HBase 的 Rowkey 设计可以说是使用 HBase 最为重要的事情,直接影响到HBase的性能
前言
RowKey 到底是什么?
常说看一张 HBase 表设计的好不好,就看它的 RowKey 设计的好不好。可见 RowKey 在 HBase 中的地位。那么 RowKey 到底是什么?
RowKey 的特点如下:
类似于 MySQL、Oracle中的主键,用于标示唯一的行
完全是由用户指定的一串不重复的字符串
HBase 中的数据永远是根据 Rowkey 的字典排序来排序的
RowKey的作用
读写数据时通过 RowKey 找到对应的 Region
MemStore 中的数据按 RowKey 字典顺序排序
HFile 中的数据按 RowKey 字典顺序排序
Rowkey 对查询的影响
如果 RowKey 设计为 uid+phone+name
1 | # 那么这种设计可以很好的支持以下的场景 |
难以支持的场景可以做索引表来支持。二级索引,或者把索引存在ES中
Rowkey 对 Region 划分影响
HBase 表的数据是按照 Rowkey 来分散到不同 Region,不合理的 Rowkey 设计会导致热点问题。
热点问题是大量的 Client 直接访问集群的一个或极少数个节点,而集群中的其他节点却处于相对空闲状态。
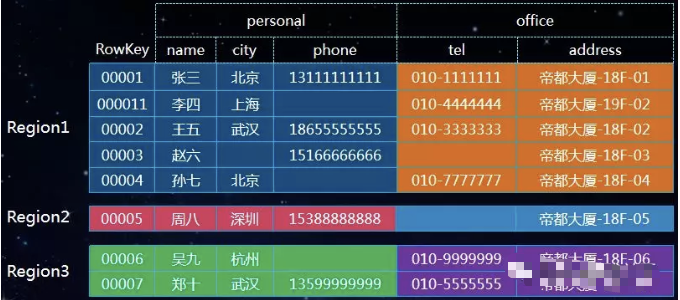
如上图,Region1 上的数据是 Region 2 的5倍,这样会导致 Region1 的访问频率比较高,进而影响这个 Region 所在机器的其他 Region。
Rowkey 原则
长度原则
Rowkey是一个二进制码流,最大长度为64KB(1024 * 64 = 65536字节,因为 row length 占2字节),Rowkey的长度被很多开发者建议说设计在10~100个字节,建议是越短越好,不要超过16个字节。
数据的持久化文件 HFile 中是按照 KeyValue 存储的,如果 Rowkey 过长比如100个字节,1000万列数据光 Rowkey 就要占用 100*1000万=10亿个字节,将近1G数据,这会极大影响 HFile 的存储效率;
MemStore将缓存部分数据到内存,如果 Rowkey 字段过长内存的有效利用率会降低,系统将无法缓存更多的数据,这会降低检索效率。因此 Rowkey 的字节长度越短越好。
目前操作系统是都是64位系统,内存8字节对齐。控制在16个字节,8字节的整数倍利用操作系统的最佳特性。
散列原则
HBase 中的行是按照 Rowkey 的字典顺序排序的,这种设计优化了 scan 操作,可以将相关的行以及会被一起读取的行存取在临近位置,便于scan。
然而糟糕的 Rowkey 设计是热点的源头。 热点发生在大量的 client 直接访问集群的一个或极少数个节点(访问可能是读,写或者其他操作)。
大量访问会使热点 Region 所在的单个机器超出自身承受能力,引起性能下降甚至 Region 不可用,这也会影响同一个 RS 上的其他 Region,
由于主机无法服务其他 Region 的请求。 设计良好的数据访问模式以使集群被充分,均衡的利用。
为了避免写热点,设计 Rowkey 使得数据应该被写入集群的多个 Region,而不是一个。
唯一原则
必须在设计上保证其唯一性。
rowkey是按照字典顺序排序存储的,因此,设计rowkey的时候,要充分利用这个排序的特点,将经常读取的数据存储到一块,将最近可能会被访问的数据放到一块。
RowKey 设计技巧
Salting(加盐)
在 Rowkey 的前面增加随机数,具体就是给 Rowkey 分配一个随机前缀以使得它和之前的 Rowkey 的开头不同。
分配的前缀种类数量应该和你想使用数据分散到不同的 Region 的数量一致。加盐之后的 Rowkey 就会根据随机生成的前缀分散到各个 Region 上,以避免热点。
假如你有下列 Rowkey,你表中每一个 Region 对应字母表中每一个字母。 以 ‘a’ 开头是同一个 Region, ‘b’开头的是同一个 Region。在表中,所有以 ‘f’开头的都在同一个 Region, 它们的 Rowkey 像下面这样
1 | foo0001 |
现在,假如你需要将上面这个 Rowkey 分散到 4个 Region。你可以用4个不同的盐:’a’, ‘b’, ‘c’, ‘d’.在这个方案下,每一个字母前缀都会在不同的 Region 中。
加盐之后,你有了下面的 Rowkey:
1 | a-foo0003 |
所以,你可以向4个不同的 Region 写,理论上说,如果所有人都向同一个 Region 写的话,你将拥有之前4倍的吞吐量。
现在,如果再增加一行,它将随机分配 a,b,c,d 中的一个作为前缀,并以一个现有行作为尾部结束:
1 | a-foo0003 |
因为分配是随机的,所以如果你想要以字典序取回数据,你需要做更多工作。加盐这种方式增加了写时的吞吐量,但是当读时有了额外代价。
Hashing(哈希)
Hashing 的原理是计算 Rowkey 的 hash 值,然后取 hash 的部分字符串和原来的 Rowkey 进行拼接。
因为哈希会使同一行永远用一个前缀加盐。因此哈希既可以让负载分散到整个集群,又可以让读可以预测。使用确定的哈希可以让客户端重构完整的rowkey,可以使用get操作准确获取某一个行数据。
这里说的 hash 包含 MD5、sha1、sha256或sha512等算法,常见的是使用MD5算法。
比如我们有如下的 RowKey:
1 | foo0001 |
使用 md5 计算这些 RowKey 的 hash 值,然后取前 6 位和原来的 RowKey 拼接得到新的 RowKey
1 | 95f18cfoo0001 |
优缺点: 可以一定程度打散整个数据集,但是不利于 Scan;比如我们使用 md5 算法,来计算Rowkey的md5值,然后截取前几位的字符串。subString(MD5(设备ID), 0, x) + 设备ID,其中x一般取5或6。
Reversing the Key(反转键)
第三种预防hotspotting的方法是反转一段固定长度或者可数的键,来让最常改变的部分(最低显著位, the least significant digit )在第一位,这样有效地打乱了行键,但是却牺牲了行排序的属性。
如果先导字段本身会带来热点问题,但该字段尾部的信息却具备良好的随机性。此时,可以考虑将先导字段做反转处理,将尾部几位直接提前到前面,或者直接将整个字段完全反转。
例如以手机号为rowkey,可以将手机号反转后的字符串作为rowkey,这样的就避免了以手机号那样比较固定开头导致热点问题。
比如我们有一下手机号,并作为RowKey
1 | 13400001111 |
完全反转
1 | 11110000431 |
有时候遇到后缀相同的,前缀随机,可我们需要把后缀相同的放在一起。所以可以考虑反转
比如我们有以下 URL ,并作为 RowKey
1 | flink.iteblog.com |
这些 URL 其实属于同一个域名,但是由于前面不一样,导致数据不在一起存放。我们可以对其进行反转,如下
1 | moc.golbeti.knilf |
经过这个之后,这些 URL 的数据就可以放一起了
RowKey 设计案例剖析
交易类表 Rowkey 设计
查询某个卖家某段时间内的交易记录
sellerId + timestamp + orderId
查询某个买家某段时间内的交易记录
buyerId + timestamp +orderId
根据订单号查询
orderNo
如果某个商家卖了很多商品,可以如下设计 Rowkey 实现快速搜索
salt + sellerId + timestamp 其中,salt 是随机数。
可以支持的场景:
全表 Scan
按照 sellerId 查询
按照 sellerId + timestamp 查询
金融风控 Rowkey 设计
查询某个用户的用户画像数据
prefix + uid
prefix + idcard
prefix + tele
其中 prefix = substr(md5(uid),0 ,x), x 取 5-6。uid、idcard以及 tele 分别表示用户唯一标识符、身份证、手机号码。
车联网 Rowkey 设计
查询某辆车在某个时间范围的交易记录
carId + timestamp
某批次的车太多,造成热点
prefix + carId + timestamp 其中 prefix = substr(md5(uid),0 ,x)
查询最近的数据
查询用户最新的操作记录或者查询用户某段时间的操作记录,RowKey 设计如下:
uid + Long.Max_Value - timestamp
支持的场景
查询用户最新的操作记录
Scan [uid] startRow [uid][000000000000] stopRow [uid][Long.Max_Value - timestamp]
查询用户某段时间的操作记录
Scan [uid] startRow [uid][Long.Max_Value – startTime] stopRow [uid][Long.Max_Value - endTime]
时间戳反转
尽量避免直接使用 time 作为 Rowkey。
如果有需求是快速获取数据的最近版本,使用反转的时间戳作为 Rowkey 的一部分对这个问题十分有用,可以用 Long.Max_Value - timestamp 追加到 key 的末尾,
例如 [key][reverse_timestamp] , [key] 的最新值可以通过scan [key]获得[key]的第一条记录,因为HBase中rowkey是有序的,第一条记录是最后录入的数据
总结
单单一张 HBase 数据表只能根据 Rowkey 来查询。多维度查询下是不够用的,
可以尝试二级索引。Phoenix、Solr 以及 ElasticSearch 都可以用于构建二级索引。

参考链接