生产环境中最常用到的 Flink kafka connector
前言
生产环境中最常用到的 Flink kafka connector
一是 Flink kafka Consumer,一个是 Flink kafka Producer。
首先看一个例子来串联下 Flink kafka connector。代码逻辑里主要是从 kafka 里读数据,然后做简单的处理,再写回到 kafka 中。
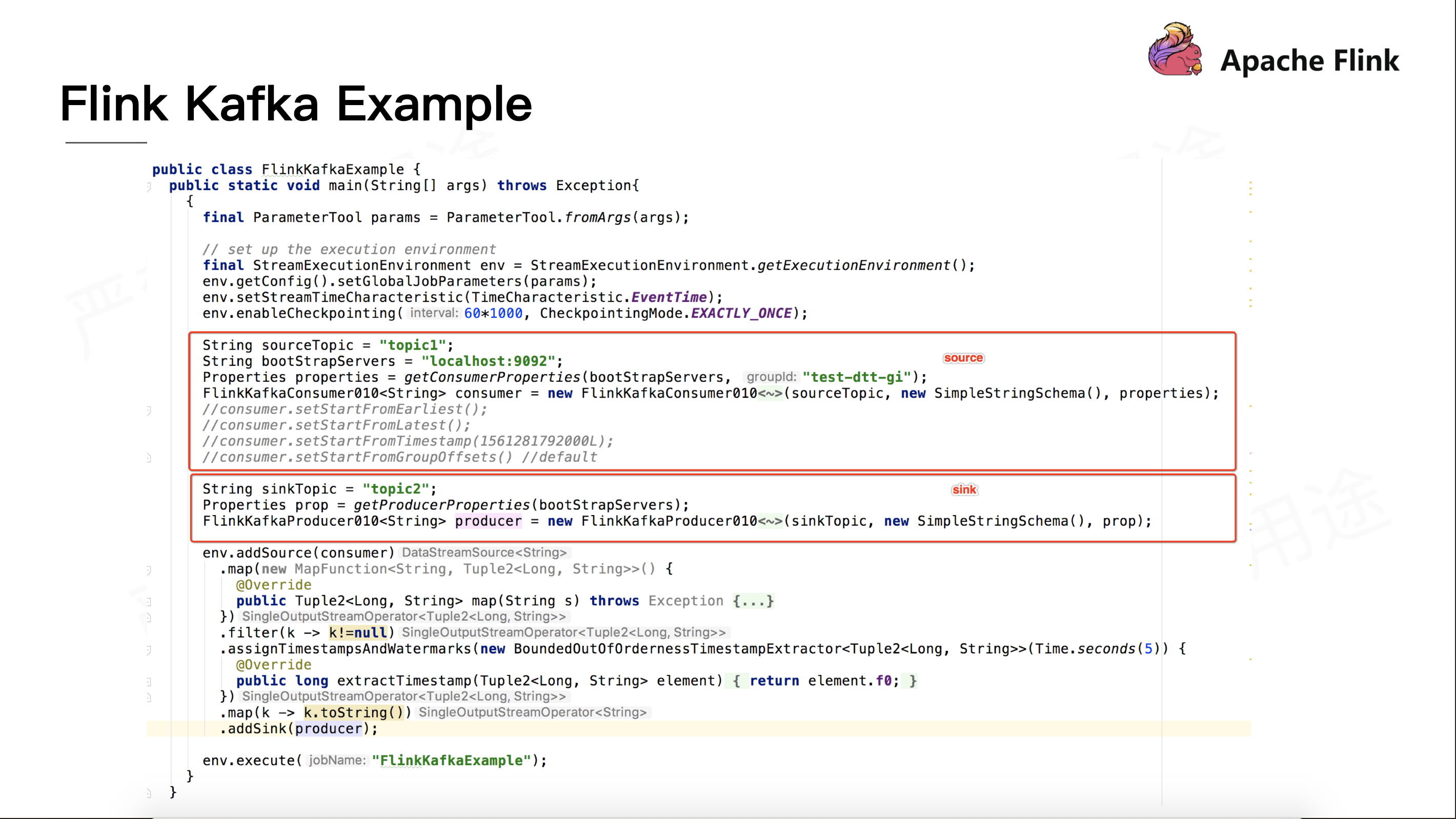
分别用红框框出如何构造一个 Source sink Function。Flink 提供了现成的构造FlinkKafkaConsumer、Producer 的接口,可以直接使用。这里需要注意,因为 kafka 有多个版本,多个版本之间的接口协议会不同。Flink 针对不同版本的 kafka 有相应的版本的 Consumer 和 Producer。例如:针对 08、09、10、11 版本,Flink 对应的 consumer 分别是 FlinkKafkaConsumer 08、09、010、011,producer 也是。
Consumer
反序列化数据
Kafka 中数据都是以二进制 byte 形式存储的。读到 Flink 系统中之后,需要将二进制数据转化为具体的 java、scala 对象。
具体需要实现一个 schema 类,定义如何序列化和反序列数据。
反序列化时需要实现 DeserializationSchema 接口,并重写 deserialize(byte[] message) 函数
如果是反序列化 kafka 中 kv 的数据时,需要实现 KeyedDeserializationSchema 接口,并重写 deserialize(byte[] messageKey, byte[] message, String topic, int partition, long offset) 函数。
如果想自己实现 Schema ,可以参看Apache-Flink深度解析-DataStream-Connectors之Kafka Simple ETL 部分
Flink 中也提供了一些常用的序列化反序列化的 schema 类。Flink-Kafka 内置 Schemas
例如,SimpleStringSchema,按字符串方式进行序列化、反序列化。
TypeInformationSerializationSchema,它可根据 Flink 的 TypeInformation 信息来推断出需要选择的 schema。
JsonDeserializationSchema 使用 jackson 反序列化 json 格式消息,并返回 ObjectNode,可以使用 .get(“property”) 方法来访问相应字段。
消费起始位置设置
设置作业从 kafka 消费数据最开始的起始位置,这一部分 Flink 也提供了非常好的封装。在构造好的 FlinkKafkaConsumer 类后面调用如下相应函数,设置合适的起始位置。
setStartFromGroupOffsets,也是默认的策略,
从 group offset 位置读取数据,group offset 指的是 kafka broker
端记录的某个 group 的最后一次的消费位置。但是 kafka broker 端没有该 group 信息,或者 group offset 无效的话,
将会根据 kafka 的参数”auto.offset.reset”的设置来决定从哪个位置开始消费,”auto.offset.reset” 默认为 largest。。setStartFromEarliest,从 kafka 最早的位置开始读取。
setStartFromLatest,从 kafka 最新的位置开始读取。
setStartFromTimestamp(long),从时间戳大于或等于指定时间戳的位置开始读取。Kafka 时戳,是指 kafka 为每条消息增加另一个时戳。该时戳可以表示消息在 proudcer 端生成时的时间、或进入到 kafka broker 时的时间。
setStartFromSpecificOffsets,从指定分区的 offset 位置开始读取,如指定的 offsets 中不存某个分区,该分区从 group offset 位置开始读取。此时需要用户给定一个具体的分区、offset 的集合。
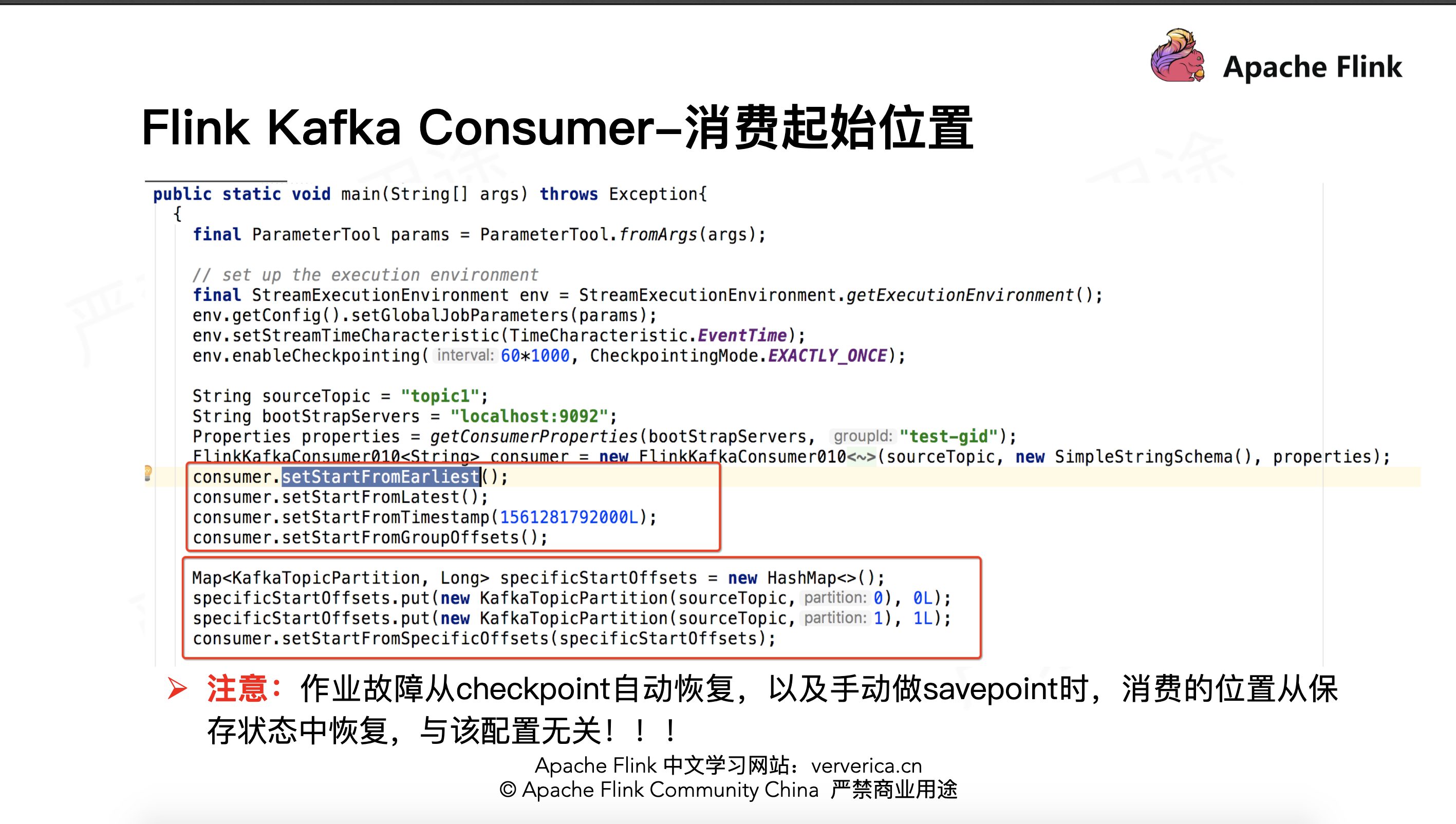
需要注意的是,因为 Flink 框架有容错机制,如果作业故障,如果作业开启 checkpoint,会从上一次 checkpoint 状态开始恢复。或者在停止作业的时候主动做 savepoint,启动作业时从 savepoint 开始恢复。这两种情况下恢复作业时,作业消费起始位置是从之前保存的状态中恢复,与上面提到跟 kafka 这些单独的配置无关。
如果该作业是从 checkpoint 或 savepoint 中恢复,则所有设置初始 offset 的函数均将失效,初始 offset 将从 checkpoint 中恢复。
topic 和 partition 动态发现
实际的生产环境中可能有这样一些需求,比如场景一,有一个 Flink 作业需要将五份数据聚合到一起,五份数据对应五个 kafka topic,随着业务增长,新增一类数据,同时新增了一个 kafka topic,如何在不重启作业的情况下作业自动感知新的 topic。场景二,作业从一个固定的 kafka topic 读数据,开始该 topic 有 10 个 partition,但随着业务的增长数据量变大,需要对 kafka partition 个数进行扩容,由 10 个扩容到 20。该情况下如何在不重启作业情况下动态感知新扩容的 partition?
针对上面的两种场景,首先需要在构建 FlinkKafkaConsumer 时的 properties 中设置 flink.partition-discovery.interval-millis 参数为非负值,表示开启动态发现的开关,以及设置的时间间隔。此时 FlinkKafkaConsumer 内部会启动一个单独的线程定期去 kafka 获取最新的 meta 信息。针对场景一,还需在构建 FlinkKafkaConsumer 时,topic 的描述可以传一个正则表达式描述的 pattern。每次获取最新 kafka meta 时获取正则匹配的最新 topic 列表。针对场景二,设置前面的动态发现参数,在定期获取 kafka 最新 meta 信息时会匹配新的 partition。为了保证数据的正确性,新发现的 partition 从最早的位置开始读取。

commit offset 方式
Flink kafka consumer commit offset 方式需要区分是否开启了 checkpoint。
如果 checkpoint 关闭,commit offset 要依赖于 kafka 客户端的 auto commit。需设置 enable.auto.commit,auto.commit.interval.ms 参数到 consumer properties,就会按固定的时间间隔定期 auto commit offset 到 kafka。
如果开启 checkpoint,这个时候作业消费的 offset 是 Flink 在 state 中自己管理和容错。此时提交 offset 到 kafka,一般都是作为外部进度的监控,想实时知道作业消费的位置和 lag 情况。此时需要 setCommitOffsetsOnCheckpoints 为 true 来设置当 checkpoint 成功时提交 offset 到 kafka。此时 commit offset 的间隔就取决于 checkpoint 的间隔,所以此时从 kafka 一侧看到的 lag 可能并非完全实时,如果 checkpoint 间隔比较长 lag 曲线可能会是一个锯齿状。

Timestamp Extraction/Watermark 生成
Flink 作业内使用 EventTime 属性时,需要指定从消息中提取时戳和生成水位的函数。
FlinkKakfaConsumer 构造的 source 后直接调用 assignTimestampsAndWatermarks 函数设置水位生成器的好处是此时是每个 partition 一个 watermark assigner
如下图。source 生成的时戳为多个 partition 时戳对齐后的最小时戳。此时在一个 source 读取多个 partition,并且 partition 之间数据时戳有一定差距的情况下,因为在 source 端 watermark 在 partition 级别有对齐,不会导致数据读取较慢 partition 数据丢失。
Q & A
在 Flink consumer 的并行度的设置:是对应 topic 的 partitions 个数吗?要是有多个主题数据源,并行度是设置成总体的 partitions 数吗?
这个并不是绝对的,跟 topic 的数据量也有关,如果数据量不大,也可以设置小于 partitions 个数的并发数。但不要设置并发数大于 partitions 总数,因为这种情况下某些并发因为分配不到 partition 导致没有数据处理。
如果 checkpoint 时间过长,offset 未提交到 kafka,此时节点宕机了,重启之后的重复消费如何保证呢?
首先开启 checkpoint 时 offset 是 Flink 通过状态 state 管理和恢复的,并不是从 kafka 的 offset 位置恢复。在 checkpoint 机制下,作业从最近一次 checkpoint 恢复,本身是会回放部分历史数据,导致部分数据重复消费,Flink 引擎仅保证计算状态的精准一次,要想做到端到端精准一次需要依赖一些幂等的存储系统或者事务操作。
参考链接