CMS(Concurrent Mark and Swee 并发-标记-清除)
前言
CMS(Concurrent Mark and Swee 并发-标记-清除) 是一款基于并发、使用标记清除算法的垃圾回收算法,只针对老年代进行垃圾回收。
CMS 主要适合场景是对响应时间的重要性需求大于对吞吐量的要求
CMS 收集器工作时,尽可能让GC线程和用户线程并发执行,以达到降低STW时间的目的
CMS 目标是尽量减少应用的暂停时间,减少full gc发生的几率,利用和应用程序线程并发的垃圾回收线程来标记清除年老代
使用场景
GC过程短暂停,适合对时延要求较高的服务,用户线程不允许长时间的停顿
缺点
服务长时间运行,造成严重的内存碎片化
名词解释
可达性分析算法
用于判断对象是否存活,基本思想是通过一系列称为“GC Root”的对象作为起点(常见的GC Root有系统类加载器、栈中的对象、处于激活状态的线程等),基于对象引用关系,从GC Roots开始向下搜索,所走过的路径称为引用链,当一个对象到GC Root没有任何引用链相连,证明对象不再存活
Stop The World
GC过程中分析对象引用关系,为了保证分析结果的准确性,需要通过停顿所有Java执行线程,保证引用关系不再动态变化,该停顿事件称为Stop The World(STW)
Safepoint
代码执行过程中的一些特殊位置,当线程执行到这些位置的时候,说明虚拟机当前的状态是安全的,如果有需要GC,线程可以在这个位置暂停。HotSpot采用主动中断的方式,让执行线程在运行期轮询是否需要暂停的标志,若需要则中断挂起
实现机制
CMS分为两种模式,background和foreground,background采用concurrent remark模式,可以和用户进程并行,而foreground则必须要stop the world(STW)。周期性的CMS采用的是background的方式,而主动的GC则采用foreground方式。
根据GC的触发机制分为:周期性Old GC(被动)和主动Old GC、个人理解,实在不知道怎么分才好。
Background Collect
周期性Old GC,执行的逻辑也叫Background Collect,对老年代进行回收,在GC日志中比较常见,由后台线程ConcurrentMarkSweepThread循环判断(默认2s)是否需要触发。
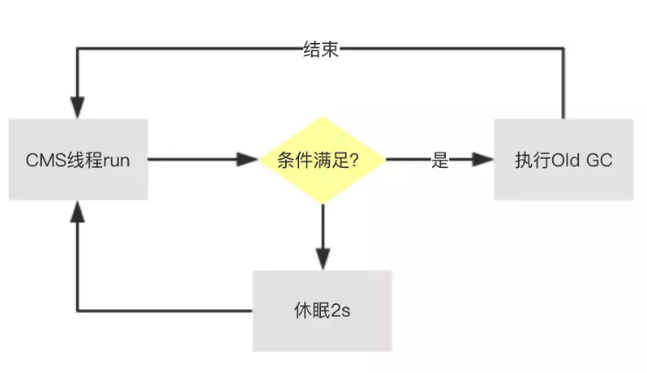
触发条件
如果没有设置-XX:+UseCMSInitiatingOccupancyOnly,虚拟机会根据收集的数据决定是否触发(建议线上环境带上这个参数,不然会加大问题排查的难度)
老年代使用率达到阈值 CMSInitiatingOccupancyFraction,默认92%
永久代的使用率达到阈值 CMSInitiatingPermOccupancyFraction,默认92%,前提是开启 CMSClassUnloadingEnabled
新生代的晋升担保失败(晋升担保失败触发Full GC)
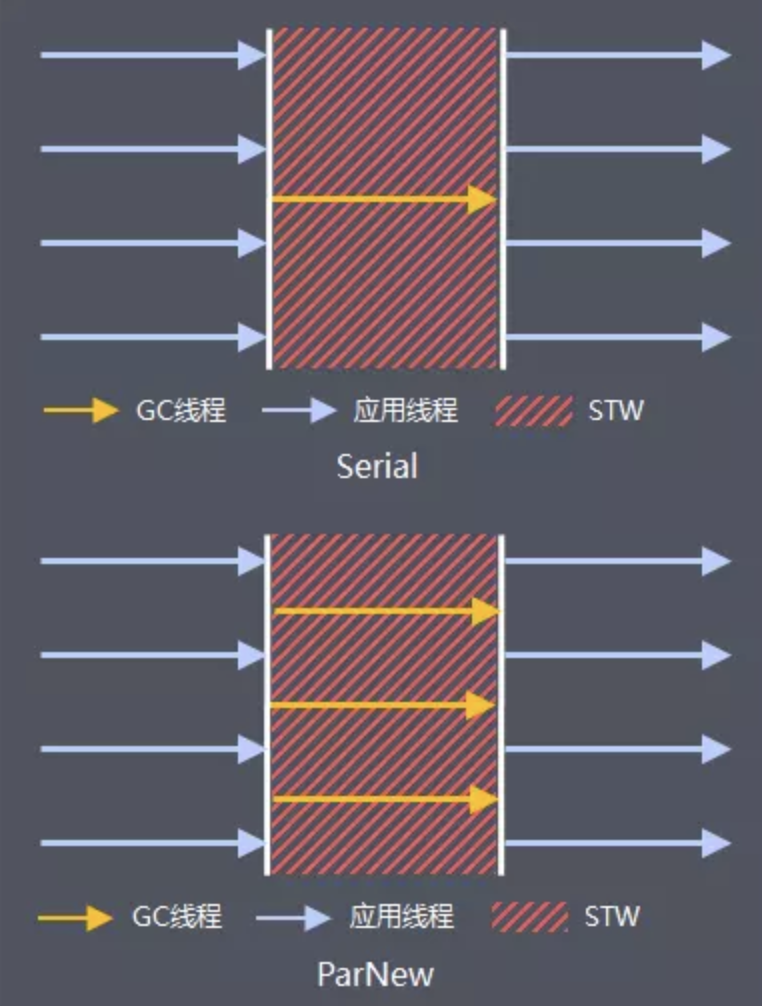
新生代垃圾回收
能与CMS搭配使用的新生代垃圾收集器有Serial收集器和ParNew收集器。这2个收集器都采用标记复制算法,都会触发STW事件,停止所有的应用线程。
不同之处在于,Serial是单线程执行,ParNew是多线程执行
老年代垃圾回收
GC 状态
当触发 cms gc 对老年代进行垃圾收集时,算法中会使用 _collectorState 变量记录执行状态,整个周期分成以下几个状态
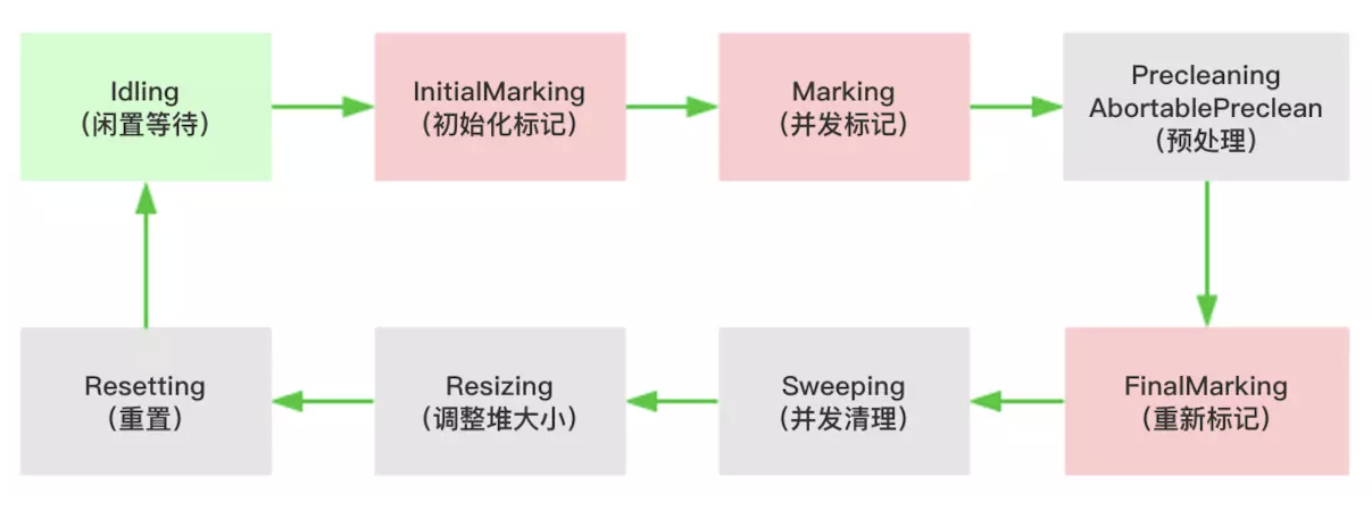
- Idling: 一次 cms gc 生命周期的初始化状态。
- InitialMarking: 根据 gc roots,标记出直接可达的活跃对象,这个过程需要stw的。
- Marking: 根据 InitialMarking 阶段标记出的活跃对象,并发迭代遍历所有的活跃对象,这个过程可以和用户线程并发执行。
- Precleaning: 并发预清理。
- AbortablePreclean: 因为某些原因终止预清理。
- FinalMarking: 由于marking阶段是和用户线程并发执行的,该过程中可能有用户线程修改某些活跃对象的字段,指向了一个非标记过的对象,在这个阶段需要重新标记出这些遗漏的对象,防止在下一阶段被清理掉,这个过程也是需要stw的。
- Sweeping: 并发清理掉未标记的对象。
- Resizing: 如果有需要,重新调整堆大小。
- Resetting: 重置数据,为下一次的 cms gc 做准备。
各阶段过程自行阅读:《图解CMS垃圾回收机制,你值得拥有》
Foreground Collect
主动的GC则采用foreground方式。这里有两种情况,是否进行 Compact,如果需要就执行 MSC 算法(即Serial Old或Parallel Old),否则就是 Foreground Collect
怎么理解上面那句话呢?往下看
主动GC开始时,需要判断本次GC是否要对老年代的空间进行Compact,即是否要压缩(因为长时间的周期性GC会造成大量的碎片空间)
判断逻辑实现如下
1 | *should_compact = |
在三种情况下会进行压缩:
其中参数UseCMSCompactAtFullCollection(默认true)和 CMSFullGCsBeforeCompaction(默认0),所以默认每次的主动GC都会对老年代的内存空间进行压缩,就是把对象移动到内存的最左边
执行了System.gc(),前提是没有参数ExplicitGCInvokesConcurrent,也会进行压缩
Young GC 过程中发生 promotion failure
带压缩动作的算法,称为MSC,标记-清理-压缩,采用单线程,全暂停的方式进行垃圾收集,暂停时间很长很长
那不带压缩动作的算法是什么样的呢?
不带压缩动作的执行逻辑叫Foreground Collect,整个过程相对周期性Old GC来说,少了 Precleaning 和 AbortablePreclean 两个阶段,其它过程都差不多。但是它整个过程都是STW的
最后从源码可以看出,除了达到一定次数之外,如果用户调用了System.gc()以及发生了promotion failed,也会进行一次压缩。同时也可以看出,foreground不一定会采用压缩,所以那些说foreground就是mark swap compact(msc)的是不对的。
MSC
MSC的全称是Mark Sweep Compact,即标记-清理-压缩,MSC是一种算法,请注意Compact,即它会压缩整理堆,这一点很重要。
MSC算法采用Serial Old或Parallel Old这些垃圾收集器,这些收集器采用标记-整理算法的GC方式
这是foreground CMS在特定情况下才会采用的一种垃圾回收算法。
这里讲一下
1 | -XX:+UseCMSCompactAtFullCollection |
配置-XX:+UseCMSCompactAtFullCollection(默认)前提下,如果CMSFullGCsBeforeCompaction=0,那么每次foreground CMS后都会采用MSC算法压缩堆内存;如果CMSFullGCsBeforeCompaction=3,那么每3次foreground CMS后才会有1次采用MSC算法压缩堆内存。
常见问题
最终标记阶段停顿时间过长问题
CMS的GC停顿时间约80%都在最终标记阶段(Final Remark),若该阶段停顿时间过长,常见原因是新生代对老年代的无效引用,在上一阶段的并发可取消预清理阶段中,执行阈值时间内未完成循环,来不及触发Young GC,清理这些无效引用
通过添加参数:-XX:+CMSScavengeBeforeRemark。在执行最终操作之前先触发Young GC,从而减少新生代对老年代的无效引用,降低最终标记阶段的停顿,但如果在上个阶段(并发可取消的预清理)已触发Young GC,也会重复触发Young GC
并发模式失败(concurrent mode failure) & 晋升失败(promotion failed)问题
如果触发了主动Old GC,这时周期性Old GC正在执行,那么会夺过周期性Old GC的执行权(同一个时刻只能有一种在Old GC在运行),并记录 concurrent mode failure 或者 concurrent mode interrupted


这两个图看得特别费力,最后还是弄懂了。应该是下面这个理解
promotion failed直接意思就是晋升到老年代,然而有时候会出现一些意外,导致对象晋升失败,这就是promotion failed。
什么情况下会发生晋升失败呢?从空间分配担保可以知道有两种情况:
- 是基于历史统计数据,比如统计数据显示历史上平均每次晋升对象的大小是av_promo,而当前老年代的空间并不足以存放av_promo大小的对象,则GC线程认为实际晋升的过程中可能会发生失败,晚失败不如早点失败,于是GC线程告诉堆发生了一次GC失败事件便终止了这次回收动作。
- 是历史统计数据显示这次老年代有足够的空间来支持对象晋升,但是 Minor GC 后,幸存空间容纳不了剩余对象(超过动态年龄的对象),将剩余对象要放入老年代,老年代有碎片或者不能容纳这些对象,所以对象晋升失败,于是GC线程同样会告诉堆发生了一次垃圾回收失败事件
发生 promotion failed 会有什么后果?就是紧接着触发concurrent mode failure,其意思为并发模式失败
concurrent mode failure在执行 CMS GC 的过程中预留的内存空间不足以保存对象,这会导致 Concurrent Mode Failure 失败,这时会启用 Serial Old 收集器来重新进行老年代的收集。为什么CMS GC会有对象进入老年代?
因为存在可能业务线程会将大对象放入老年代,而此时老年代空间不足;或者 promotion failed 导致的对象晋升,而此时老年代空间不足或老年代空间足够,但存在大量碎片。
当出现concurrent mode failure的现象时,就意味着此时JVM将继续采用 Stop-The-World 的方式来进行 Full GC,Full GC 会启用 Serial Old 收集器, Serial Old 收集器是单线程收集器,这样就会导致 STW 更长
concurrent mode interrupted 是由于外部因素触发了 full gc,比如执行了System.gc()
并发模式失败和晋升失败都会导致长时间的停顿,常见解决思路如下
- 降低触发CMS GC的阈值,即参数-XX:CMSInitiatingOccupancyFraction的值,让CMS GC尽早执行,以保证有足够的空间
- 增加CMS线程数,即参数-XX:ConcGCThreads,
- 增大老年代空间
- 让对象尽量在新生代回收,避免进入老年代
内存碎片问题
通常CMS的GC过程基于标记清除算法,不带压缩动作,导致越来越多的内存碎片需要压缩
可通过参数CMSFullGCsBeforeCompaction的值,设置多少次foreground CMS触发一次MSC
思考
周期性的CMS(background)只会回收老年代,除了周期性的进行GC之外,还有一些紧急情况,需要主动触发GC(foreground),主动触发的GC会连带一次Minor GC,所以也称为Full GC。主动触发的GC是会暂停所有用户现场的,俗称stop the world(STW)。
在那些没有实现CMS的老虚拟机或者没有开启CMS的虚拟机中,每一次Old GC都是Full GC,且会STW,当然因为除了CMS之外,其他的老年代回收算法都是采用标记-整理的方式,所以肯定也是压缩的,。
如果正在进行CMS回收,又触发了一次Full GC,则Full GC会抢占回收执行机会,停止CMS,采用Serial Old或Parallel Old这些采用标记-整理算法的GC方式(CMS采用的是标记-清理算法)进行Full GC
在 JDK 9 中 CMS GC 被废弃后,现有应用程序的最佳处理方法是什么?感兴趣可以参阅CMS 被废弃了,该怎么办呢?
参考链接