记一次断电造成的 HDFS Corrupt block 影响到 HBase 的事件
前言 测试环境断电,同事把 HBase 启动起来之后遇到 RS 不可用,反馈后让我去排查下原因
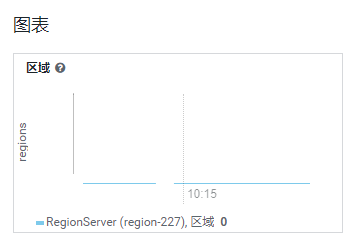
过程 先把停止的 RS 启动,CM未报明显错误,但是观察发现 Region 数为空
既然这样就看日志定位下,先看 RS 日志未有收获,那再看下 HMaster 日志
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 2019-12-23 10:00:25,981 INFO org.apache.hadoop.hbase.master.SplitLogManager: total=1, unassigned=0, tasks={/hbase/splitWAL/WALs%2Fregion-227%2C16020%2C1576486413270-splitting%2Fregion-227%252C16020%252C1576486413270.region-227%252C16020%252C1576486413270.regiongroup-0.1 576833983591=last_update = 1577066410474 last_version = 2 cur_worker_name = region-228,16020,1576840559418 status = in_progress incarnation = 0 resubmits = 0 batch = installed = 1 done = 0 error = 0} 2019-12-23 10:00:26,759 INFO org.apache.hadoop.hbase.coordination.SplitLogManagerCoordination: Task /hbase/splitWAL/WALs%2Fregion-227%2C16020%2C1576486413270-splitting%2Fregion-227%252C16020%252C1576486413270.region-227%252C16020%252C1576486413270.regiongroup-0.15768339 83591 entered state=ERR region-228,16020,1576840559418 2019-12-23 10:00:26,759 WARN org.apache.hadoop.hbase.coordination.SplitLogManagerCoordination: Error splitting /hbase/splitWAL/WALs%2Fregion-227%2C16020%2C1576486413270-splitting%2Fregion-227%252C16020%252C1576486413270.region-227%252C16020%252C1576486413270.regiongroup -0.1576833983591 2019-12-23 10:00:26,759 WARN org.apache.hadoop.hbase.master.SplitLogManager: error while splitting logs in [hdfs://reh/hbase/WALs/region-227,16020,1576486413270-splitting] installed = 1 but only 0 done 2019-12-23 10:00:26,759 WARN org.apache.hadoop.hbase.master.procedure.ServerCrashProcedure: Failed state=SERVER_CRASH_SPLIT_LOGS, retry pid=3, state=RUNNABLE:SERVER_CRASH_SPLIT_LOGS, locked=true; ServerCrashProcedure server=region-227,16020,1576486413270, splitWal=true, meta=false; cycles=11833 java.io.IOException: error or interrupted while splitting logs in [hdfs://reh/hbase/WALs/region-227,16020,1576486413270-splitting] Task = installed = 1 done = 0 error = 1 at org.apache.hadoop.hbase.master.SplitLogManager.splitLogDistributed(SplitLogManager.java:271) at org.apache.hadoop.hbase.master.MasterWalManager.splitLog(MasterWalManager.java:402) at org.apache.hadoop.hbase.master.MasterWalManager.splitLog(MasterWalManager.java:387) at org.apache.hadoop.hbase.master.MasterWalManager.splitLog(MasterWalManager.java:284) at org.apache.hadoop.hbase.master.procedure.ServerCrashProcedure.splitLogs(ServerCrashProcedure.java:253) at org.apache.hadoop.hbase.master.procedure.ServerCrashProcedure.executeFromState(ServerCrashProcedure.java:159) at org.apache.hadoop.hbase.master.procedure.ServerCrashProcedure.executeFromState(ServerCrashProcedure.java:59) at org.apache.hadoop.hbase.procedure2.StateMachineProcedure.execute(StateMachineProcedure.java:189) at org.apache.hadoop.hbase.procedure2.Procedure.doExecute(Procedure.java:965) at org.apache.hadoop.hbase.procedure2.ProcedureExecutor.execProcedure(ProcedureExecutor.java:1742) at org.apache.hadoop.hbase.procedure2.ProcedureExecutor.executeProcedure(ProcedureExecutor.java:1481) at org.apache.hadoop.hbase.procedure2.ProcedureExecutor.access$1200(ProcedureExecutor.java:78) at org.apache.hadoop.hbase.procedure2.ProcedureExecutor$WorkerThread.run(ProcedureExecutor.java:2058)
可以推断是拆分日志时出错或中断导致的问题,该问题影响到了 RS 的 region 恢复
既然这个 log 文件有问题,优先恢复服务,将其 move 到临时文件
1 sudo -u hdfs hadoop fs -mv hdfs://reh/hbase/WALs/region-227,16020,1576486413270-splitting/region-227%2C16020%2C1576486413270.region-227%2C16020%2C1576486413270.regiongroup-0.1576833983591 /user/root
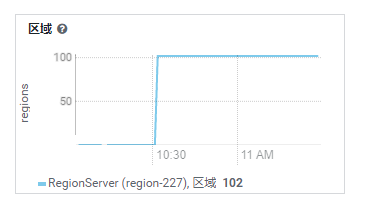
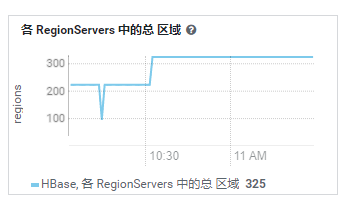
可以看到 Region 有所恢复
RS 分管的 Region 也恢复在线
接着来看看为啥 block 会出问题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 [root@region-227 ~]# sudo -u hdfs hdfs fsck / Connecting to namenode via http://region-227:9870/fsck?ugi=hdfs&path=%2F FSCK started by hdfs (auth:SIMPLE) from /192.168.1.227 for path / at Mon Dec 23 10:58:33 CST 2019 /user/root/region-227%2C16020%2C1576486413270.region-227%2C16020%2C1576486413270.regiongroup-0.1576833983591: CORRUPT blockpool BP-911051597-192.168.1.240-1572922263924 block blk_1073813352 /user/root/region-227%2C16020%2C1576486413270.region-227%2C16020%2C1576486413270.regiongroup-0.1576833983591: CORRUPT 1 blocks of total size 57732 B. Status: CORRUPT Number of data-nodes: 3 Number of racks: 1 Total dirs: 1851 Total symlinks: 0 Replicated Blocks: Total size: 1299310671 B Total files: 1428 (Files currently being written: 6) Total blocks (validated): 1074 (avg. block size 1209786 B) (Total open file blocks (not validated): 4) ******************************** UNDER MIN REPL'D BLOCKS: 1 (0.09310987 %) dfs.namenode.replication.min: 1 CORRUPT FILES: 1 CORRUPT BLOCKS: 1 CORRUPT SIZE: 57732 B ******************************** Minimally replicated blocks: 1073 (99.90689 %) Over-replicated blocks: 0 (0.0 %) Under-replicated blocks: 0 (0.0 %) Mis-replicated blocks: 0 (0.0 %) Default replication factor: 3 Average block replication: 2.9972067 Missing blocks: 0 Corrupt blocks: 1 Missing replicas: 0 (0.0 %) Blocks queued for replication: 0 Erasure Coded Block Groups: Total size: 0 B Total files: 0 Total block groups (validated): 0 Minimally erasure-coded block groups: 0 Over-erasure-coded block groups: 0 Under-erasure-coded block groups: 0 Unsatisfactory placement block groups: 0 Average block group size: 0.0 Missing block groups: 0 Corrupt block groups: 0 Missing internal blocks: 0 Blocks queued for replication: 0 FSCK ended at Mon Dec 23 10:58:33 CST 2019 in 37 milliseconds The filesystem under path '/' is CORRUPT
HDFS 有三副本策略,3份全丢状态就为 corrupt,看来该 block blk_1073813352 无法恢复了
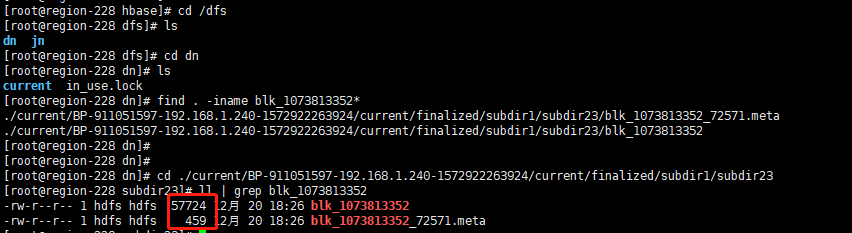
到 DN 磁盘目录下搜索看是否块文件缺失
看来块没有缺失,但是什么问题造成无法恢复呢?
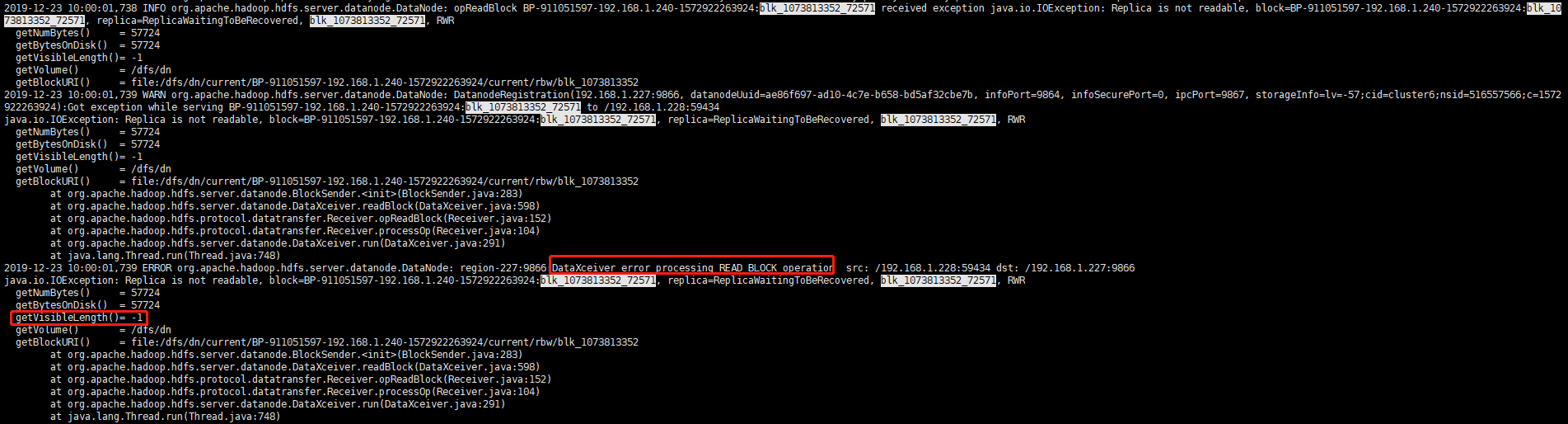
1 2 3 4 5 6 7 8 9 10 11 12 13 2019-12-23 10:00:01,739 ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: region-227:9866:DataXceiver error processing READ_BLOCK operation src: /192.168.1.228:59434 dst: /192.168.1.227:9866 java.io.IOException: Replica is not readable, block=BP-911051597-192.168.1.240-1572922263924:blk_1073813352_72571, replica=ReplicaWaitingToBeRecovered, blk_1073813352_72571, RWR getNumBytes() = 57724 getBytesOnDisk() = 57724 getVisibleLength()= -1 getVolume() = /dfs/dn getBlockURI() = file:/dfs/dn/current/BP-911051597-192.168.1.240-1572922263924/current/rbw/blk_1073813352 at org.apache.hadoop.hdfs.server.datanode.BlockSender.<init>(BlockSender.java:283) at org.apache.hadoop.hdfs.server.datanode.DataXceiver.readBlock(DataXceiver.java:598) at org.apache.hadoop.hdfs.protocol.datatransfer.Receiver.opReadBlock(Receiver.java:152) at org.apache.hadoop.hdfs.protocol.datatransfer.Receiver.processOp(Receiver.java:104) at org.apache.hadoop.hdfs.server.datanode.DataXceiver.run(DataXceiver.java:291) at java.lang.Thread.run(Thread.java:748)
DataXceiver error processing READ_BLOCK operation 说明读出现了问题
根据BlockSender.java:283 源码判断是跟 replicaVisibleLength 有关
replicaVisibleLength 又由 getReplica(block, datanode) 得到的 replica 实例调用getVisibleLength()得到
查阅资料 指导 visible length 表示从数据节点获取数据块副本真实的数据长度
再对比之前报错信息的 getVisibleLength()= -1 可知块数据长度变为-1导致无法读取
接着看 -1 是怎么导致的,到这里就有点全靠猜测了
分析源码找到 FinalizedReplica 99行 ,猜测其跟 NumBytes 有关,但是根据报错信息上显示getNumBytes() = 57724,就有点猜不透了
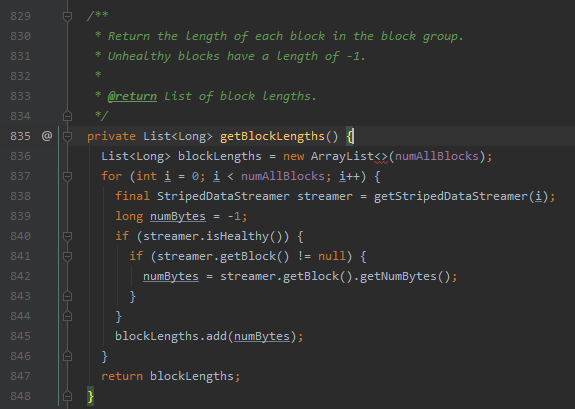
在项目中搜索 -1 看到有个方法可能是关键, DFSStripedOutputStream 835行
1 Return the length of each block in the block group. Unhealthy blocks have a length of -1.
该方法注释说返回 block 的长度,但是对于不健康的块返回 -1
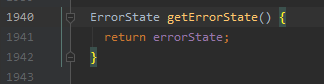
看看判断 block 健康的方法,跳到了DataStreamer 1940行
DataStreamer 是 HDFS 写流程中将 packet 数据包流式传输到管线的类
到了这里我猜估计就是写过程遇到些故障(断电),块损坏,然后 DataStreamer 将其置换为故障,然后 DFSStripedOutputStream 就将其长度变为 -1
这就是我猜想的大概,水平有限,谅解谅解
不往下看了,剩下找不到突破口了
总结 既然块 3 副本都损坏了,那只能删除这个文件了,这个文件是 HBase 未落盘的 Hlog 切分,无法恢复说明就存在
这里还有个问题我未解决,就是为什么切分要恢复的日志未恢复会阻塞 RS 的 Region 上线,带着思考题去研究下这方面的知识。
参考链接