CDH 从图表生成器添加图表
前言
在分布式系统中脑裂又称为双主现象,由于网络问题可能会导致出现两个 NameNode 同时为 Active 状态,此时两个 NameNode 都可以对外提供服务,无法保证数据一致性。ActiveStandbyElector 通过 Fencing 机制防止脑裂现象。
机制
当某个 NameNode 竞选成功,成功创建 ActiveStandbyElectorLock 临时节点后会创建另一个名为 ActiveBreadCrumb 的持久节点,该节点保存了 NameNode 的地址信息,正常情况下删除 ActiveStandbyElectorLock 节点时会主动删除 ActiveBreadCrumb,但如果由于异常情况导致 Zookeeper Session关闭,此时临时节点 ActiveStandbyElectorLock 会被删除,但持久节点 ActiveBreadCrumb 并不会删除,当有新的 NameNode 竞选成功后它会发现已经存在一个旧的 NameNode 遗留下来的 ActiveBreadCrumb 节点,此时会通知 ZKFC 对旧的 ANN 进行 fencing,
在进行 fencing 的时候,会执行以下的操作:
- 首先尝试调用这个旧 Active NameNode 的 HAServiceProtocol RPC 接口的 transitionToStandby 方法,看能不能把它转换为 Standby 状态。
- 如果 transitionToStandby 方法调用失败,那么就执行 Hadoop 配置文件之中预定义的隔离措施,Hadoop 目前主要提供两种隔离措施,通常会选择 sshfence:
- sshfence: 通过 SSH 登录到目标机器上,执行命令 fuser 将对应的进程杀死;
- shellfence: 执行一个用户自定义的 shell 脚本来将对应的进程隔离;
具体如何使用可以参阅Hadoop NameNode HA fencing
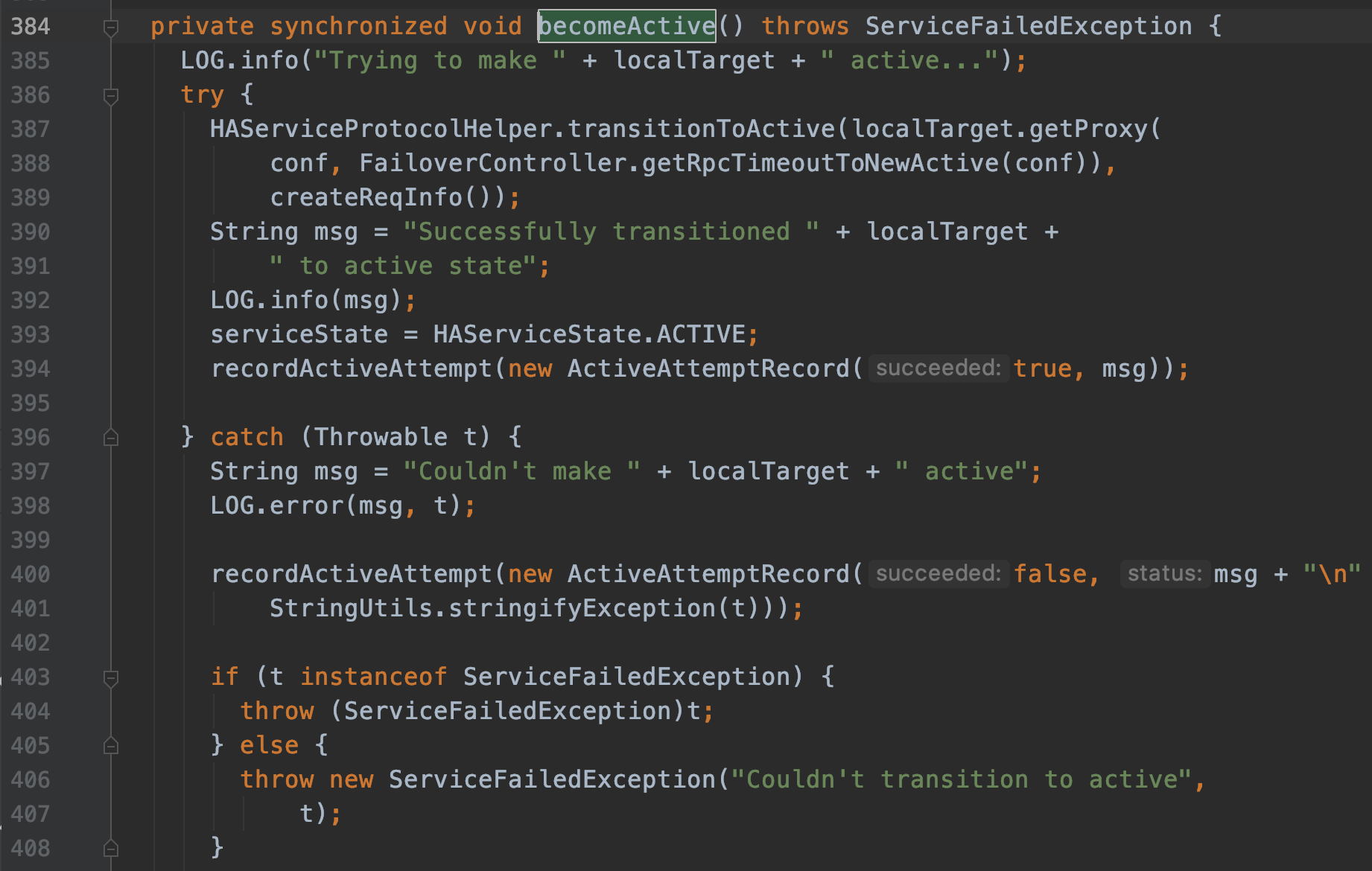
只有在成功地执行完成 fencing 之后,选主成功的 ActiveStandbyElector 才会回调 ZKFailoverController 的 becomeActive 方法将对应的 NameNode 转换为 Active 状态,开始对外提供服务

JournalNode 方面
同一时刻只有一个 NameNode 可以写入 QJM, 这样就不担心脑裂问题。
Epoch 是一个单调递增的整数,用来标识每一次 Active NameNode 的生命周期,每发生一次 NameNode 的主备切换,Epoch 就会加 1。这实际上是一种 fencing 机制。
Epoch 的过程完全类似:
- Active NameNode 首先向 JournalNode 集群发送 getJournalState RPC 请求,每个 JournalNode 会返回自己保存的最近的那个 Epoch(代码中叫 lastPromisedEpoch)。
- NameNode 收到大多数的 JournalNode 返回的 Epoch 之后,在其中选择最大的一个加 1 作为当前的新 Epoch,然后向各个 JournalNode 发送 newEpoch RPC 请求,把这个新的 Epoch 发给各个 JournalNode。
- 每一个 JournalNode 在收到新的 Epoch 之后,首先检查这个新的 Epoch 是否比它本地保存的 lastPromisedEpoch 大,如果大的话就把 lastPromisedEpoch 更新为这个新的 Epoch,并且向 NameNode 返回它自己的本地磁盘上最新的一个 EditLogSegment 的起始事务 id,为后面的数据恢复过程做好准备。如果小于或等于的话就向 NameNode 返回错误。
- NameNode 收到大多数 JournalNode 对 newEpoch 的成功响应之后,就会认为生成新的 Epoch 成功
在生成新的 Epoch 之后,每次 NameNode 在向 JournalNode 集群提交 EditLog 的时候,都会把这个 Epoch 作为参数传递过去。每个 JournalNode 会比较传过来的 Epoch 和它自己保存的 lastPromisedEpoch 的大小,如果传过来的 epoch 的值比它自己保存的 lastPromisedEpoch 小的话,那么这次写相关操作会被拒绝。一旦大多数 JournalNode 都拒绝了这次写操作,那么这次写操作就失败了。如果原来的 Active NameNode 恢复正常之后再向 JournalNode 写 EditLog,那么因为它的 Epoch 肯定比新生成的 Epoch 小,并且大多数的 JournalNode 都接受了这个新生成的 Epoch,所以拒绝写入的 JournalNode 数目至少是大多数,这样原来的 Active NameNode 写 EditLog 就肯定会失败,失败之后这个 NameNode 进程会直接退出,这样就实现了对原来的 Active NameNode 的隔离了。
参考链接