HBase Region 过多导致的集群性能不佳
前言
有 10 个节点的HBase集群。每天早上 10 点所有 RS warn 告警。

持续过程 30 分钟。
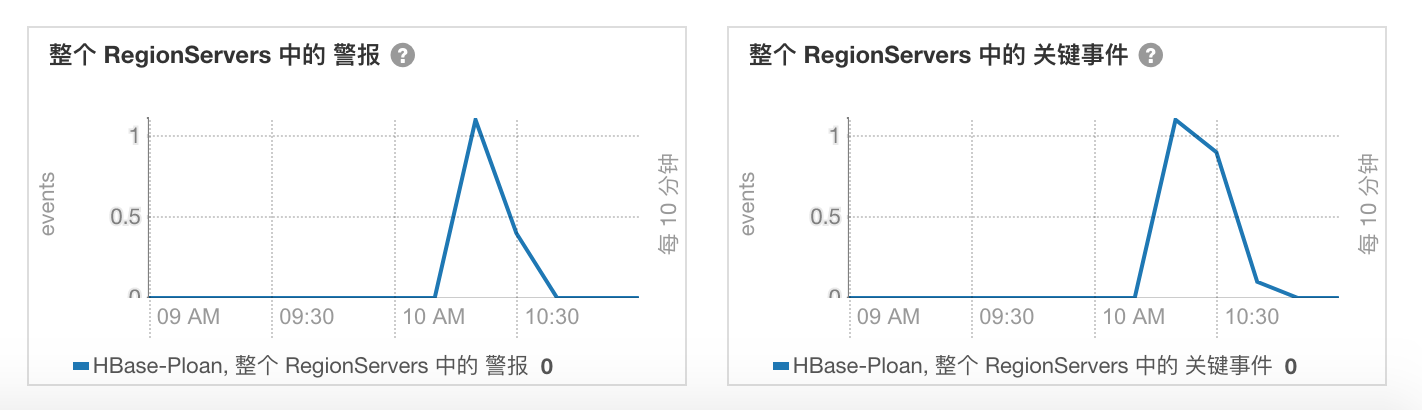
GC 时间过长,还触发了 RS 宕机。
问题分析
优先看 GC 告警的机器。查看 CM 监控发现该机器的 CPU,磁盘吞吐量在 10:00 - 10:30 这一段时间都是飙高的。
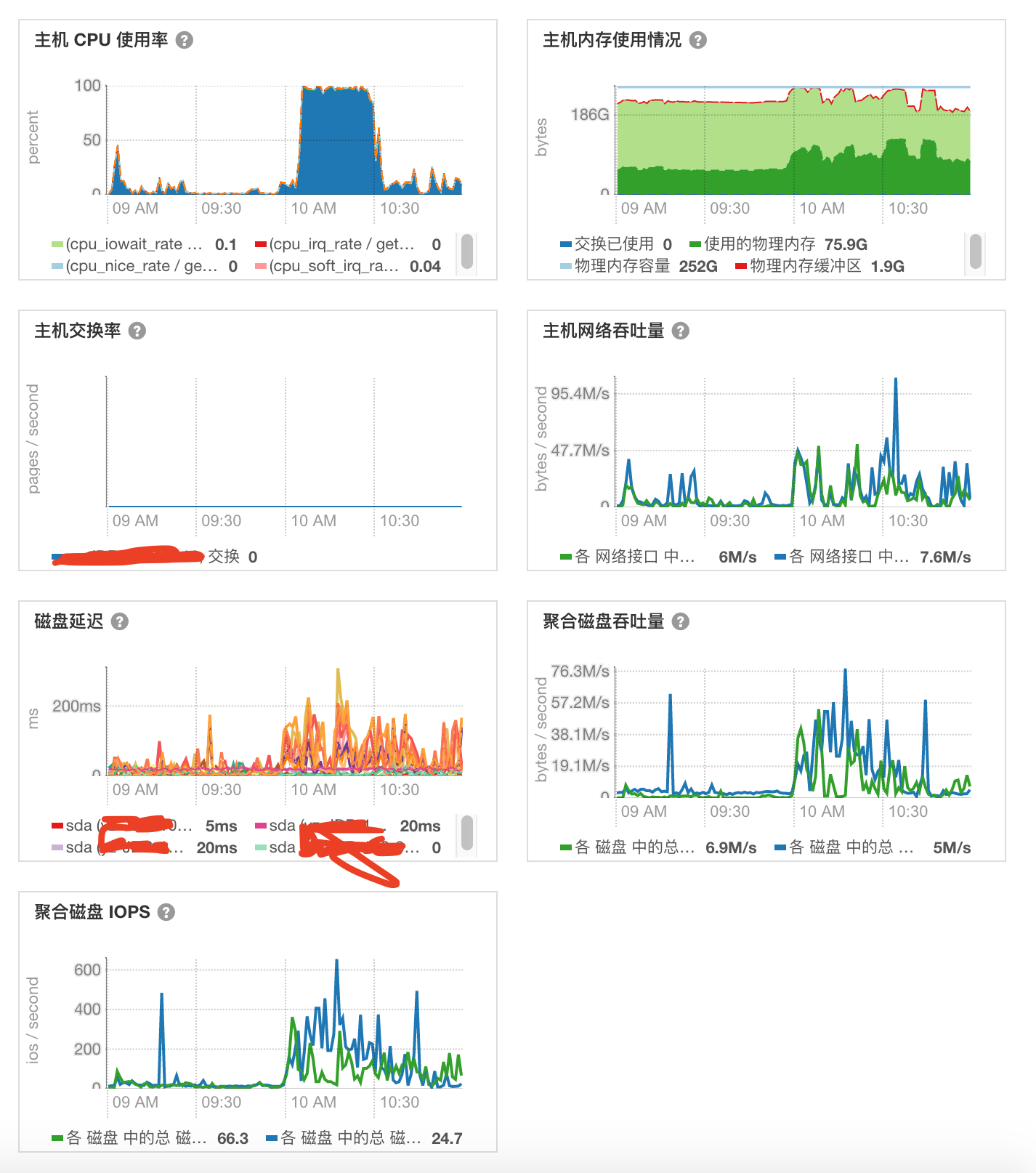
我接着查看发现所有的 RS 都是 10:00 - 10:30 这一段时间都是飙高的。
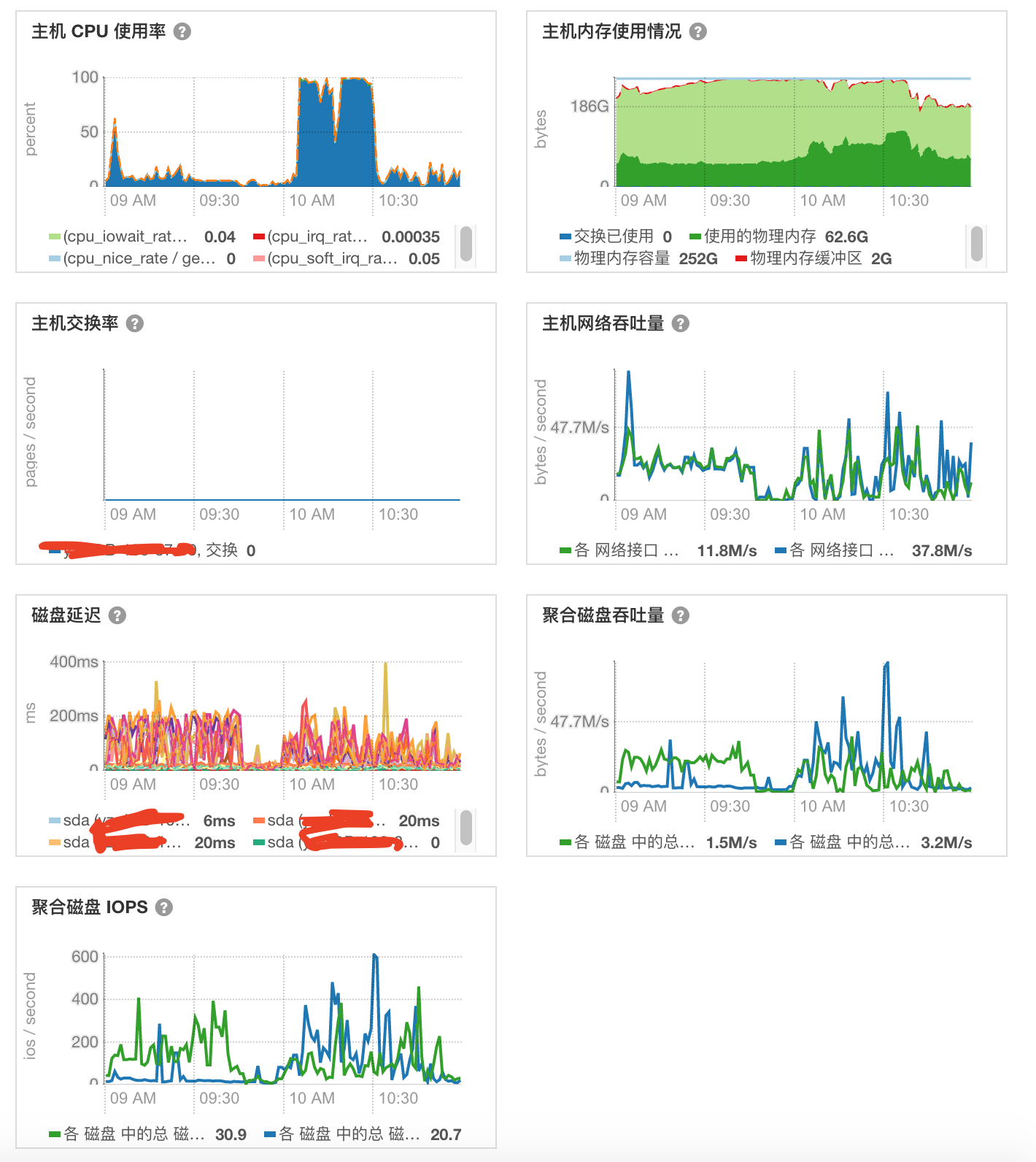
肯定是什么触发的。先看读写读写量。
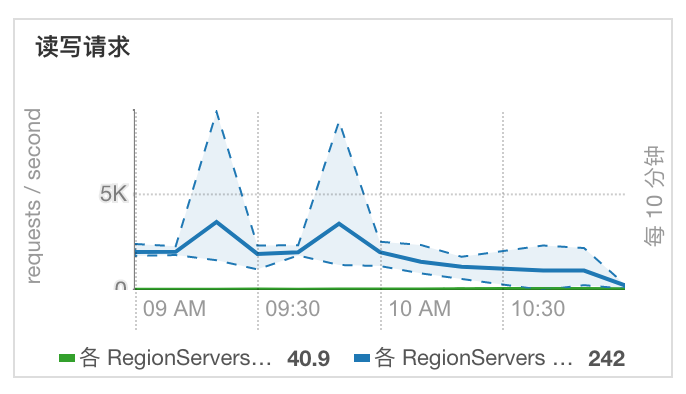
读写量也不大,说明不是由大批量请求造成的。
监控看不出问题,那就转战看日志。
发现有很多类似如下的输出:
... because info has and old edit so flush to free WALs after random delay ...
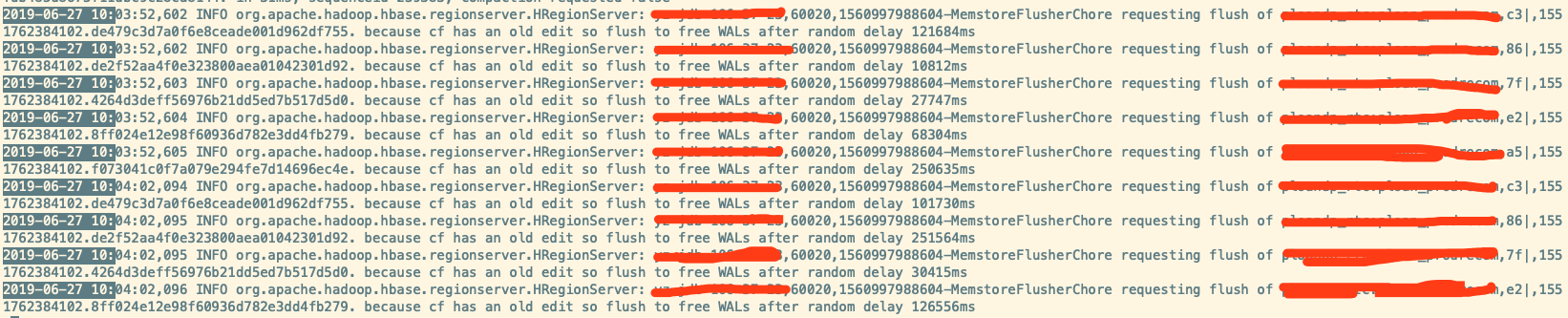
这是很明显的写入量很小,因为周期性 flush 线程触发的行为,比如某 store 很久没更新了而最新的 edit 距今超过阈值(默认 1小时),
那么就会 delay 一个 random 时间去执行刷新。参阅HBase Flush 时机
第5点定期刷新
通过如下关键字去看历次触发的 flush 产生的文件大小
1 | grep 'org.apache.hadoop.hbase.regionserver.HStore: Added hdfs' /var/log/hbase/hbase-cmf-hbase-REGIONSERVER-${FQDN_HOSTNAME}.log.out | awk '{print $1" "$2" "$(NF-1)$NF}' |
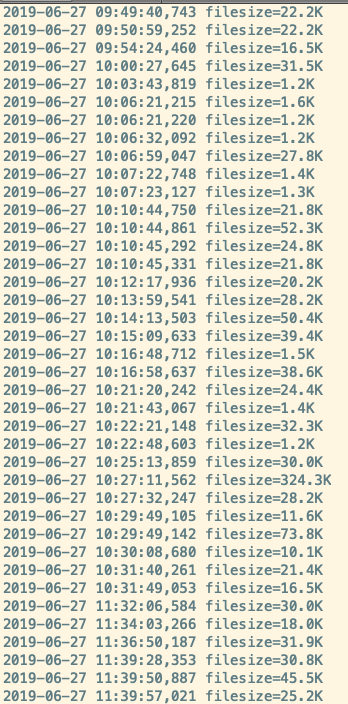
发现几乎每次刷出来的都是小文件,不到 100KB。
为什么这么多小文件呢?小文件过多会触发 compaction 机制。
刚好同事已经排查出小文件过多原因。
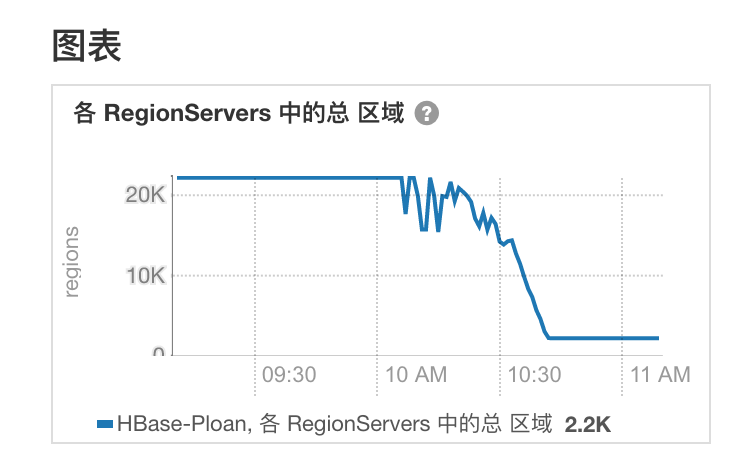
HBase 集群的 Region 个数达到了 2w 个。因为该 HBase 集群上有 Kylin 服务。Kylin 生成了大量的临时表。
而清理临时表的定时脚本因配置不当没有启动起来。导致该 HBase 集群 Region 个数越来越多。Region 越多,MemStore 刷新越小,
所以产生了小 HFile 文件。
compaction 机制检查到 Store 中 HFile 个数达到 3 个时就会执行 Compaction
同事手动运行脚本之后已经将 Region 个数降到 2k 左右了,平摊到 10 个RS就是 200+ 个。符合合理范围。HBase最佳实践之Region数量&大小
原因找到了,那我就找找 compaction 发生的痕迹。验证是由 compaction 触发导致服务器压力大。
根据监控上的时间点。看到 CPU 在 10:06 分达到峰值。在日志里查询 10:06 左右发生了什么事。

功夫不负有心人,看到关键CompactionChecker missed its start time(图中绿色框)。
翻译过来就是 CompactionChecker 线程丢失了开始时间。为什么丢失开始时间是因为发生了 GC 造成了 STW(图中蓝色框),线程被挂起了。这不是重点,接着往下看。
CompactionChecker 线程是干什么的?
CompactionChecker 是RS上的工作线程(Chore)。后台线程 CompactionChecker 定期触发检查是否需要执行 compaction,设置执行周期是通过 threadWakeFrequency 指定。
大小通过 hbase.server.thread.wakefrequency 配置(默认10000),然后乘以默认倍数 hbase.server.compactchecker.interval.multiplier (1000), 毫秒时间转换为秒。因此,在不做参数修改的情况下,CompactionChecker大概是2hrs 46mins 40sec 执行一次。
接着日志我往前翻上一次 CompactionChecker 时间。得到以下信息。
1 | 2019-06-27 07:12:02,093 INFO org.apache.hadoop.hbase.ScheduledChore: Chore: CompactionChecker missed its start time |
可以计算可以知道两个时间相差 2时 54分 18秒。符合 CompactionChecker 间隔时间。查看 RS 6点到 8点 CPU 监控。
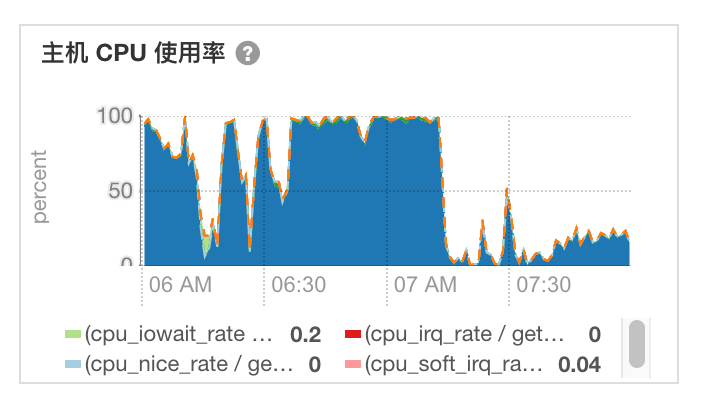
可以看出 7:12 之后 CPU 峰值降下来了。
正如猜想一样。CompactionChecker 是关键。
思路归纳
Region 过多会影响 HBase 状态。Region 之间共享 RS 的 MemStore 内存区域,因此 Region 过多,MemStore 刷新越小。
当 memstore 满后,就不得不刷新到文件系统,会创建一个数据存储在 HDFS 上的 HFile。
这也意味着 Region 越多,产生的 HFile 越小。
这个也迫使 HBase 执行大量的合并操作才能保持 HFile 的数量低至合理数目。
这些合并操作对集群产生了过多扰动,进而影响集群性能。
到了这里基本可以结案了。
参考链接