Linux 运维知识练习
Linux 理论部分
进程管理
进程和线程有什么区别
线程是CPU调度的基本单位,而进程则是资源拥有的基本单位
进程有哪些状态
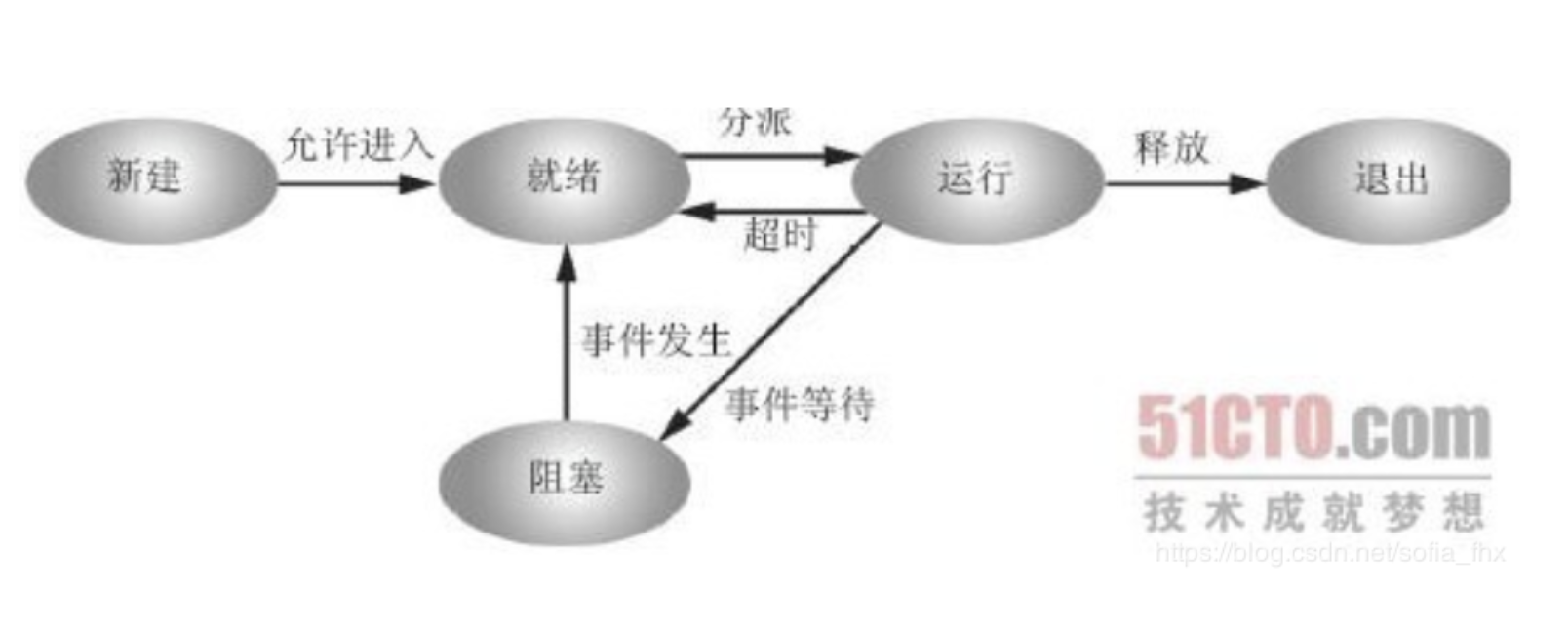
1.创建状态
进程由创建而产生。创建进程是一个非常复杂的过程,一般需要通过多个步骤才能完成:如首先由进程申请一个空白的进程控制块(PCB),并向PCB中填写用于控制和管理进程的信息;然后为该进程分配运行时所必须的资源;最后,把该进程转入就绪状态并插入到就绪队列中。
2.就绪状态
这是指进程已经准备好运行的状态,即进程已分配到除CPU以外所有的必要资源后,只要再获得CPU,便可立即执行。如果系统中有许多处于就绪状态的进程,通常将它们按照一定的策略排成一个队列,该队列称为就绪队列。有执行资格,没有执行权的进程。
3.运行状态
这里指进程已经获取CPU,其进程处于正在执行的状态。对任何一个时刻而言,在单处理机的系统中,只有一个进程处于执行状态而在多处理机系统中,有多个进程处于执行状态。既有执行资格,又有执行权的进程。
4.阻塞状态
这里是指正在执行的进程由于发生某事件(如I/O请求、申请缓冲区失败等)暂时无法继续执行的状态,即进程执行受到阻塞。此时引起进程调度,操作系统把处理机分配给另外一个就绪的进程,而让受阻的进程处于暂停的状态,一般将这个暂停状态称为阻塞状态
5.终止状态
进程的终止也要通过两个步骤:首先,是等待操作系统进行善后处理,最后将其PCB清零,并将PCB空间返还给系统。当一个进程到达了自然结束点,或是出现了无法克服的错误,或是被操作系统所终结,或是被其他有终止权的进程所终结,它将进入终止状态。进入终止态的进程以后不能在再执行,但是操作系统中任然保留了一个记录,其中保存状态码和一些计时统计数据,供其他进程进行收集。一旦其他进程完成了对其信息的提取之后,操作系统将删除其进程,即将其PCB清零,并将该空白的PCB返回给系统。
为什么要分开就绪和阻塞状态
答:因为就绪态只需要等待处理机,而阻塞态可能在等待输入输出,即使分配给处理机也是徒劳,所以两状态图不妥。对于调度进程,只需要等待就绪队列里的进程,因为阻塞状态可以转换到就绪队列里去。
什么是僵尸进程
一个进程使用fork()创建子进程,如果子进程退出,而父进程并没有调用wait()或waitpid()获取子进程的状态信息,那么子进程的某些信息如进程描述符仍然保存在系统中,这种进程称之为僵尸进程
查看僵尸进程,利用命令ps,可以看到有标记为Z(zombie)的进程就是僵尸进程
1 | # 查看进程的状态的 |
僵尸进程产生的原因
- 子进程结束后向父进程发出SIGCHLD信号,父进程默认忽略了它
- 父进程没有调用wait()或waitpid()函数来等待子进程的结束
- 网络原因有时会引起僵尸进程
如果出现大量的僵尸进程会有哪些危害
僵尸进程会在系统中保留其某些信息如进程描述符、进程id等等。以进程id为例,系统中可用的进程id是有限的,如果由于系统中大量的僵尸进程占用进程id,就会导致因为没有可用的进程id系统不能产生新的进程,这种问题可就大了,这就是僵尸进程来的危害,因此大部分情况下,我们都应当避免僵尸进程的产生。
总而言之,僵尸进程会占用系统资源,如果很多,则会严重影响服务器的性能,最大的危害就是内存泄露
如何杀死僵尸进程
僵尸进程用kill命令是无法杀掉的,但是我们可以结果掉僵尸进程的父进程(如果其父进程不需要的话);父进程挂了之后,僵尸进程就成了孤儿进程,孤儿进程不会占用系统资源,会被init程序收养,然后init程序将其回收
1 | # 查看僵尸进程的父进程 |
一台服务器上产生了100多少僵死进程,而且每一僵死进程的父进程都不一样,如果用上面的方法,一条一条的杀会挺麻烦的。
一条命令直接查找僵死进程,然后将父进程杀死
ps -A -o stat,ppid,pid,cmd | grep -e "^[Zz]" | awk '{print $2}' | xargs kill -9
描述进程间通信有哪些⽅方法
进程间通信(IPC,Interprocess communication)是一组编程接口,让程序员能够协调不同的进程,使之能在一个操作系统里同时运行,并相互传递、交换信息。
- 管道: 管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系
- 有名管道: 有名管道也是半双工的通信方式,但是它允许无亲缘关系进程之间的通信
- 消息队列: 消息队列是消息的链表,存放在内核中并由消息队列表示符标示。消息队列克服了信号传递信息少,管道只能承载无格式字节流以及缓冲区大小受限制等缺点
- 共享内存: 共享内存就是映射一段能被其它进程所访问的内存,共享内存由一个进程创建,但是多个进程都可以访问。共享内存是最快的IPC,往往与其它通信机制配合使用,来实现进程间的同步和通信
- 信号量: 信号量是一个计数器,可以用来控制多个进程对共享资源的访问,它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。主要作为进程间以及同一进程内不同线程之间的同步手段
- socket: 套接字也是进程间的通信机制,与其它通信机制不同的是,它可以用于不同机器间的进程通信
- 信号: 信号是一种比较复杂的通信方式,用于通知接受进程某个时间已经发生
什么是 Unix 信号
信号是一种中断,是一种处理异步事件的方法
1 | # 用 kill -l 命令可以察看系统定义的信号列表 |
具体含义请转自Unix系统中常用的信号含义
SIGKILL用来立即结束程序的运行,该信号不能被阻塞、捕获和忽略
当你对⼀个进程发送 一个 HUP 信号,但是没有任何作⽤,分析原因
先解释下 HUP 信号, 全名叫hangup,表示终端断线
当用户注销(logout)或者网络断开时,终端会收到Linux HUP信号(hangup)信号从而关闭其所有子进程
当用户退出Linux登录时,前台进程组和后台有对终端输出的进程将会收到SIGHUP信号。这个信号的默认操作为终止进程,因此前台进程组和后台有终端输出的进程就会中止,不过可以捕获这个信号,比如wget能捕获SIGHUP信号,并忽略它,这样就算退出了Linux登录,wget也能继续下载。
没有任何作⽤有两种可能
- 进程忽略Linux HUP信号
- 进程运行在新的会话里从而成为不属于此终端的子进程
发送 HUP 信号(即意外终止信号)到运行进程 ID 为 1001 的程序
1 | $ kill -9 1001 |
请简述nohup命令的原理
nohup 命令运行指定的命令,忽略所有挂断(SIGHUP)信号,在注销后使用 nohup 命令运行后台中的程序
nohup 命令会从终端解除进程的关联,进程会丢掉STDOUT,STDERR的链接。标准输出和标准错误缺省会被重定向到 nohup.out 文件中。一般我们可在结尾加上”&”来将命令同时放入后台运行,也可用”>filename 2>&1”来更改缺省的重定向文件名,”>filename 2>&1”意思是把标准错误(2)重定向到标准输出中(1),而标准输出又导入文件filename里面,所以结果是标准错误和标准输出都导入文件filename里面了
使用&后台运行程序:
- 结果会输出到终端
- 使用Ctrl + C发送SIGINT信号,程序免疫
- 关闭session发送SIGHUP信号,程序关闭
使用nohup运行程序:
- 结果默认会输出到nohup.out
- 使用Ctrl + C发送SIGINT信号,程序关闭
- 关闭session发送SIGHUP信号,程序免疫
平日线上经常使用nohup和&配合来启动程序:
- 同时免疫SIGINT和SIGHUP信号
如何在bash脚本中处理用户的Ctrl-C
可以使用Bash提供的trap命令捕获中断信号
trap的用法如下:
1 | trap [-lp] [[arg] signal_spec ...] |
-l: 列出所有信号的序号及名称-p: 列出特定信号对应的处理指令arg: 是signal_spec指定的信号的处理指令signal_spec: 是需要捕获的信号
执行下方脚本,Ctrl+C按键将触发onCtrlC函数
1 | !/bin/bash |
如果用户中断程序的运行,这个 trap 将会被执行,可以确保onCtrlC方法被执行。onCtrlC 后面的这个 exit 命令,它的存在是必要的。如果没有它,程序会在它中断点(也就是信号接收的时刻)继续执行
bashrc和环境变量
shell 按照登录类型和交互类型分类,总共有哪⼏类,在各个类别中⾄少举出⼀个例子
登录shell和非登陆shell
- 登录shell: 需要用户名、密码登录后才能进入的shell(或者以–login选项启动的shell,实际上不是真的存在哪个用户来登录)
- 非登录shell: 不需要输入用户名和密码即可打开的Shell(直接bash命令就是打开一个新的非登录shell,在Gnome或KDE中打开一个“终端”(terminal)窗口程序也是一个非登录shell)
退出一个登录shell: exit或者logout
退出一个非登录shell: 只能exit
登录shell 时,其bash进程名为”-bash”
非登陆shell时,bash进程名为”bash”
1 | (base) [root@iZbp144crtihiqovt4h5m4Z ~]# su - lihm |
交互式shell和非交互式shell
- 交互式模式: 在终端上执行,shell等待你的输入,并且立即执行你提交的命令
- 非交互式模式: 以shell script(非交互)方式执行。在这种模式 下,shell不与你进行交互,而是读取存放在文件中的命令,并且执行它们。当它读到文件的结尾EOF,shell也就终止
上述各个类别的 bash 系统配置文件和个⼈配置⽂件分别是什么,加载顺序是怎样的
交互式登录shell:
/etc/profile-> (~/.bash_profile|~/.bash_login|~/.profile) ->(~/.bashrc->/etc/bashrc) ->~/.bash_logout(~/.bash_profile | ~/.bash_login | ~/.profile) 中读取第一个存在而且可读的文件并且执行其中的命令,可以在shell启动时使用–noprofile选项来禁止这种行为
是以登录shell注销的,Bash会读取并执行文件~/.bash_logout和/etc/bash.bash_logout中的命令,假如文件存在的话
交互式非登陆shell:
~/.bashrc->/etc/bashrc
一般建议将配置直接添加在
~/.bashrc中,这样不管是登录式Shell还是 非登录式Shell都可以读到
$PS1这个环境变量有什么⽤
是用来定义命令行的提示符,可以按照我们自己的需求来定义自己喜欢的提示符
$: 提示符。如果是 root 用户,则会显示提示符为”#”;如果是普通用户,则会显示提示符为”$”
在什么情况下需要修改$PATH, 应该如何合理地修改它
需要修改环境变量加载一些命令时修改$PATH
如果永久更改就修改配置文件,临时更改对当前会话有效则命令行修改即可
修改过~/.bashrc后, 如何让改变⽴即生效
执行source profile就会立即生效
bashrc与profile有什么异同点? 两者的加载顺序如何
bashrc 用于交互式非登陆,profile用于交互式登陆
/etc/profile,/etc/bashrc是系统全局环境变量设定~/.profile,~/.bashrc用户家目录下的私有环境变量设定
加载顺序是 profile 再 bashrc
FHS与proc
为什么系统命令会分别放到/bin, /sbin, /usr/bin, /usr/sbin这四个⽬目录中? 这些⽬录间有什么区别
首先区别下/sbin和/bin:
从命令功能来看,/sbin 下的命令属于基本的系统命令,如shutdown,reboot,用于启动系统,修复系统,/bin下存放一些普通的基本命令,如ls,chmod等,这些命令在Linux系统里的配置文件脚本里经常用到。
从用户权限的角度看,/sbin目录下的命令通常只有管理员才可以运行,/bin下的命令管理员和一般的用户都可以使用。
从可运行时间角度看,/sbin,/bin能够在挂载其他文件系统前就可以使用。
而/usr/bin,/usr/sbin与/sbin /bin目录的区别在于:
/bin,/sbin目录是在系统启动后挂载到根文件系统中的,所以/sbin,/bin目录必须和根文件系统在同一分区;
/usr/bin,/usr/sbin可以和根文件系统不在一个分区
/var目录通常用来放哪些内容? /var和/tmp有什么区别
/var目录主要针对常态性变动文件,包括缓存(cache)、登录文件(logfile)以及某些软件运行所产生的文件,包括程序文件(lock file,run file),或者例如MySQL数据库的文件等
/var/cache: 应用程序本身运行过程中会产生生的一些暂存文件
/var/lib: 程序本身执行的过程中需要使用到的数据文件放置的目录。再次目录下各自的软件应该要有各自的目录。举例来说,Mysql的数据库放置到/var/lib/mysql,而rpm的数据库则放到/var/lib/rpm目录下
/var/lock: 某些设备或者是文件资源一次只能被一个应用程序所使用 ,如当系统中有一个刻录机两个人都要使用,那么需要在一个人使用的时候上锁,那么第一个人使用完毕后,第二个人才可以继续使用
/var/log: 这个是登录文件放置日志的的目录。里面比较重要的文件/var/log/messages,/var/log/harry(记录登陆者信息)等
/var/run/: 某些程序启动服务后,会将他们PID放置在这个目录下
/var和/tmp区别是/var系统产生的不可自动销毁的缓存文件、日志记录,/tmp保存在使用完毕后可随时销毁的缓存文件
/boot目录里有哪些内容
- 系统Kernel的配置文件
- 启动管理程序GRUB的目录,里面存放的都是GRUB在启动时所需要的画面、配置及各阶段(stage1, stage1.5, stage 2)的文件
- Initrd文件,是系统启动时的模块供应的主要来源
- System.map文件时系统Kernel中的变量对应表
- vmlinuz是在启动过程中最重要的一个文件,因为这个文件就是实际系统所使用的kernel
/usr/include和/usr/lib有什么区别
/usr/include(头文件存放处),/usr/lib(库函数存放处)
/proc目录下的那些数字是什么东⻄
目录名即为进程的pid
如何在proc⽂文件系统中查看CPU和内存信息
CPU: cat /proc/cpuinfo
内存: cat /proc/meminfo
⽂件系统
什么是 inode,它包含哪些内容
文件数据都储存在”block”中,那应该有一个地方储存文件的元信息,比如文件的创建者、文件的创建日期、文件的大小等等。这种储存文件元信息的区域就叫做inode,中文译名为”索引节点”
可以用stat命令,查看某个文件的inode信息,输出中除了文件名以外的所有文件信息,都存在inode之中
软链接和硬链接的区别是什么
软链接
- 软链接是存放另一个文件的路径的形式存在
- 软链接可以跨文件系统,硬链接不可以
- 软链接可以对一个不存在的文件名进行链接,硬链接必须要有源文件
- 软链接可以对目录进行链接
硬链接
- 硬链接,以文件副本的形式存在。但不占用实际空间
- 不允许给目录创建硬链接
- 硬链接只有在同一个文件系统中才能创建
- 删除其中一个硬链接文件并不影响其他有相同 inode 号的文件
不论是硬链接或软链接都不会将原本的档案复制一份,只会占用非常少量的磁碟空间
为什么不能对目录建立硬链接?
硬连接的话,相当于镜像的方式,创建一个目录的硬连接之后,操作系统需要把这个目录下所有的文件都要做一次硬连接(复制一份过去),这样操作系统在访问这个链接的时候要不断去遍历,大大增加复杂度,而且很容易进入死循环
为什么不能跨设备建立硬链接
首先,不同的文件系统的文件管理方式不同,甚至有些文件系统不是索引文件系统,并不一定两个文件系统的inode有相同的含义。再者,即使有相同inode含义,硬链接的几个文件,具有相同的inode号码。不同文件系统中,也可能有使用该inode号的文件,这将产生矛盾。
假设 B 是 A 的(软/硬)链接文件
对于硬链接和软链接, ⽐较当A或者B被删除时, 各有什什么后果?
- 硬链接
- A 被删除,源数据还在
- B 被删除,源数据还在
- 软连接
- A 被删除,数据丢失
- B 被删除,源数据还在
当A不存在时, 能否建⽴A的硬链接B? 能否建立A的软链接B?
不能建立硬链接,能建立软链接
LVM是什么,有什么作⽤
可以将LVM视为”动态分区” ,这意味着你可以在Linux系统运行时从命令行创建/调整大小/删除LVM”分区” (LVM称之为”逻辑卷” ): 不需要重新引导系统,内核就能知道新创建的或调整大小的分区
如果有多个硬盘,则逻辑卷可以扩展到多个磁盘: 换句话说,它们不受单个磁盘的大小限制,而不受总大小的限制
LV可以设置”striped” ,以便将I/O分发到并行承载LV的所有磁盘。类似于RAID-0,但是更容易设置
你可以创建任意LV的(只读)快照,可以在以后将原始LV恢复到快照,或者在不再需要快照时删除快照,这对于服务器备份(例如,(无法停止所有应用程序写入,创建快照并备份快照))很方便,但是也可用于在关键系统升级(克隆root分区,升级,如果出现问题,很容易恢复)之前提供”安全”
从安全角度考虑,哪些分区应适当限制⼤小
???
什么是 RAID,介绍至少3种 level 的 RAID
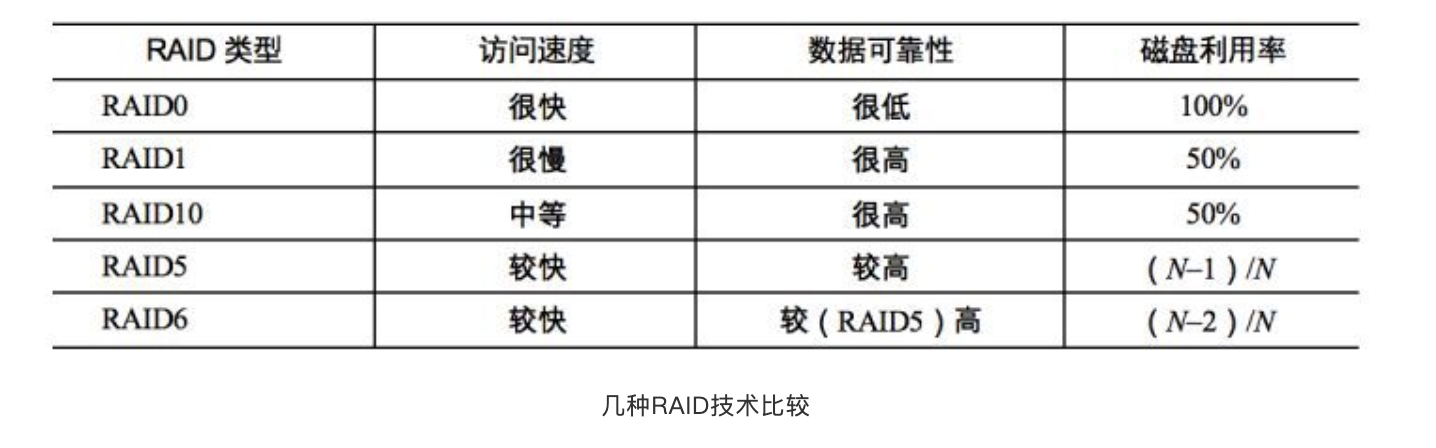
RAID0
数据在从内存缓冲区写入磁盘时,根据磁盘数量将数据分成N份,这些数据同时并发写入N块磁盘,使得数据整体写入速度是一块磁盘的N倍,读取的时候也一样,因此RAID0具有极快的数据读写速度。但是RAID0不做数据备份,N块磁盘中只要有一块损坏,数据完整性就被破坏,所有磁盘的数据都会损坏
RAID1
数据在写入磁盘时,将一份数据同时写入两块磁盘,这样任何一块磁盘损坏都不会导致数据丢失,插入一块新磁盘就可以通过复制数据的方式自动修复,具有极高的可靠性
RAID10
结合RAID0和RAID1两种方案,将所有磁盘平均分成两份,数据同时在两份磁盘写入,相当于RAID1,但是在每一份磁盘里面的N/2块磁盘上,利用RAID0技术并发读写,既提高可靠性又改善性能,不过RAID10的磁盘利用率较低,有一半的磁盘用来写备份数据
SUID机制与sudo
简述SUID机制存在的意义
SUID就是允许用户在执行程序的时候拥有这个程序属主的权限的一个机制
sudo的主配置文件路径是什么? 应如何更新这个文件?
/etc/sudoers是sudo的主配置文件
如果想设置sudo设置,有两种方式
- 直接在通过
sudo visudo /etc/sudoers修改/etc/sudoers文件 - 在
/etc/sudoers.d/username目录下添加一个文件,文件名称就用需要设定的用户名
1 | # 建议在/etc/sudoers.d/下面创建文件编辑 |
常用实例讲解
oracle用户可以在任何地点以任何的身份执行所有命令,等同于root
oracle2用户可以在任何地点以root的身份执行命令useradd(无需密码)和usermod(需要密码)
oracle3用户只能在192.168.1.120主机远程登录并以root身份执行ifconfig eth0命令
2
oracle3 192.168.1.120 = (root) NOPASSWD:NETCMNDoracle4用户可以执行/usr/sbin下的所有命令除了/usr/sbin/userdel
sudo提供人性化的日志功能,在/var/log/secure日志文件中可以查看到,用于记录所有sudo类用户的所有动作
如果需要在shell脚本中通过sudo调用某个命令或者程序, 应如何配置sudo?
sudo 的 -S 选项允许从stdin读入密码,使用方式echo [password] | sudo -S [command]
怎样将某个⾼权限程序⼀部分的功能开放给sudo?
例如能让用户改⼦网掩码, ⽽不让他修改机器ip地址
cron
系统配置⽂件的路径是什么?
/etc/crontab
cron时间描述⾥的’-‘是什么意思, ‘/‘是什么意思?
整数间的短线(-)指定一个整数范围。如,1-4意味着整数 1、2、3、4
正斜线(/)可以用来指定间隔频率。在范围后加上 /
@reboot会在什么时候执行?
希望在系统重启后执行某个命令
cron的最小粒度是分钟, 如何⽤cron实现每分钟跑两次(例如, 分别在第0秒和第30秒)运⾏的任务?
起两个cron,其中一个cron 利用sleep休息30秒
用户管理
新⽤户创建时, 如果选择⾃动创建⽤户home⽬录, 此时home⽬录中⾃动⽣成的内容是从哪⼉来的?
把框架目录(默认为/etc/skel)下的文件复制到用户主目录下
删除⼀个⽤户时, 系统会执⾏哪些操作, 改变哪些⽂件?
userdel 会查询系统账户文件,例如 /etc/password 和 /etc/group。那么它会删除所有和用户名相关的条目。在删除它之前,用户名必须存在。
不带选项使用 userdel,只会删除用户,-r 用于彻底删除,用户HOME目录下的信息会被移除,在其他位置上的档案也将一一找出并删除,比如用户的邮件池,在路径/var/mail/用户名下的邮件
用户的密码存储在哪个⽂件⾥?
Linux 账号文件/etc/passwd,密码文件/etc/shadow
禁⽌用户登录的⽅式有哪些?
命令方式
- 已经存在的用户: usermod -s /sbin/nologin
- 新用户: useradd -s /sbin/nologin
/bin/false是最严格的禁止login选项,一切服务都不能用
而/sbin/nologin只是不允许login系统,但可以使用其他ftp等服务
直接修改/etc/passwd
把需禁止用户的/bin/bash修改为/sbin/nologin
如何踢用户下线
Linux系统root用户可强制踢制其它登录用户
首先可用w命令查看登录用户信息
1 | $ w |
强制踢人命令格式pkill -kill -t tty比如踢掉第一个root: pkill -kill -t pts/1
- 只有root用户才能踢人,但任何用户都可以踢掉自己
- 如果同时有二个人用root用户登录,任何其中一个可以踢掉另一个
- pts/0就是自己开的桌面环境现的第一个终端
⽂件传输: scp vs rsync
对比默认参数下, 两种⽅式消耗的系统资源情况
在都是空目录的情况下同步信息,scp和rsync的执行效率相当,在一个量级,但是当已经同步过一次之后,在后续同步内容的过程中会看到同步的效率rsync快了非常多,这是因为scp是复制,而rsync是覆盖。
scp消耗资源少,不会提高多少系统负荷,在这一点上,rsync就远远不及它。虽然 rsync比scp会快一点,但当小文件众多的情况,rsync会导致硬盘I/O非常高,而scp基本不影响系统使用
在服务器端存在对应服务的条件下, 哪种方式的传输是有加密的?
rsync默认不是加密传输,而scp是加密传输,使用时可以按需选择
rsync如果有加密传输文件的需求,可以自定义加密管道管道协议,使用ssh通道或者vpn通道。使用参数:-e来指定相应的管道协议
1 | # 使用-e参数,指定加密的协议以及协议的端口号 |
请阐述在scp和rsync的具体适⽤场景
rsync 背后算法原理可以参考RSYNC 的核心算法
如果是频繁更新的文件并且是小文件,则建议使用rsync
如果是很少更新的文件,建议使用scp,简单方便快捷,同时还是加密传输
即在什么时候应该适用scp⽽不是rsync, 在什么时候应该适用rsync⽽不是scp
只需传输改动部分,无需重新传输整个文件时用rsync
点对点传输全量文件时用scp
- rsync只对差异文件做更新,可以做增量或全量备份;而scp只能做全量备份。简单说就是rsync只传修改了的部分,如果改动较小就不需要全部重传,所以rsync备份速度较快;默认情况下,rsync通过比较文件的最后修改时间(mtime)和文件的大小(size)来确认哪些文件需要被同步过去
- rsync是分块校验+传输,scp是整个文件传输。rsync比scp有优势的地方在于单个大文件的一小部分存在改动时,只需传输改动部分,无需重新传输整个文件。如果传输一个新的文件,理论上rsync没有优势
Linux 实践部分
top
如何将top的输出通过管道交给另⼀个进程?
top -bn 1 显示所有进程信息
- -b: 在批处理模式下启动top,这对于将top输出发送到其他程序或文件很有用。在此模式下,top将不接受输入,并一直运行到您使用`-n’命令行选项设置的迭代次数限制或终止为止
- 指定结束前top应生成的最大迭代次数或帧数
举例,top翻页: top -bn1 | less
如何让top显示每一个CPU的使⽤情况?
如果要查看每个逻辑cpu的使用率,只需要运行top命令,按下数字键1即可
如何在top⾥杀进程
按下k即可,根据后面输入的PID杀死进程
top的默认刷新时间是多少? 如何修改这个默认设置?
默认是5s,可以在启动时使用-d指定信息刷新的时间间隔,也可以在交互时键入d命令指定间隔时间
top⾥的load average是如何计算的?
指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数
对于单cpu和多cpu情况,系统的average load情况稍有不同。单cpu是最简单的情形,比如过去的平均一分钟里面,判断系统处于运行或者等待状态的进程数则表示系统的平均负载,但是在linux系统下稍有不同,那些处于io等待状态的进程也会被纳入去计算。这样就导致CPU利用率可能和平均负载很不同,在大部分进程都在做IO的时候,即使平均负载很大,也会没有很大的CPU利用率。另外,有些系统对于进程和线程的处理也很不一样,有的对于每一个线程都会进行计算,有的只关注进程,对于超线程技术的线程来说,可能又是别的处理方式。对于多CPU的平均负载的计算,是在单CPU的情况下再除以CPU的个数
假设top显示ffmpeg进程的CPU使⽤率为143.7%, 请具体解释这个数值是如何计算出来的
ffmpeg进程在多核CPU下,每个CPU使用率的累加和
第四列的NI是什么意思?
任务nice值,代表这个进程的优先值
在LINUX系统中,Nice值的范围从-20到+19(不同系统的值范围是不一样的),正值表示低优先级,负值表示高优先级,值为零则表示不会调整该进程的优先级。具有最高优先级的程序,其nice值最低,所以在LINUX系统中,值-20使得一项任务变得非常重要;与之相反,如果任务的nice为+19,则表示它是一个高尚的、无私的任务,允许所有其他任务比自己享有宝贵的CPU时间的更大使用份额,这也就是nice的名称的来意
ssh
ssh的实现原理
远程主机收到用户的登录请求,把自己的公钥发给用户
用户使用这个公钥,将登录密码加密后,发送回来
远程主机用自己的私钥,解密登录密码,如果密码正确,就同意用户登录
ssh连接时如何指定远程端口, 如何设置连接超时间?
1 | # -p 指定端口 |
ssh私钥⽂件默认的权限是什么?
600,属主是当前用户
如何利⽤ssh来进行端⼝转发?
本地端口转发
假定host1是本地主机,host2是远程主机。由于种种原因,这两台主机之间无法连通。但是,另外还有一台host3,可以同时连通前面两台主机。因此,很自然的想法就是,通过host3,将host1连上host2
在host1执行下面的命令
1 | $ ssh -L 2121:host2:21 host3 |
命令中的L参数一共接受三个值,分别是”本地端口:目标主机:目标主机端口”,它们之间用冒号分隔。这条命令的意思,就是指定SSH绑定本地端口2121,然后指定host3将所有的数据,转发到目标主机host2的21端口(假定host2运行FTP,默认端口为21)
这样一来,只要连接host1的2121端口,就等于连上了host2的21端口
1 | $ ftp localhost:2121 |
“本地端口转发”使得host1和host3之间仿佛形成一个数据传输的秘密隧道,因此又被称为”SSH隧道”
下面是一个比较有趣的例子
1 | $ ssh -L 5900:localhost:5900 host3 |
它表示将本机的5900端口绑定host3的5900端口(这里的localhost指的是host3,因为目标主机是相对host3而言的)
另一个例子是通过host3的端口转发,ssh登录host2
1 | $ ssh -L 9001:host2:22 host3 |
这时,只要ssh登录本机的9001端口,就相当于登录host2了,下面的-p参数表示指定登录端口
1 | $ ssh -p 9001 localhost |
远程端口转发
还是接着看上面那个例子,host1与host2之间无法连通,必须借助host3转发。但是,特殊情况出现了,host3是一台内网机器,它可以连接外网的host1,但是反过来就不行,外网的host1连不上内网的host3。这时,”本地端口转发”就不能用了,怎么办?
解决办法是,既然host3可以连host1,那么就从host3上建立与host1的SSH连接,然后在host1上使用这条连接就可以了
在host3执行下面的命令
1 | $ ssh -R 2121:host2:21 host1 |
R参数也是接受三个值,分别是”远程主机端口:目标主机:目标主机端口”。这条命令的意思,就是让host1监听它自己的2121端口,然后将所有数据经由host3,转发到host2的21端口。由于对于host3来说,host1是远程主机,所以这种情况就被称为”远程端口绑定”
绑定之后,我们在host1就可以连接host2了
1 | $ ftp localhost:2121 |
passphrase是什么东西? 有什么作用?
passphrase是对私钥设置的口令,passphrase是用来对密钥对的私钥进行加密的,不会在网络上传播
在⾃己的电脑上操作,通过 ssh agent forward 先登录 A,再从 A 登录 B
find
find能根据哪些条件来查找⽂件
- 指搜索层级
- 根据文件名和inode查找
- 根据属主、属组查找
- 根据文件类型查找
- 空文件或目录
- 组合条件
- 根据文件大小来查找
- 根据时间戳
- 根据权限查找
find能否根据⽂件内容来搜索, 为什么?
不能,但是可以配合grep 命令来
find / | xargs grep function查找系统根目录下面的所有文件的内容中包含有function字符串的文件列表
find可以如何删除找到的⽂件? 请提供三种方法
以删除目录下所有exe文件为例
- find . -name -type f “*.exe” | xargs rm -rf
- find . -name ‘’*.exe” -type f -print -exec rm -rf {} ;
- find ./ -iname “*.exe” -ok rm {} ;
- find ./ -iname “*.exe” -delete
mtime, ctime, atime的区别
- atime:(access time)显示的是文件中的数据最后被访问的时间,比如系统的进程直接使用或通过一些命令和脚本间接使用。(执行一些可执行文件或脚本)
- mtime:(modify time)显示的是文件内容被修改的最后时间,比如用vi编辑时就会被改变。(也就是Block的内容)
- ctime:(change time)显示的是文件的权限、拥有者、所属的组、链接数发生改变时的时间。当然当内容改变时也会随之改变(即inode内容发生改变和Block内容发生改变时
有一个要注意的就是,在kernel 2.6.30之前,文件系统中默认会及时的更新atime,而在此之后的版本里有变化
Linux atime修改策略与 mount 有关,可选的值有 noatime、relatime 和 strictatime
- noatime: atime不会被更新,即使修改了文件内容
- relatime:
- 如果一个文件的 atime 比 ctime 或 mtime 更早,此时你去读取了该文件,atime 才会被更新为当前时间。
- atime 比现在早一天,那么 atime 在文件读取时会被更新
- strictatime: atime 在文件每次被读取时,都能够被更新
所以只有发生以下三种情况之一才会更新atime
- 将分区 mount 的挂载的时候指定采用非 relatime 方式,使用方法就是通过
mount -o relatime /dir来挂装目录- atime 小于 ctime 或者小于 mtime 的时候
- 本次的 access time 和上次的 atime 超过24个小时
-type中有哪些常⻅类型?
b block (buffered) special
- c: character (unbuffered) special
- d: directory
- p: named pipe (FIFO)
- f: regular file
- l: symbolic link; this is never true if the -L option or the -follow option is in effect, unless the symbolic link is broken. If you want to search for symbolic links when -L is in effect, use -xtype.
- s: socket
- D: door (Solaris)
grep
了解-c/-v/-A/-B/-C/-E/-n/-i/-R参数的意义
- -c: 统计匹配到的次数
- -v: 查找不包含指定内容的行
- -A: 显示匹配行及前面多少行, 如: -A3, 则表示显示匹配行及前3行
- -B: 显示匹配行及后面多少行, 如: -B3, 则表示显示匹配行及后3行
- -C: 显示匹配行前后多少行, 如: -C3, 则表示显示批量行前后3行
- -E: –extended-regexp的缩写,将模式解释为一个扩展的正则表达式
- -n: 显示行号
- -i: 不区分大小写
- -R: 递归地读取每个目录下的所有文件。遵循所有符号链接,不像-r
- -w: 按单词搜索
- -e: 使用正则搜索
- -r: 逐层遍历目录查找
- –color: 匹配到的内容高亮显示
- –include: 指定匹配的文件类型
- –exclude: 过滤不需要匹配的文件类型
- -q: 不显示任何信息
- -o: 只显示匹配PATTERN 部分
对于-q/-o参数, 给出具体的使用场景
-q 场景用于是否能够匹配,通过$?知道命令的执行结果来确认是否匹配到信息,避免泄漏信息
-o 场景用于知道匹配到的文件,不需要过多知道匹配到的行信息,避免泄漏
ls
对于ls -l的输出中的第⼀列, 给出每个字符的含义
第一个字符如果是d表示目录,空为文件
从r 读权限,w 写权限,x执行权限
目录的⼤小是什么意思?
用ls命令出来的目录大小,不包括里面的文件大小
基本上用ls命令查看到的目录大小都是4K(假设块大小为4K)
ls默认的排序⽅式是什么? 有哪些参数能改变这⼀行为?
默认会以文件名排序
-S 基于文件大小进行排序;-t 基于文件修改时间进行排序;-r 将排序结果反向输出
-f 直接列出结果,而不进行排序
对于-R/-i参数, 请给出具体的使⽤场景
-R 若目录下有文件,则以下之文件亦皆依序列出
-i 打印每个文件、目录的索引号
需要查看子目录下的文件时,使用-R,需要知道索引号时使用 -i
df/du
如何显示inode占用率?
df -ih
如何显示⽂件系统的类型?
df -Th
什么情况下⽤rm删除了一个⼤文件,df显示的空余⼤小会没有变化
参考自运维实战案例之文件已删除但空间不释放问题解析,文中问题是删除access_log文件空间未释放
解决思路
一般说来不会出现删除文件后空间不释放的情况,但是也存在例外,比如文件被进程锁定,或者有进程一直在向这个文件写数据等等,要理解这个问题,就需要知道Linux下文件的存储机制和存储结构。
一个文件在文件系统中的存放分为两个部分:数据部分和指针部分,指针位于文件系统的meta-data中,数据被删除后,这个指针就从meta-data中清除了,而数据部分存储在磁盘中,数据对应的指针从meta-data中清除后,文件数据部分占用的空间就可以被覆盖并写入新的内容,之所以出现删除access_log文件后,空间还没释放,就是因为httpd进程还在一直向这个文件写入内容,导致虽然删除了access_log文件,但文件对应的指针部分由于进程锁定,并未从meta-data中清除,而由于指针并未被删除,那么系统内核就认为文件并未被删除,因此通过df命令查询空间并未释放也就不足为奇了
问题排查
既然有了解决问题的思路,那么接下来看看是否有进程一直在向acess.log文件中写数据,这里需要用到Linux下的lsof命令,通过lsof | grep delete命令可以获取一个已经被删除但仍然被应用程序占用的文件列表
从输出结果可以看到,/tmp/acess.log文件被进程httpd锁定,而httpd进程还一直向这个文件写入日志数据,从第七列可知,这个日志文件大小仅70G,而系统根分区总大小才100G,由此可知,这个文件就是导致系统根分区空间耗尽的罪魁祸首,在最后一列的“deleted”状态,说明这个日志文件已经被删除,但由于进程还在一直向此文件写入数据,空间并未释放
解决问题
最简单的方法是关闭或者重启httpd进程,不过这并不是最好的方法,对待这种进程不停对文件写日志的操作,要释放文件占用的磁盘空间,最好的方法是在线清空这个文件,通过以下命令完成
1 | echo " " >/tmp/acess.log |
通过这种方法,磁盘空间不但可以马上释放,也可保障进程继续向文件写入日志,这种方法经常用于在线清理Apache、Tomcat、Nginx等Web服务产生的日志文件
如何仅显示某个⽬录下⽂件的总⼤小
du -sh 目录名
请解释如何产⽣一个⽂件空洞

在UNIX文件操作中,文件位移量可以大于文件的当前长度
在这种情况下,对该文件的下一次写将延长该文件,并在文件中构成一个空洞。位于文件中但没有写过的字节都被设为 0
如果 offset 比文件的当前长度更大,下一个写操作就会把文件”撑大(extend)”在文件里创造”空洞(hole)”
没有被实际写入文件的所有字节由重复的 0 表示。空洞是否占用硬盘空间是由文件系统(file system)决定的
如果发现了 df 和 du 两个命令的输出磁盘占⽤量不一致,可能原因有哪些
常见的df和du不一致情况就是文件删除的问题。当一个文件被删除后,在文件系统 目录中已经不可见了,所以du就不会再统计它了。然而如果此时还有运行的进程持有这个已经被删除了的文件的句柄,那么这个文件就不会真正在磁盘中被删除, 分区超级块中的信息也就不会更改。这样df仍旧会统计这个被删除了的文件
硬盘空间消失是因为删除的文件被其他程序引用,导致空间无法回收
ps
ps auxww默认是按照什么进⾏排序的?
auxww参数解释
a选项显示出所有运行进程的内容, 而不仅仅是您的进程u选项显示出进程所归属的用户名字以及内存使用,x选项显示出后台进程ww选项表示把每个进程的整个命令行全部显示完, 而不是由于命令行过长就把它从屏幕上截去
默认情况下,输出不排序
如何用ps来查看进程树
ps -e f
ps -e -H
如何⽤ps来查看单个线程的资源使⽤情况?
-L用于显示线程
ps -eLf
1 | $ ps -eLf |
LWP light weight process ID 可以称其为线程ID
NLWP 进程中的线程数number of lwps (threads) in the process
cut
cut默认的分隔符是什么? 如何设置分隔符?
-d自定义分隔符,默认为制表符
对于每⼀行, 如何让cut仅显示第3到第5列?
-f 参数指定 3-5
对于每⼀行, 如何让cut仅显示第10到第15个字符?
-c 以字符为单位进行分割,-f 指定10-15
在什么情况下, -c和-b的输出有区别?
-b: 以字节为单位进行分割,-c: 以字符为单位进行分割,多字节字符时就输出有区别了
sort
如何对每⾏第3列进⾏排序?
-k3,-k指定要排序的key,key由字段组成。key格式为”POS1[,POS2]”,POS1为key起始位置,POS2为key结束位置
请给出具体例子说明什么情况下使⽤了-n会导致sort的输出和不加-n不一致
当排序列为数值时,使用-n选项,来告诉sort要以数值来排序,不加-n则是以字典序排序
请了解-u/-r的意义
-r默认是升序排序,使用该选项将得到降序排序的结果,-r不参与排序动作,只是操作排序完成后的结果
-u只输出重复行的第一行。结合”-f”使用时,重复的小写行被丢弃。
默认的分隔符是什么? 如何指定分隔符?
-t<分隔字符>: 指定排序时所用的栏位分隔字符
请给出-T参数的使⽤场景
sort命令在进行大文件排序,会自动使用外排序,此时默认会在/tmp目录下新建一个大文件,排序完成后删除,产生的临时文件是隐藏文件,解决办法是使用-T参数指定临时文件目录
tail/head
如何取得⼀个⽂件的前几个字符?
head -c<字符数> finename
tail -f是⼲什么的?
tail命令用于输入文件中的尾部内容,-f 显示文件最新追加的内容
如何用tail显示从第25⾏开始, 显示⼀个40多⾏(不不知道具体数目)的⽂件的内容?
tail -n +25
请提供两种不同的办法来打印⼀个文件的第50⾏内容

head -n 50,输出最后一行就是第50⾏内容
tail -n +50,输出第一行就是第50⾏内容
iostat
直接⽆参数启动这个命令,能得到哪些数据?
1 | $ iostat |
如何持续监控某块硬盘的读写情况?
1 | $ iostat -d vda -x 2 |
-d: 仅显示磁盘统计信息,接硬盘名可以指定某块具体硬盘,这里没有给出硬盘路径就是默认全部
-x: 输出扩展信息
iostat的输出中,哪些输出对于诊断磁盘IO问题⽐较关键?
%iowait: 如果该值较高,表示磁盘存在I/O瓶颈
%util: 一秒中有百分之多少的时间用于I/O操作,即被IO消耗的CPU百分比,一般地,如果该参数是100%表示设备已经接近满负荷运行了
avgqu-sz: 如果avgqu-sz比较大,也表示有当量io在等待
tps是什么东西? 这个值正常情况下会在哪个范围内波动?
TPS: Transactions Per Second(每秒传输的事物处理个数)
TPS波动范围= TPS标准差/TPS平均值* 100%. 在5%内算是正常的
ip
查看arp表
ARP表,它记录着主机的IP地址和MAC地址的对应关系
ARP协议: ARP协议是工作在网络层的协议,它负责将IP地址解析为MAC地址
ip neigh
查看有哪些端⼝
查看ip地址
Ip a
查看路由表
ip route
使⽤ip命令设置ip地址
设置IP: ip addr add 192.168.0.123/24 dev eth0
删除配置的IP: ip add del 192.168.0.123/24 dev eth0
ss/netstat
查看当前监听的端⼝,并显示监听端⼝的进程 PID
netstat -anlp | grep 80
wget
如何用wget发⼀个HTTP POST请求
1 | wget --post-data="user=user1&pass=pass1&submit=Login" http://domain.com/path/page_need_login.php |
请简述wget续传/重复下载的逻辑及相关参数
当文件特别大或者网络特别慢的时候,往往一个文件还没有下载完,连接就已经被切断,此时就需要断点续传。wget的断点续传是自动的,只需要使用-c参数
重复下载最简单的做法只需要 加上 -O 就可以
-O和-o参数有什么区别?
使用wget -O下载并以不同的文件名保存(-O:下载文件到对应目录,并且修改文件名称),-o将所有消息记录到日志文件
screen
这个命令是⽤来做什么的?
用户可以通过该软件同时连接多个本地或远程的命令行会话,并在其间自由切换
如何继续上⼀次的会话?
查看所有会话
screen -ls
重新连接会话,12865 为会话id
screen -r 12865
如何⼿工保存⼀个会话?
在每个screen session 下,所有命令都以 ctrl+a(C-a) 开始
C-a d -> detach,暂时离开当前session,将目前的 screen session (可能含有多个 windows) 丢到后台执行,并会回到还没进 screen 时的状态
touch
touch修改文件的atime和mtime
touch -a filename: 更新文件的atime和ctime
touch -m filename: 更新文件的mtime和ctime
touch -r 参考文件名 目标文件名: 将目标文件的的atime和mtime更改为参考文件的时间并更新ctime
Linux是如何更新访问时间的,这里须得明白下面一点,其更新策略为,当满足以下任意一条件时才更新访问时间
- 访问时间早于修改时间或改变时间
- 距离上次更新时间间隔大于24h
Docker
Docker和虚拟机的区别
服务器好比运输码头: 拥有场地和各种设备(服务器硬件资源)
服务器虚拟化好比作码头上的仓库: 拥有独立的空间堆放各种货物或集装箱(仓库之间完全独立,独立的应用系统和操作系统)
Docker比作集装箱: 各种货物的打包
熟悉Dockerfile编写
熟悉docker常⽤用指令和参数: 打包/查看/拉取/运行/设置环境变量/挂载⽬录
打包: docker image build -t koa-demo:0.0.1 .
有Dockerfile 文件之后,可以使用
docker image build命令创建 image 文件查看本机image文件: docker image ls
删除本机image文件: docker rmi [imageID]
拉取: docker image pull library/hello-world
library/hello-world是 image 文件在仓库里面的位置,其中library是 image 文件所在的组,hello-world是 image 文件的名字运行: docker container run hello-world
docker container run命令会从 image 文件,生成一个正在运行的容器实例注意,
docker container run命令具有自动抓取 image 文件的功能。如果发现本地没有指定的 image 文件,就会从仓库自动抓取。因此,前面的docker image pull命令并不是必需的步骤查看本机正在运行的容器: docker container ls
查看本机所有容器,包括终止运行的容器: docker container ls –all
image 文件生成的容器实例,本身也是一个文件,称为容器文件。也就是说,一旦容器生成,就会同时存在两个文件: image 文件和容器文件。而且关闭容器并不会删除容器文件,只是容器停止运行而已
终止: docker container kill [containID]
对于那些不会自动终止的容器,必须使用
docker container kill命令手动终止删除终止运行的容器文件: docker container rm [containerID]
终止运行的容器文件,依然会占据硬盘空间
设置环境变量: docker run –env VARIABLE=VALUE image:tag
可以使用简写 -e 替换 –env
挂载目录: docker run -it -v /test:/soft centos
启动一个centos容器,宿主机的/test目录挂载到容器的/soft目录
查看镜像/容器详细信息: docker inspect NAME|ID
Docker⽹络类型,以及Docker对主机上的iptables的影响
查看容器的详细信息(可以查看网络类型Networks)
1 | $ docker network ls |
bridge(桥接式网络)(默认)
启动容器时,首先会在主机上创建一个docker0的虚拟网桥,相当于交换机,同时自动分配一对网卡设备,一半在容器(eth0),一半在宿主机,并且还关联到了docker0,从而进行连接
Docker0网络是Docker搭建的一个虚拟桥接网络,默认网关地址是172.17.0.1。Docker默认的网络是Docker0网络,也就意味着Docker中所有没有指定网络的容器都会加入到这个桥接网络中,网络中的容器可以互相通信。
Container(K8S会常用)
与另一个运行得容器共用一个网络Network Namespace
使用方式:
--network=container:容器ID注意共用时端口不能相同,端口谁先占用就是谁的
host (主机)
与宿主机共用一个网络
使用方式:
--network=host使用后不需要做端口映射,性能最高,端口谁先占用就是谁的
none (空)
不为容器配置任何网络功能,不使用任何网络类型
使用方式:--network=none
Docker对主机上的iptables的影响
Docker引擎启动的时候会修改iptables规则
使用 iptables-save 命令查看 iptable,Docker 对 iptables 的 NAT 表和 FILTER 表都作了较大的改动
容器对外请求数据
如果Docker0中的容器请求外部的数据,那么他的数据包将会发送到网关172.17.0.1处。当数据包到达网关后,将会查询主机的路由表,确定数据包将从那个网卡发出。iptables负责对数据包进行snat转换,将原地址转为对应网卡的地址,因此容器对外是不可见的
外部对容器请求数据
外部想要访问容器内的数据,首先需要将容器的端口映射到宿主机上。这时候docker会在iptables添加转发规则,把接收到的数据转发给容器
重启iptables会导致docker 的规则丢失,所以建议动态修改iptables
Docker的镜像是如何存储
后端开发
要求
PYTHONPATH环境变量
PYTHONPATH是Python中一个重要的环境变量,用于在导入模块的时候搜索路径
Linux下设置PYTHONPATH环境变量有三种方法: 一种作用于当前终端,一种作用于当前用户,一种作用于所有用户
1 | # 作用于当前终端,直接当前终端输入命令 |
查看python的包路径
利用pip 命令查看pip show beautifulsoup4
利用包的__file__函数
1 | $ python |
Python3查看pip安装的软件包及版本
2
3
4
5
6
7
8
Package Version
---------------------------------- ---------
alabaster 0.7.12
anaconda-client 1.7.2
anaconda-navigator 1.9.12
anaconda-project 0.8.3
appnope 0.1.0
python的包结构
1 | picture/ Top-level package |
包(package)是 Python 中对模块的更高一级的抽象,Python 要求每一个「包」目录下,都必须有一个名为 __init__.py 的文件,一个Python 脚本就是一个 Python 模块(Module)。
python的日志模块
Python 标准库 logging 用作记录日志,默认分为六种日志级别(括号为级别对应的数值),NOTSET(0)、DEBUG(10)、INFO(20)、WARNING(30)、ERROR(40)、CRITICAL(50)
absolute_import这个模块的用途
作用是绝对路径导入
绝对导入和相对导入之间的差异仅在从包导入模块和从包导入其他子模块时才起作用
例如: 关于这句from __future__ import absolute_import的作用
直观地看就是说”加入绝对引入这个新特性”。说到绝对引入,当然就会想到相对引入。那么什么是相对引入呢?比如说,你的包结构是这样的:
1 | pkg/ |
如果你在main.py中写import string,那么在Python 2.4或之前,Python会先查找当前目录下有没有string.py,若找到了,则引入该模块,然后你在main.py中可以直接用string了。如果你是真的想用同目录下的string.py那就好,但是如果你是想用系统自带的标准string.py呢?那其实没有什么好的简洁的方式可以忽略掉同目录的string.py而引入系统自带的标准string.py。这时候你就需要from __future__ import absolute_import了。这样,你就可以用import string来引入系统的标准string.py,而用from pkg import string来引入当前目录下的string.py了
熟悉import的⽅式: 相对路径和绝对路径
相对路径导入方式只有from…import支持,import语句不支持,且只有使用.或..的才算是相对路径,否则就是绝对路径,就会从sys.path下搜索
1 | # 同级目录 导入 reverse |
常见HTTP的状态码
1xx(临时响应)表示临时响应并需要请求者继续执行操作的状态代码。
- 100 (继续)请求者应当继续提出请求。服务器返回此代码表示已收到请求的第一部分,正在等待其余部分
- 101 (切换协议)请求者已要求服务器切换协议,服务器已确认并准备切换。
2xx (成功)表示成功处理了请求的状态代码。
- 200 (成功)服务器已成功处理了请求。通常,这表示服务器提供了请求的网页。
- 201 (已创建)请求成功并且服务器创建了新的资源。
- 202 (已接受)服务器已接受请求,但尚未处理。
- 203 (非授权信息)服务器已成功处理了请求,但返回的信息可能来自另一来源。
- 204 (无内容)服务器成功处理了请求,但没有返回任何内容。
- 205 (重置内容)服务器成功处理了请求,但没有返回任何内容。
- 206 (部分内容)服务器成功处理了部分GET 请求。
3xx (重定向)表示要完成请求,需要进一步操作。通常,这些状态代码用来重定向。
- 300 (多种选择)针对请求,服务器可执行多种操作。服务器可根据请求者(user agent) 选择一项操作,或提供操作列表供请求者选择。
- 301 (永久移动)请求的网页已永久移动到新位置。服务器返回此响应(对GET 或HEAD请求的响应)时,会自动将请求者转到新位置。
- 302 (临时移动)服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。
- 303 (查看其他位置)请求者应当对不同的位置使用单独的GET 请求来检索响应时,服务器返回此代码。
- 304 (未修改)自从上次请求后,请求的网页未修改过。服务器返回此响应时,不会返回网页内容,即取的缓存。
- 305 (使用代理)请求者只能使用代理访问请求的网页。如果服务器返回此响应,还表示请求者应使用代理。
- 307 (临时重定向)服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。
4xx(请求错误)这些状态代码表示请求可能出错,妨碍了服务器的处理。
- 400 (错误请求)服务器不理解请求的语法。
- 401 (未授权)请求要求身份验证。对于需要登录的网页,服务器可能返回此响应。
- 403 (禁止)服务器拒绝请求。
- 404 (未找到)服务器找不到请求的网页。
- 405 (方法禁用)禁用请求中指定的方法。
- 406 (不接受)无法使用请求的内容特性响应请求的网页。
- 407 (需要代理授权)此状态代码与401(未授权)类似,但指定请求者应当授权使用代理。
- 408 (请求超时)服务器等候请求时发生超时。
- 409 (冲突)服务器在完成请求时发生冲突。服务器必须在响应中包含有关冲突的信息。
- 410(已删除)如果请求的资源已永久删除,服务器就会返回此响应。
- 411 (需要有效长度)服务器不接受不含有效内容长度标头字段的请求。
- 412 (未满足前提条件)服务器未满足请求者在请求中设置的其中一个前提条件。
- 413 (请求实体过大)服务器无法处理请求,因为请求实体过大,超出服务器的处理能力。
- 414 (请求的URI 过长)请求的URI(通常为网址)过长,服务器无法处理。
- 415 (不支持的媒体类型)请求的格式不受请求页面的支持。
- 416 (请求范围不符合要求)如果页面无法提供请求的范围,则服务器会返回此状态代码。
- 417 (未满足期望值)服务器未满足”期望”请求标头字段的要求。
5xx(服务器错误)这些状态代码表示服务器在尝试处理请求时发生内部错误。这些错误可能是服务器本身的错误,而不是请求出错。
- 500 (服务器内部错误)服务器遇到错误,无法完成请求。
- 501 (尚未实施)服务器不具备完成请求的功能。例如,服务器无法识别请求方法时可能会返回此代码。
- 502 (错误网关)服务器作为网关或代理,从上游服务器收到无效响应。
- 503 (服务不可用)服务器目前无法使用(由于超载或停机维护)。通常,这只是暂时状态。
- 504 (网关超时)服务器作为网关或代理,但是没有及时从上游服务器收到请求。
- 505 (HTTP 版本不受支持)服务器不支持请求中所用的HTTP 协议版本。