Flink 作业提交方式
前言
写了 Flink 代码之后,肯定得想着提交到集群上小跑一下,不然总觉得少了点什么。
Yarn
在 Yarn 上提交作业分为2种情况:
- yarn seesion
- Flink run
两者者对于现有大数据平台资源使用率有着很大的区别:
yarn seesion(Start a long-running Flink cluster on YARN) 这种方式需要先启动集群,然后在提交作业。
第二种 Flink run 直接在 YARN 上提交运行 Flink作业(Run a Flink job on YARN),这种方式的好处是一个任务会对应一个job, 即没提交一个作业会根据自身的情况,向 yarn 申请资源,直到作业执行完成,并不会影响下一个作业的正常运行,除非是yarn上面没有任何资源的情况下。
yarn seesion
不管采用客户端模式还是分离模式,提交作业都是一样的。
下面以 Flink 目录下的 LICENSE 为例,计算 WordCount 将处理后的数据放到 HDFS。
数据准备
首先上传数据到 HDFS
1 | hadoop fs -mkdir /user/root/test |
提交作业并查看结果
1 | ./bin/flink run ./examples/batch/WordCount.jar --input hdfs://nameservice1/user/root/test/LICENSE --output hdfs://nameservice1/user/root/test/result.txt |
对于Flink on yarn 作业提交后,若要在 Flink WEB UI上查看作业的,到完成 Job 里可以看到
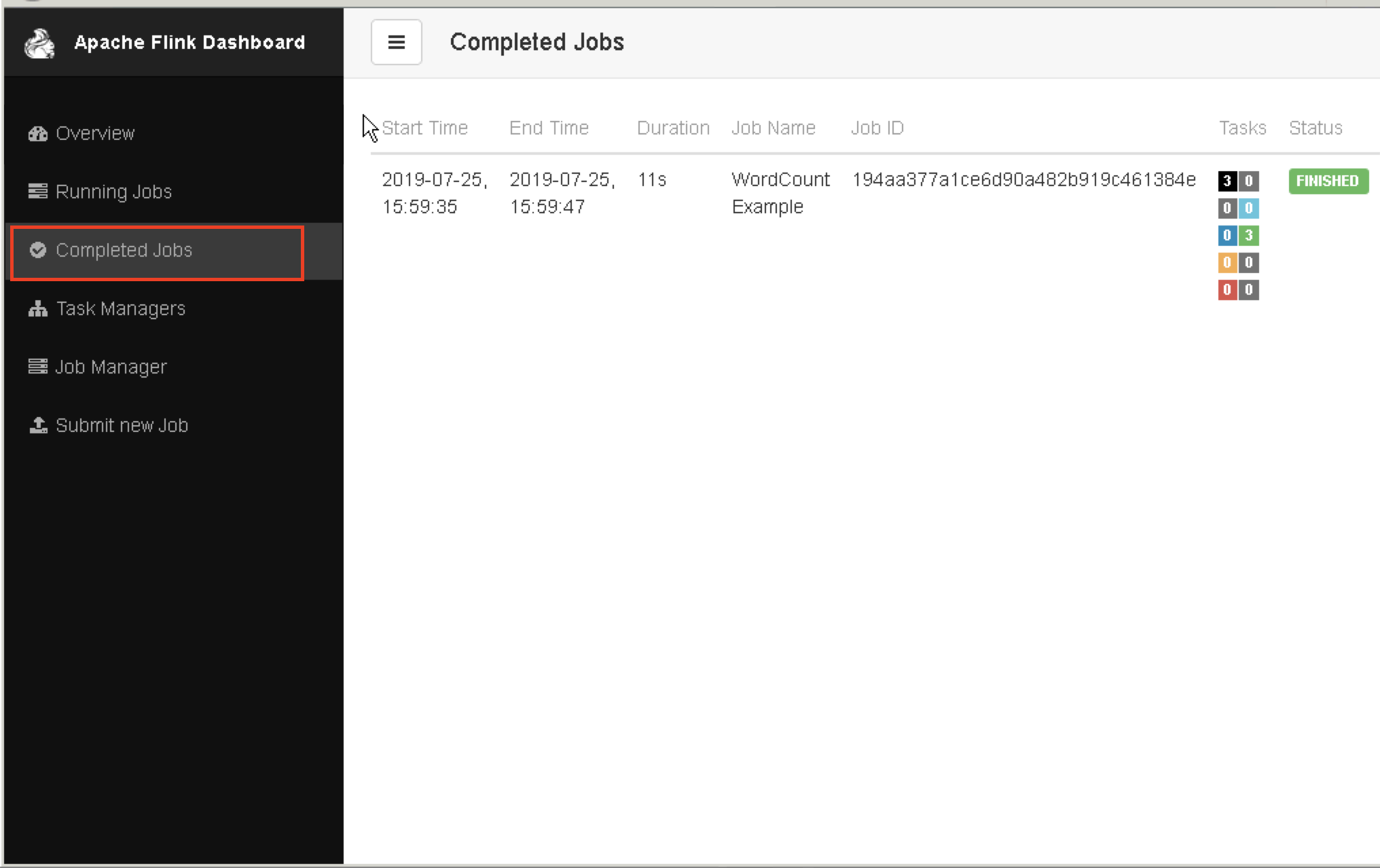
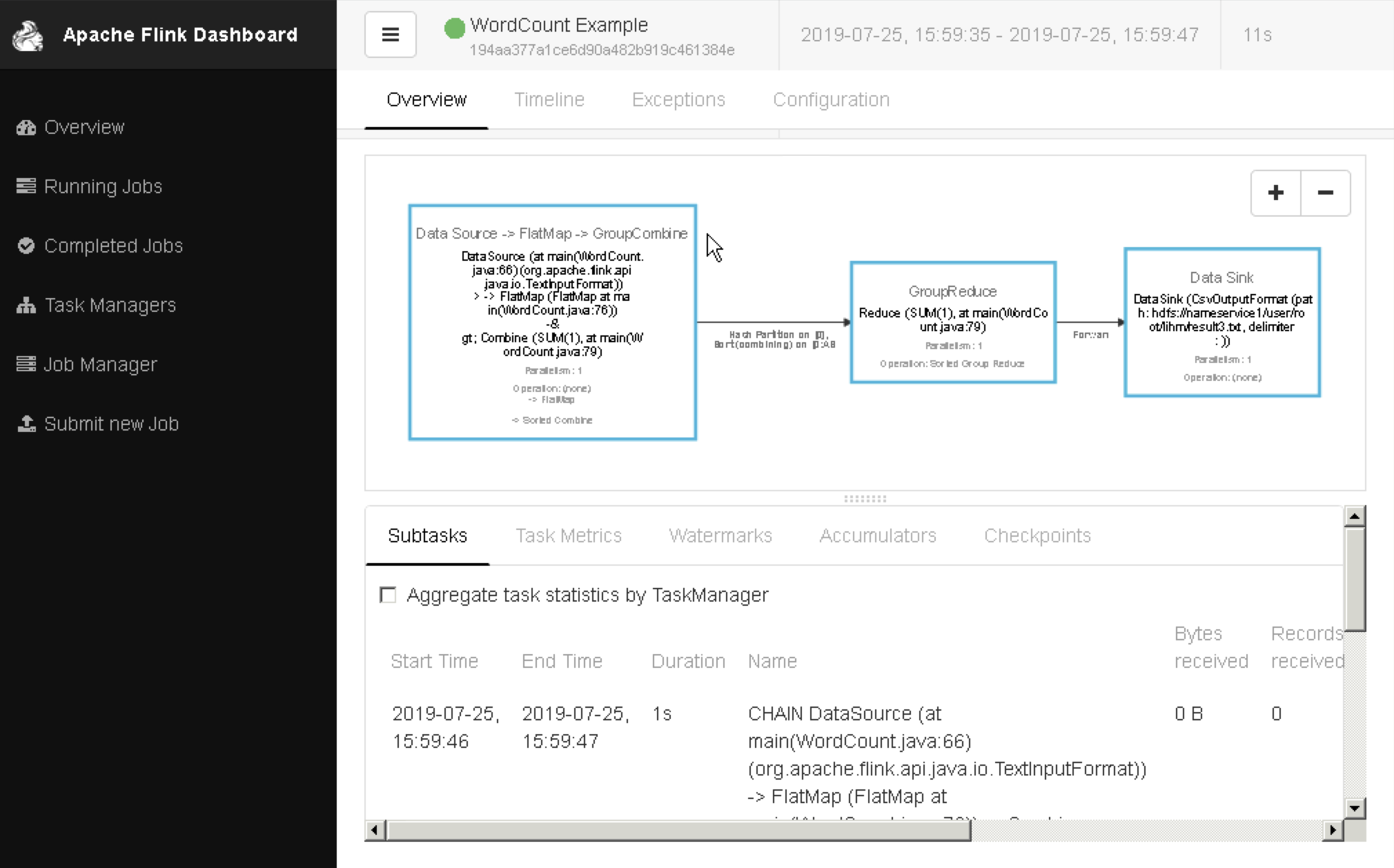
查看作业的详细
运行到指定的 yarn session
指定 yarn applicationID 来运行到特定的 yarn session
可以指定yid -yid,–yarnapplicationId
指定运行到 ID 为 application_1550579025929_62420 的yarn-session
1 | ./bin/flink run -yid application_1550579025929_62420 ./examples/batch/WordCount.jar --input hdfs://nameservice1/user/root/test/LICENSE --output hdfs://nameservice1/user/root/test/result4.txt |
run 方式
对于前面介绍的 yarn session 需要先启动一个集群,然后在提交作业。
对于Flink run 直接提交作业就相对比较简单,不需要额外的去启动一个集群,直接提交作业,即可完成 Flink 作业。
同样支持两种提交方式,默认不指定就是客户端方式
1 | # 客户端会多出来一个CliFrontend进程,就是驱动进程, 会在终端打印执行信息 |
需要使用分离方式提交的话。可以在提交作业的命令行中指定 -d 或者 –detached 进行分离提交。程序提交完毕退出客户端,
1 | # 程序提交完毕退出客户端,不在打印作业进度等信息! |
通过bin/flink run -help命令获取帮助。这里将不在解释
有时候 Yarn 集群是 jdk1.7 的,但是 Flink 得 1.8以上,这时需要在启动命令中指定 jdk1.8
1 | bin/flink run -m yarn-cluster -yn 2 -yjm 2048 -ytm 5120 \ |
总结
顺道提一下 slots 数的指定:
对于 standalone cluster 而言,由于一台机器上只有一个TaskManager,slots数应与机器核数相同。
对于 single job on yarn模式和 yarn cluster 模式而言,一台机器上可能有多个TaskManager(取决于yarn在该机器上分配的container数),理论上应该与该Container分配的核数一致为佳。
注意事项: 如果是平时的本地测试或者开发,可以采用yarn seesion, 如果是生产环境推荐使用 run 方式
参考链接