Connector 的作用就相当于一个连接器,连接 Flink 计算引擎跟外界存储系统。
前言
Flink 是新一代流批统一的计算引擎,它需要从不同的第三方存储引擎中把数据读过来,进行处理,然后再写出到另外的存储引擎中。Connector 的作用就相当于一个连接器,连接 Flink 计算引擎跟外界存储系统。
Flink 里有以下几种方式,当然也不限于这几种方式可以跟外界进行数据交换
- Flink 里面预定义了一些 source 和 sink
- Flink 内部也提供了一些 Boundled connectors
- 使用第三方 Apache Bahir 项目中提供的连接器
- 通过异步 IO 方式
预定义的 source 和 sink
Flink 里预定义了一部分 source 和 sink。

基于文件的 source 和 sink
如果要从文本文件中读取数据,可以直接使用
1 | env.readTextFile(path) |
就可以以文本的形式读取该文件中的内容。当然也可以使用
1 | env.readFile(fileInputFormat, path) |
根据指定的 fileInputFormat 格式读取文件中的内容
如果数据在 Flink 内进行了一系列的计算,想把结果写出到文件里,也可以直接使用内部预定义的一些 sink,
比如将结果已文本或 csv 格式写出到文件中,可以使用 DataStream 的 writeAsText(path) 和
writeAsCsv(path)
基于 Socket 的 Source 和 Sink
提供 Socket 的 host name 及 port,可以直接用 StreamExecutionEnvironment 预定的接口
socketTextStream 创建基于 Socket 的 source,从该 socket 中以文本的形式读取数据。
当然如果想把结果写出到另外一个 Socket,也可以直接调用 DataStream writeToSocket。
基于内存 Collections、Iterators 的 Source
可以直接基于内存中的集合或者迭代器,调用 StreamExecutionEnvironment fromCollection、fromElements 构建相应的 source。结果数据也可以直接 print、printToError 的方式写出到标准输出或标准错误。
详细也可以参考 Flink 源码中提供的一些相对应的 Examples 来查看异常预定义 source 和 sink 的使用方法,例如 WordCount、SocketWindowWordCount。
Bundled Connectors
Flink 里已经提供了一些绑定的 Connector,例如 kafka source 和 sink,Es sink等。读写 kafka、es、rabbitMQ 时可以直接使用相应 connector 的 api 即可。第二部分会详细介绍生产环境中最常用的 kafka connector。
虽然该部分是 Flink 项目源代码里的一部分,但是真正意义上不算作 Flink 引擎相关逻辑,并且该部分没有打包在二进制的发布包里面。所以在提交 Job 时候需要注意, job 代码 jar 包中一定要将相应的 connetor 相关类打包进去,否则在提交作业时就会失败,提示找不到相应的类,或初始化某些类异常。

Apache Bahir 中的连接器
Apache Bahir 最初是从 Apache Spark 中独立出来项目提供,以提供不限于 Spark 相关的扩展/插件、连接器和其他可插入组件的实现。通过提供多样化的流连接器(streaming connectors)和 SQL 数据源扩展分析平台的覆盖面。如有需要写到 flume、redis 的需求的话,可以使用该项目提供的 connector。

Async I/O
流计算中经常需要与外部存储系统交互,比如需要关联 MySQL 中的某个表。一般来说,如果用同步 I/O 的方式,会造成系统中出现大的等待时间,影响吞吐和延迟。为了解决这个问题,异步 I/O 可以并发处理多个请求,提高吞吐,减少延迟。
Async 的原理可参考官方文档
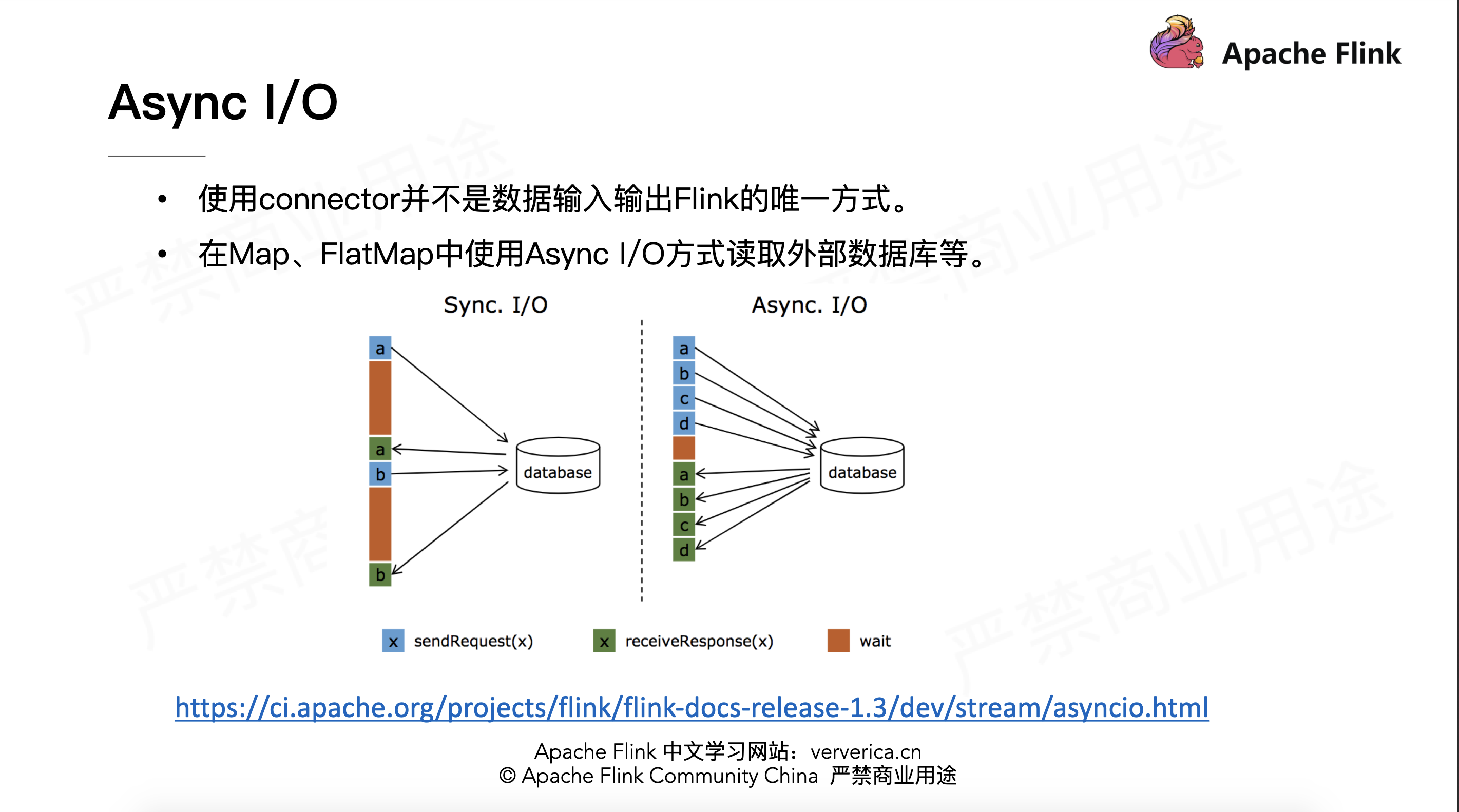
参考链接