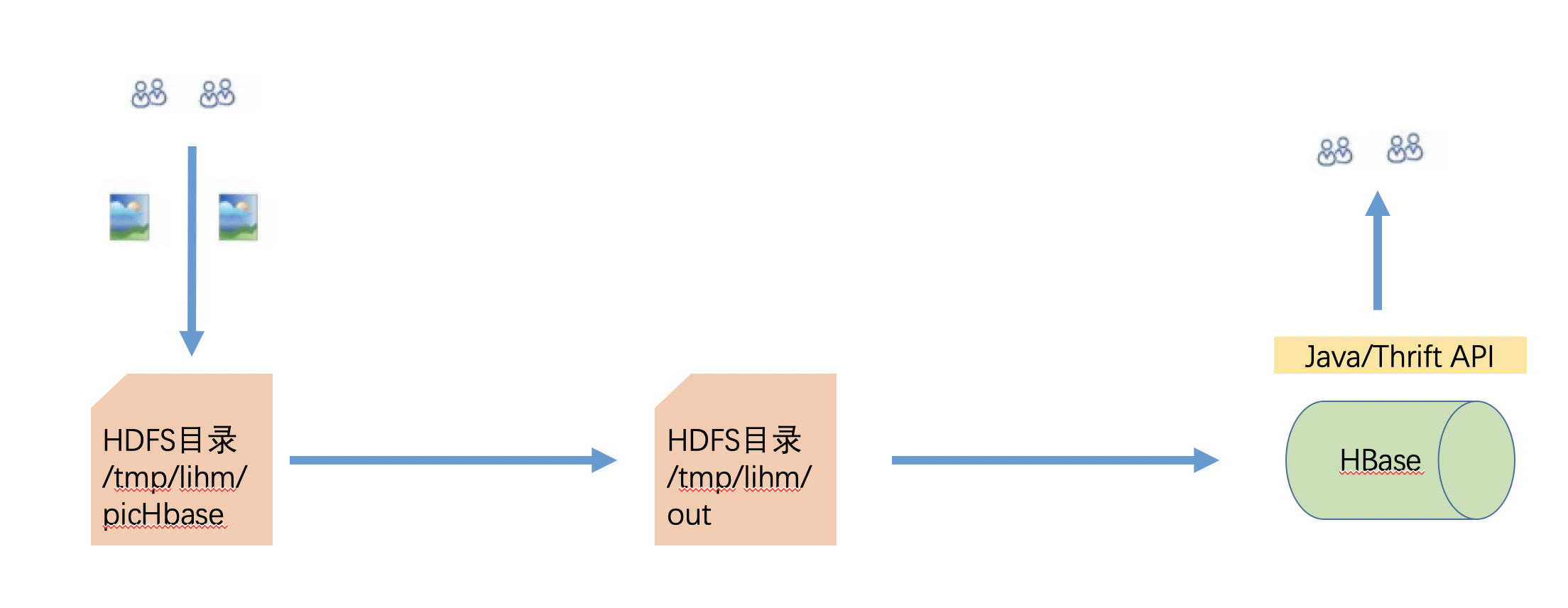
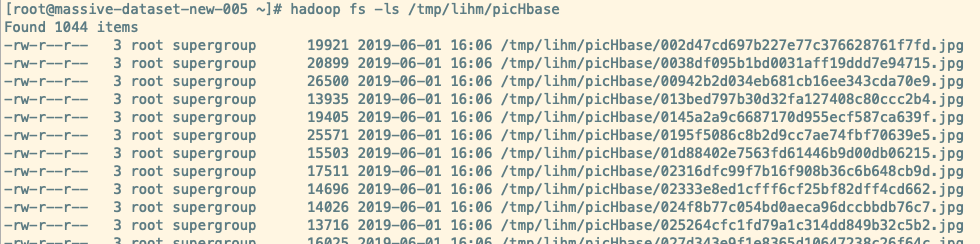
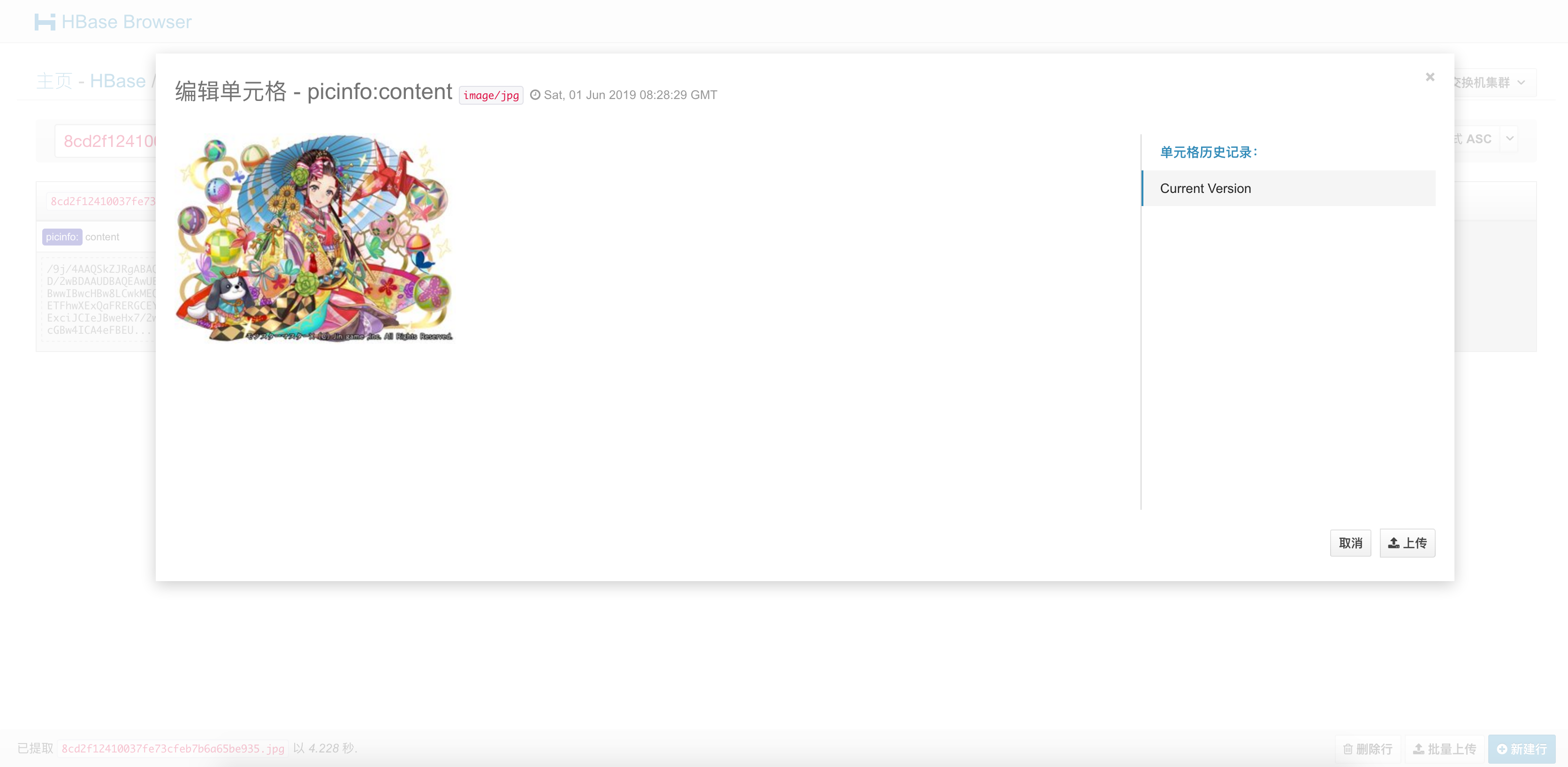
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
| package cn.lihm.hbaseproj;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.commons.io.IOUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;
/**
* @author lihm
* @date 2019-06-01 15:26
* @description TODO
*/
public class SequenceFileTest {
private static String inpath = "/tmp/lihm/picHbase";
private static String outpath = "/tmp/lihm/out";
private static SequenceFile.Writer writer = null;
/**
* 递归文件;并将文件写成SequenceFile文件
*
* @param fileSystem
* @param path
* @throws Exception
*/
public static void listFileAndWriteToSequenceFile(FileSystem fileSystem, String path) throws Exception{
final FileStatus[] listStatuses = fileSystem.listStatus(new Path(path));
for (FileStatus fileStatus : listStatuses) {
if(fileStatus.isFile()){
Text fileText = new Text(fileStatus.getPath().toString());
System.out.println(fileText.toString());
//返回一个SequenceFile.Writer实例 需要数据流和path对象 将数据写入了path对象
FSDataInputStream in = fileSystem.open(new Path(fileText.toString()));
byte[] buffer = IOUtils.toByteArray(in);
in.read(buffer);
BytesWritable value = new BytesWritable(buffer);
//写成SequenceFile文件
writer.append(fileText, value);
}
if(fileStatus.isDirectory()){
listFileAndWriteToSequenceFile(fileSystem,fileStatus.getPath().toString());
}
}
}
/**
* 将二进制流转化后的图片输出到本地
*
* @param bs 二进制图片
* @param picPath 本地路径
*/
public static void picFileOutput(byte[] bs, String picPath) {
// 将输出的二进制流转化后的图片的路径
File file = new File(picPath);
try {
FileOutputStream fos = new FileOutputStream(file);
fos.write(bs);
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 读 hbase 图片
*/
public static void readPicHBase() {
try {
Configuration hbaseConf = HBaseConfiguration.create();
// 公司 HBase 集群
hbaseConf.set("hbase.zookeeper.quorum", "100.73.12.11");
hbaseConf.set("hbase.zookeeper.property.clientPort", "2181");
hbaseConf.set("zookeeper.znode.parent", "/hbase");
Connection connection = ConnectionFactory.createConnection(hbaseConf);
Table table = connection.getTable(TableName.valueOf("tu"));
Get get = new Get("8cd2f12410037fe73cfeb7b6a65be935.jpg".getBytes());
Result rs = table.get(get);
// 保存get result的结果,字节数组形式
byte[] bs = rs.value();
picFileOutput(bs, "/Users/tu/Public/ZaWu/picHBase/8cd2f12410037fe73cfeb7b6a65be935.jpg");
table.close();
connection.close();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 将图片文件转成sequence file,然后保存到HBase
*/
public static void picToHBase() {
try {
Configuration hbaseConf = HBaseConfiguration.create();
// 公司 HBase 集群
hbaseConf.set("hbase.zookeeper.quorum", "100.73.12.11");
hbaseConf.set("hbase.zookeeper.property.clientPort", "2181");
hbaseConf.set("zookeeper.znode.parent", "/hbase");
Connection connection = ConnectionFactory.createConnection(hbaseConf);
Table table = connection.getTable(TableName.valueOf("tu"));
// 设置读取本地磁盘文件
Configuration conf = new Configuration();
conf.addResource(new Path("/Users/tu/Public/ZaWu/conf.cloudera.yarn/core-site.xml"));
conf.addResource(new Path("/Users/tu/Public/ZaWu/conf.cloudera.yarn/yarn-site.xml"));
conf.addResource(new Path("/Users/tu/Public/ZaWu/conf.cloudera.yarn/hdfs-site.xml"));
URI uri = new URI(inpath);
FileSystem fileSystem = FileSystem.get(uri, conf,"hdfs");
// 实例化writer对象
writer = SequenceFile.createWriter(fileSystem, conf, new Path(outpath), Text.class, BytesWritable.class);
// 递归遍历文件夹,并将文件下的文件写入 sequenceFile 文件
listFileAndWriteToSequenceFile(fileSystem, inpath);
// 关闭流
org.apache.hadoop.io.IOUtils.closeStream(writer);
// 读取所有文件
URI seqURI = new URI(outpath);
FileSystem fileSystemSeq = FileSystem.get(seqURI, conf);
SequenceFile.Reader reader = new SequenceFile.Reader(fileSystemSeq, new Path(outpath), conf);
Text key = new Text();
BytesWritable val = new BytesWritable();
// key = (Text) ReflectionUtils.newInstance(reader.getKeyClass(), conf);
// val = (BytesWritable) ReflectionUtils.newInstance(reader.getValueClass(), conf);
int i = 0;
while(reader.next(key, val)){
// 读取图片文件的文件名作为 Rowkey
String temp = key.toString();
temp = temp.substring(temp.lastIndexOf("/") + 1);
// rowKey 设计
String rowKey = temp;
// String rowKey = Integer.valueOf(tmp[0])-1+"_"+Integer.valueOf(tmp[1])/2+"_"+Integer.valueOf(tmp[2])/2;
System.out.println(rowKey);
// 构造 Put
Put put = new Put(Bytes.toBytes(rowKey));
// 指定列簇名称、列修饰符、列值 temp.getBytes()
put.addColumn("picinfo".getBytes(), "content".getBytes() , val.getBytes());
table.put(put);
}
table.close();
connection.close();
org.apache.hadoop.io.IOUtils.closeStream(reader);
} catch (IOException e) {
e.printStackTrace();
} catch (URISyntaxException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
picToHBase();
readPicHBase();
}
}
|