快速采集 hdfs-audit 分析并进行展示监控
前言
本文主要是基于小火牛的《如何快速采集分析平台日志,并进行展示监控?》
HDFS 存在某业务导致NameNode RPC通信频繁,希望通过 ELK 快速分析 NameNode RPC 操作并对接 Grafana 展示
安装
ELK 这里使用是 7.5 版本,Kafka 使用是 CDH6.3 自带的,grafana 使用是 6.5
FileBeat、Kafka 搭建过程网上也很多,可以参考下我之前写的
贴一下 filebeat.yml 的配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/hadoop-hdfs/hdfs-audit.log
harvester_buffer_size: 32768
scan_frequency: 1s
backoff: 10ms
# backoff <= max_backoff <= scan_frequency
processors:
- drop_fields: # 删除字段,不再kibana里面展示,默认情况kibana里面会自动展示这些beat字段, 前缀带@符号的好像删不掉
fields: ["input", "ecs", "agent", "host", "log"]
output.kafka:
enabled: true
hosts: ["xxxx:9092"]
topic: hdfsAudit
required_acks: 1 # ACK的可靠等级.0=无响应,1=等待本地消息,-1=等待所有副本提交.默认1
keep_alive: 10s # 连接的存活时间.如果为0,表示短连,发送完就关闭.默认为0秒
logging.level: error # 最低日志级别,建议在开发时期开启日志并把日志调整为debug或者info级别,在生产环境下调整为error级别
name: xxxx
|
Elasticsearch、Kibana 搭建过程网上很多,本人参考自下方链接
遇到的坑
- 需要普通用户启动,解压后目录最好放在普通用户家目录下,别放在 root 家目录
elasticsearch.yml 中 cluster.initial_master_nodes 参数填的内容是 node.name 参数的值
logstash 搭建过程网上很多,这里是直接解压到 root 家目录下
在 config 目录下新增一个 kafka.conf
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| input {
kafka {
bootstrap_servers => "xxxx:9092"
topics => ["hdfsAudit"]
group_id => "logstash"
}
}
filter {
mutate {
rename => ["message", "fileMessage"]
}
json {
source => "fileMessage"
}
grok {
match => {
"message" => "(?<logd>(%{YEAR}[./-]%{MONTHNUM}[./-]%{MONTHDAY})) %{TIME:logt} %{LOGLEVEL:level}%{GREEDYDATA}ugi=(?<ugi>([\w]*)/?)%{GREEDYDATA}ip=/%{IPV4:ip}%{GREEDYDATA}cmd=(?<cmd>([\w]*)/?)%{GREEDYDATA}src=(?<src>([\w/._-]*)/?)%{GREEDYDATA}dst=%{GREEDYDATA}"
}
add_field => {
"logdate" => "%{logd} %{logt}"
}
remove_field => ["fileMessage", "logt", "logd", "message"]
}
date {
match => [ "logdate","ISO8601" ]
target => "@times"
remove_field => ['logdate']
}
}
output {
stdout {
codec => rubydebug
}
elasticsearch {
index => "logstash-hdfs-auit-%{+YYYY.MM.dd}"
hosts => ["xxxx:9200"]
}
}
|
这里我一开始使用小火牛推荐的dissect来解析,遇到各种问题,实在能力不够解决不了,就用回grok了
使用 bin/logstash -f config/kafka.conf 启动后观察是否有报错,或者解析不成功的。可行后就使用 nohup 后台启动
Grafana 安装网上很多,官网也有说明
Logstash、Elasticsearch、Kibana 最好找一台机器部署,因为很吃资源,尽量别影响到集群
展示
Grafana 配置 NameNode RPC 操作
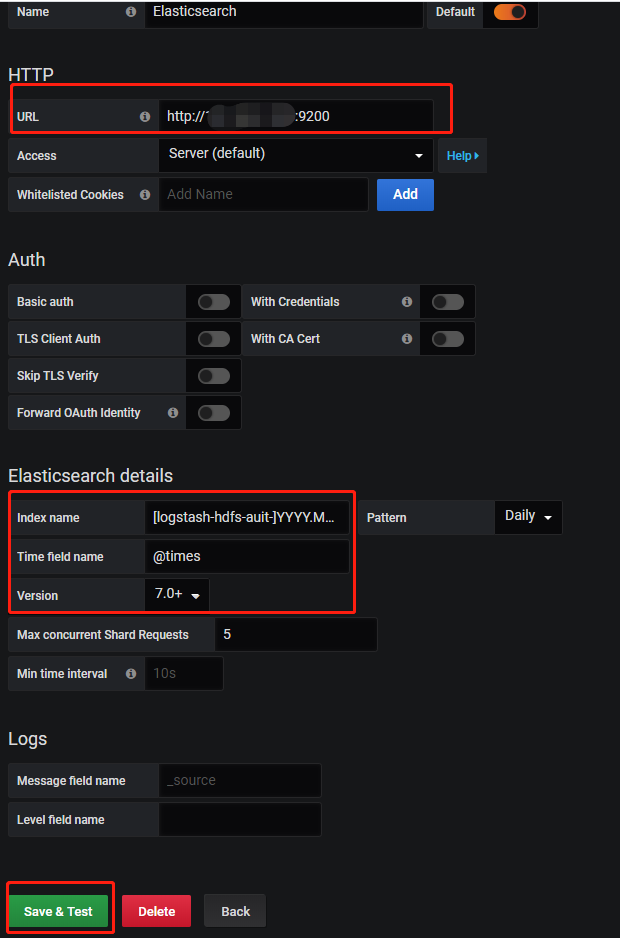
然后创建Dashboard依次配置以下几种查询展示
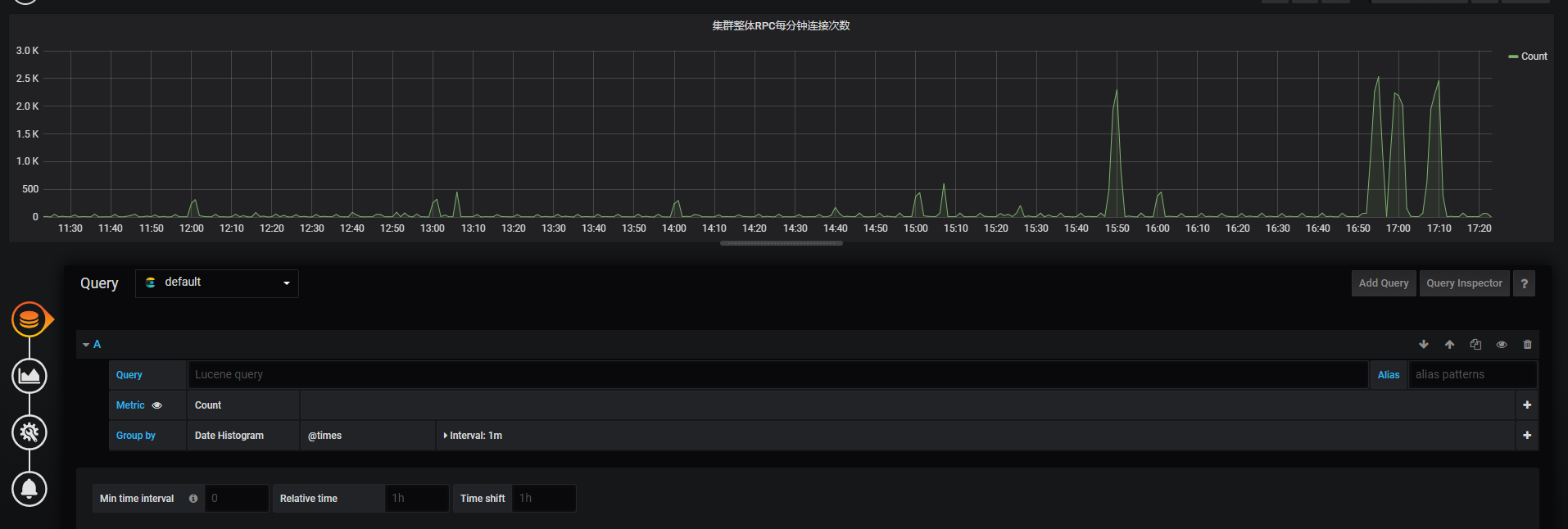
集群整体RPC每分钟连接次数
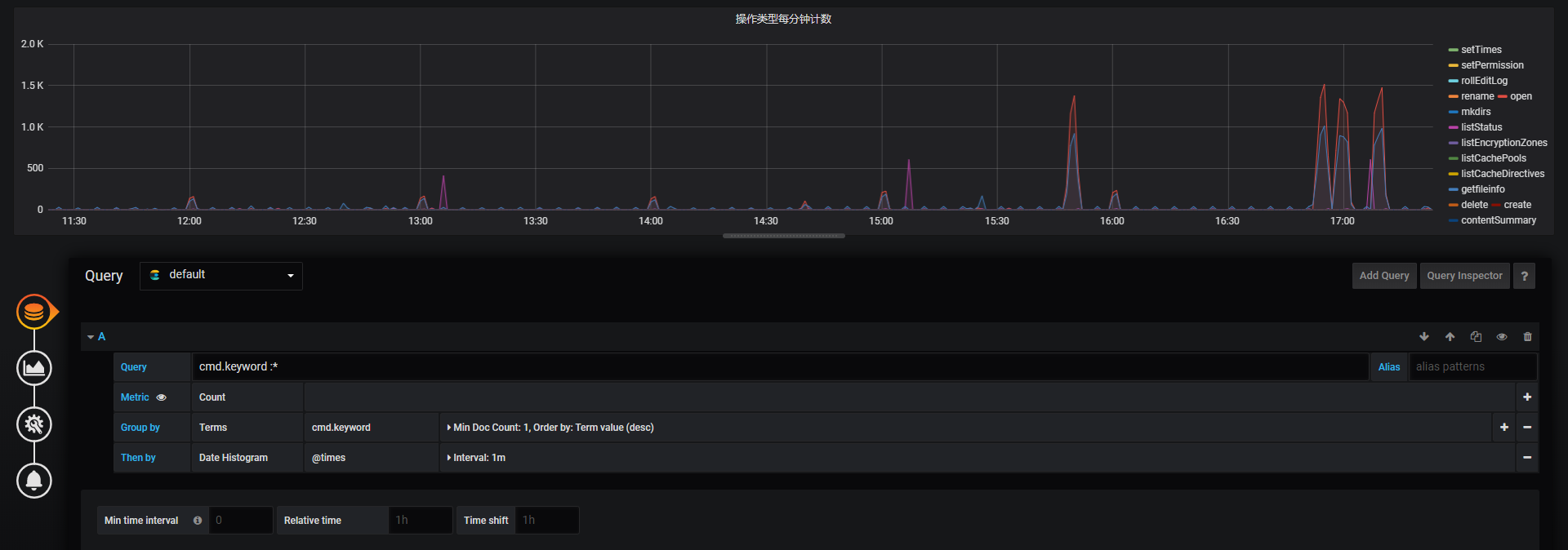
操作类型每分钟计数
每分钟操作类型排行前五
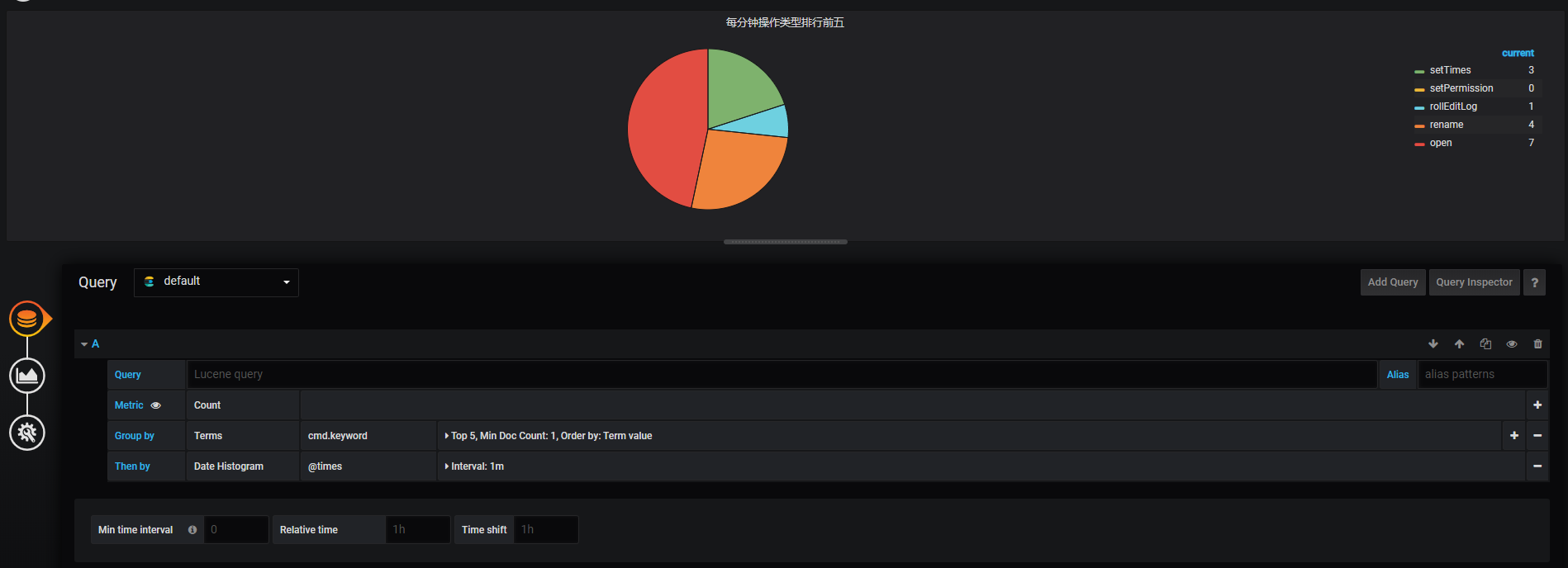
饼图配置可是折腾了我一会,原来还需要安装插件,语法还不会写,orz
Grafana 默认版本中没有饼图插件,需要自行安装,安装使用参考下方
总结
这一次是采坑花了时间精力去折腾的,整出来后还是有些成就感的
RPC的监控只是监控大数据平台的一个指标,路还很长,再接再厉
参考链接