CAP 定理是分布式系统的基本定理,也是理解分布式系统的起点。
前言
在学习微服务概念时看到 CAP 概念。因此学习了解并记录。

分布式系统(distributed system)正变得越来越重要,大型网站几乎都是分布式的,大数据体系也是分布式结构的。
分布式系统的最大难点,就是各个节点的状态如何同步。
CAP 定理是这方面的基本定理,也是理解分布式系统的起点。
CAP理论是架构师在设计分布式系统过程中,处理数据一致性问题时必须考虑的基石级理论。
分布式系统
分布式系统非常关注三个指标
1. 数据一致性
数据“强一致性”,是希望系统只读到最新写入的数据。
通过单点串行化的方式,就能够达到这个效果。
2. 系统可用性
如果系统每运行100个时间单位,会有1个时间单位无法提供服务,则说系统的可用性是99%。
可用性和可靠性是比较容易搞混的两个指标,以一台取款机为例:
- 正确的输入,能够取到正确的钱,表示系统可靠
- 取款机7*24小时提供服务,表示系统可用
保证系统高可用的方法是:
- 冗余
- 故障自动转移
3. 节点连通性与扩展性
分布式系统,往往有多个节点,每个节点之间,都不是完全独立的,
需要相互通信,当发生节点无法联通时,数据是否还能保持一致,
系统要如何进行容错处理,是需要考虑的。
理解
CAP定理是对上述分布式系统的三个特性进行归纳。
- Consistency 一致性
- Availability 可用性
- Partition Tolerance 分区容忍性
等等。好像根本理解不了啊。
没关系可以参看阮一峰老师的文章 CAP 定理的含义 先有个概念印象。
看完之后好像懂了,有种是懂非懂的感觉。
没关系,本人结自己理解在叙述一遍
CAP理论核心思想是任何基于网络的数据共享系统最多只能满足两者,不可能三者兼顾。
- Consistency: 一致性指”all nodes see the same data at the same time”,
即更新操作成功并返回客户端完成后,所有节点在同一时间的数据完全一致。等同于所有节点拥有数据的最新版本。- 这里对应一致性模型中的强一致性*
- Availability: 可用性指”Reads and writes always succeed”,
意思是只要收到用户的读写请求,每一个非故障的节点就必须在有限的时间内给出回应。
用户都一定会收到回应数据,不会收到服务错误,但不保证用户收到的数据一定是最新的数据。- 两个指标”有限的时间内”,”给出回应”*
- Partition tolerance: 分区容忍性具体指”the system continues to operate despite arbitrary message loss or failure of part of the system”
即分布式系统容忍因网络故障出现分区,分区之间网络不可达的情况。仍然需要能够保证对外提供满足一致性和可用性的服务,除非是整个网络环境都发生了故障。
特殊的原因导致这些子网络出现网络不连通的状况,但各个子网络的内部网络是正常的,从而导致整个系统的网络环境被切分成了若干个孤立的区域。
“
提高分区容忍性的办法就是一个数据项复制到多个节点上,那么出现分区之后,这一数据项就可能分布到各个区里。分区容忍就提高了。然而,要把数据复制到多个节点,就会带来一致性的问题,就是多个节点上面的数据可能是不一致的。要保证一致,每次写操作就都要等待全部节点写成功,而这等待又会带来可用性的问题。
“
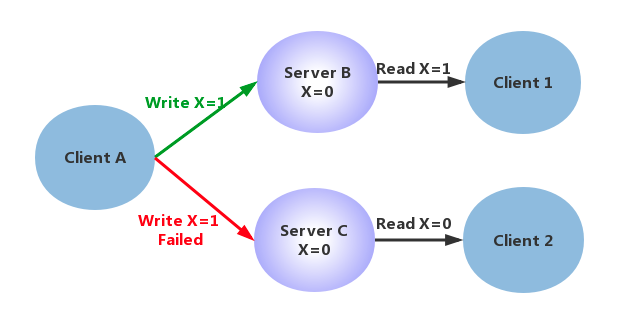
如图,ClientA 可以发送指令到 Server 并且设置更新X的值,Client1 从Server读取该值,在单点情况下,即没有网络分区的情况下,或者通过简单的事务机制,可以保证Client 1 读到的始终是最新的值,不存在一致性的问题。
如果在系统中增加一组节点,即设计为分布式系统,Write操作可能在 Server B 上成功,在 Server C 上失败,这时候对于 Client 1 和 Client 2,就会读取到不一致的值,出现不一致。如果要保持x值的一致性,Write 操作必须同时失败,降低系统的可用性。
如果 ClientA 写 ServerB 操作的时候,让 ServerB 向 ServerC 发送一条消息,要求 ServerC 的 X 也改成 1。即保证每次写操作就都要等待全部节点写成功,那这样”有限时间”过长会降低系统的可用性。
因此设计分布式数据系统,就是在一致性和可用性之间取一个平衡。
强一致很难怎么办?
在通常的分布式系统中,为了保证数据的高可用,通常会将数据保留多个副本(replica),
网络分区是既成的现实,于是只能在可用性和一致性两者间做出选择。
CAP理论关注的是绝对情况下,在工程上,可用性和一致性并不是完全对立,
我们关注的往往是如何在保持相对一致性的前提下,提高系统的可用性。
单点串行化,虽然能保证“强一致”,但对系统的并发性能,以及高可用有较大影响,
互联网的玩法,更多的是“最终一致性”,短期内未必读到最新的数据,
但在一个可接受的时间窗口之后,能够读到最新的数据。
当然,并不是完全不管数据的一致性。
牺牲一致性,只是不再要求关系型数据库中的强一致性,
例如大多数web应用,其实并不需要强一致性,因此牺牲一致性而换取高可用性。达到最终一致性即可,
考虑到客户体验,这个最终一致的时间窗口,要尽可能的对用户透明,也就是需要保障“用户感知到的一致性”。
用阮一峰老师的例子来说明:
举例来说,发布一张网页到 CDN,多个服务器有这张网页的副本。后来发现一个错误,需要更新网页,这时只能每个服务器都更新一遍。
一般来说,网页的更新不是特别强调一致性。短时期内,一些用户拿到老版本,另一些用户拿到新版本,问题不会特别大。当然,所有人最终都会看到新版本。所以,这个场合就是可用性高于一致性。
通常是通过数据的多份异步复制来实现系统的高可用和数据的最终一致性的,
“用户感知到的一致性”的时间窗口则取决于数据复制到一致状态的时间。
总结
分布式系统本身就强调的是不挂掉。因此设计时架构师能够选择的只有C或者A,要么保证数据一致性(保证数据绝对正确),
要么保证可用性(保证是系统服务可用)。
CAP可以理解为一致性,可用性,联通与扩展性
CAP三者只能取其二
最常见的实践是AP + 最终一致性
参考链接