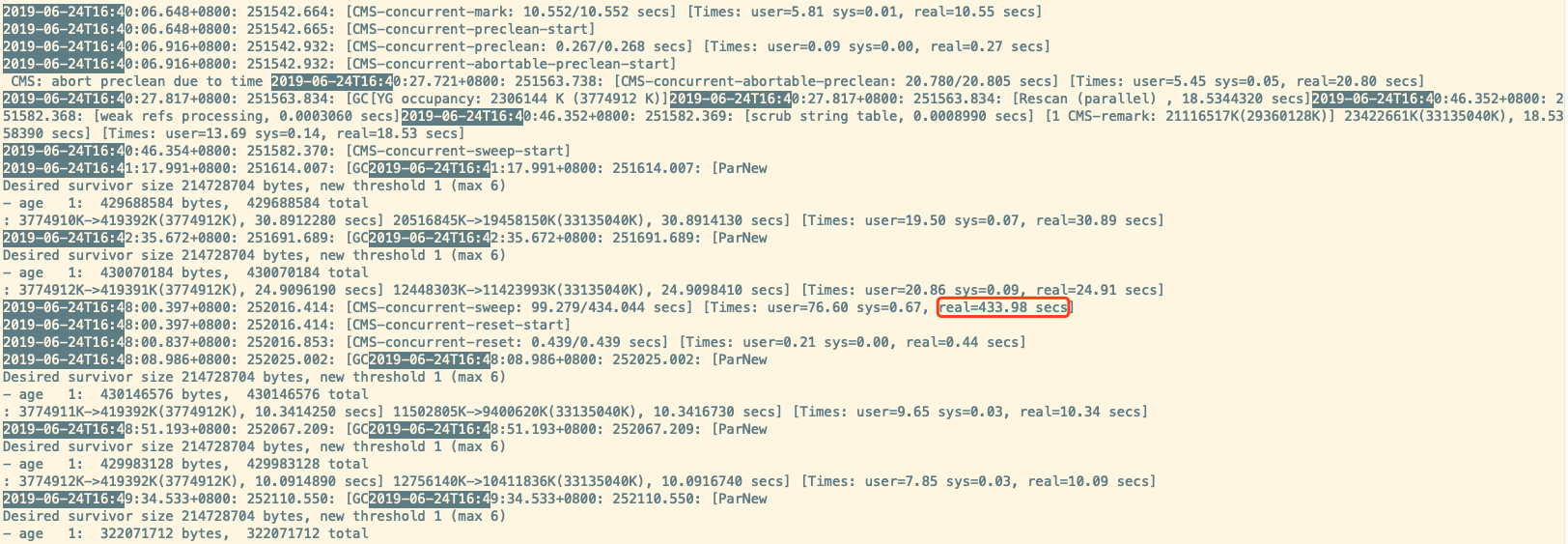
发现 CMS-concurrent-sweep 持续了 433.98 secs 。 orz
排查
接着来看看 RS 宕机的直接原因
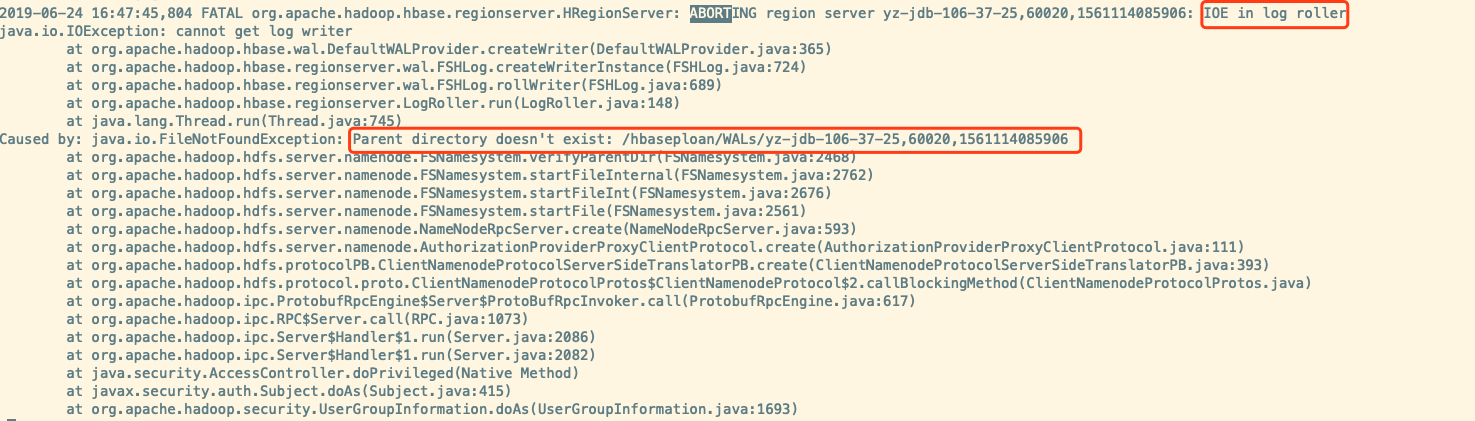
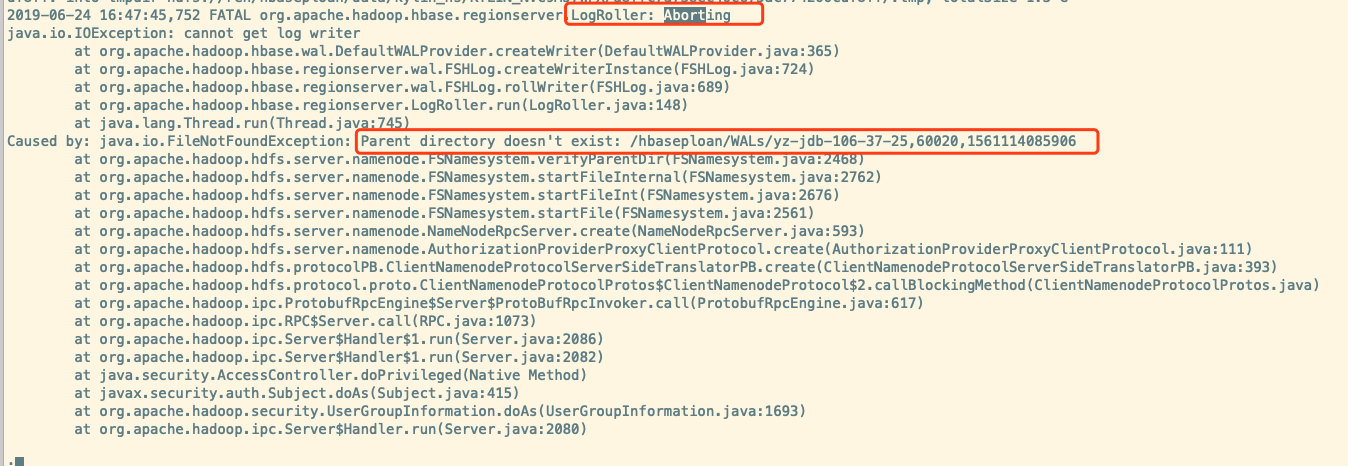
log 回滚报错,报错原因是 Parent directory doesn’t exist: /hbaseploan/WALs/yz-jdb-106-37-25,60020,1561114085906。
因为文件不存在了, log writer 获取失败。
为什么不存在呢? 接着看

看样子估计是 WAL 日志所在的块丢失了。
接着看为什么会丢失
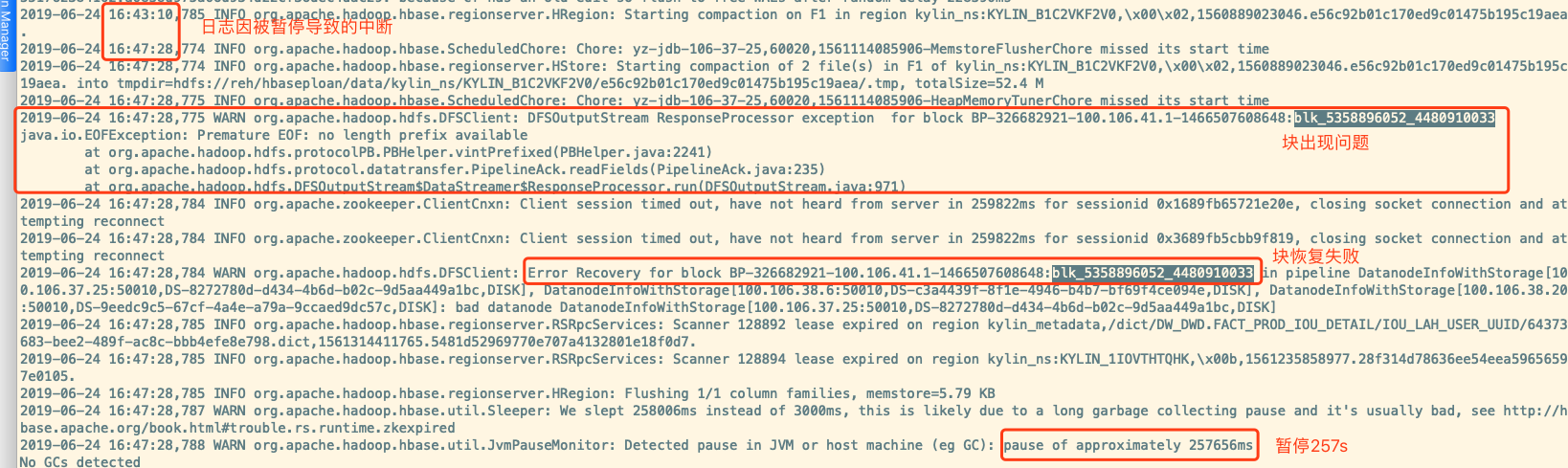
从日志内容来看应该是 HBase 调用DFSClient向 DN 写入 block 数据”BP-326682921-100.106.41.1-1466507608648:blk_5358896052_4480910033″,但是 DN 返回失败, recover 过程也是 ERROR的。具体失败原因需要查看 DN 节点日志,如下所示
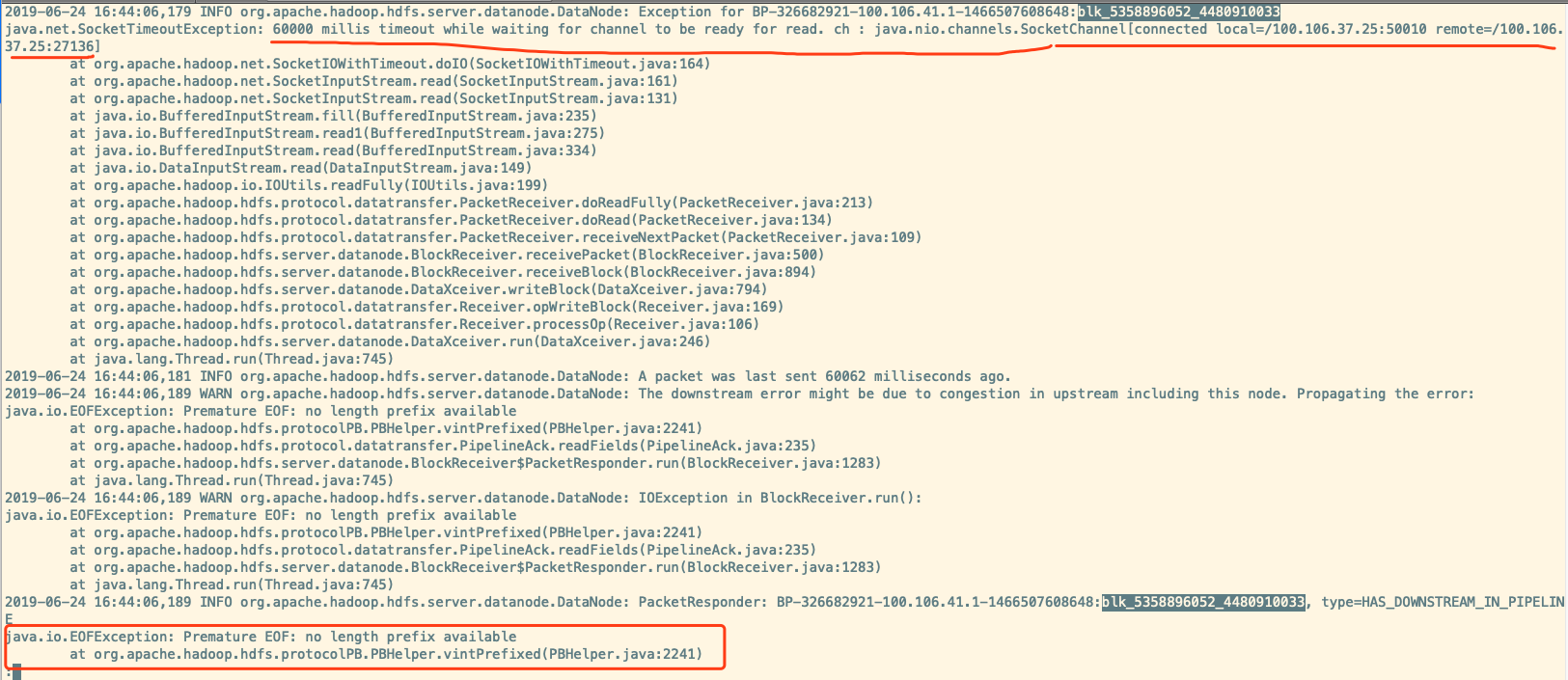
很显然,从日志可以看出,DN 一直在等待来自客户端的 read 请求,但是直至 SocketTimeout,请求都没有过来,此时 DN 会将该连接断开。
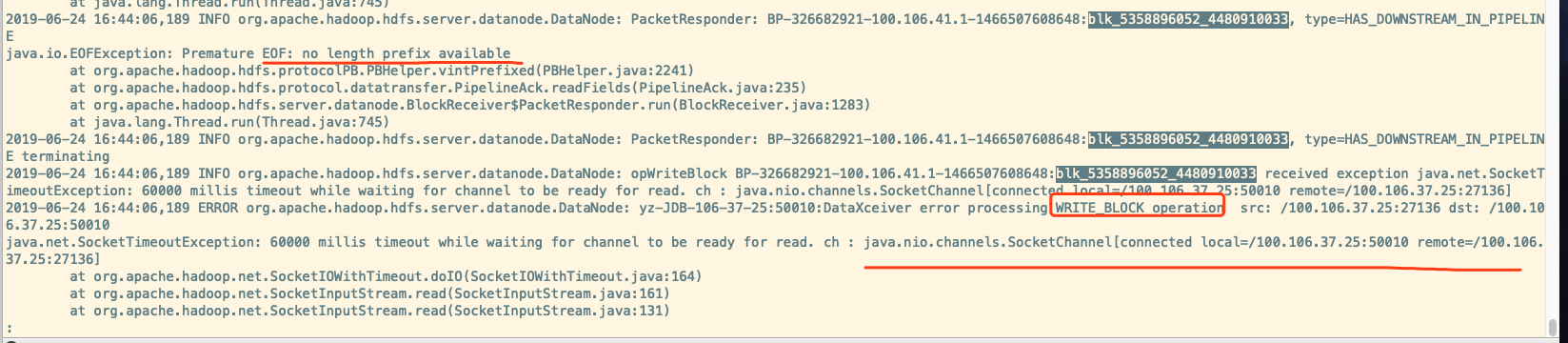
估计因为断开连接,所以这个 block 出现了写故障,恢复也失败了。
然后该块丢失导致 log 操作文件时失败。
因此 RS 才宕机的。
罪魁祸首就是 GC 导致的 Stop The World
但是什么导致的 GC。由于监控简陋,未清楚原因。打算研究部署一套 Ganglia 来实现监控。
为什么 block 恢复也失败。我也没找到原因。涉及到 HDFS pipeline 写。有机会补补这方面知识。
参考链接